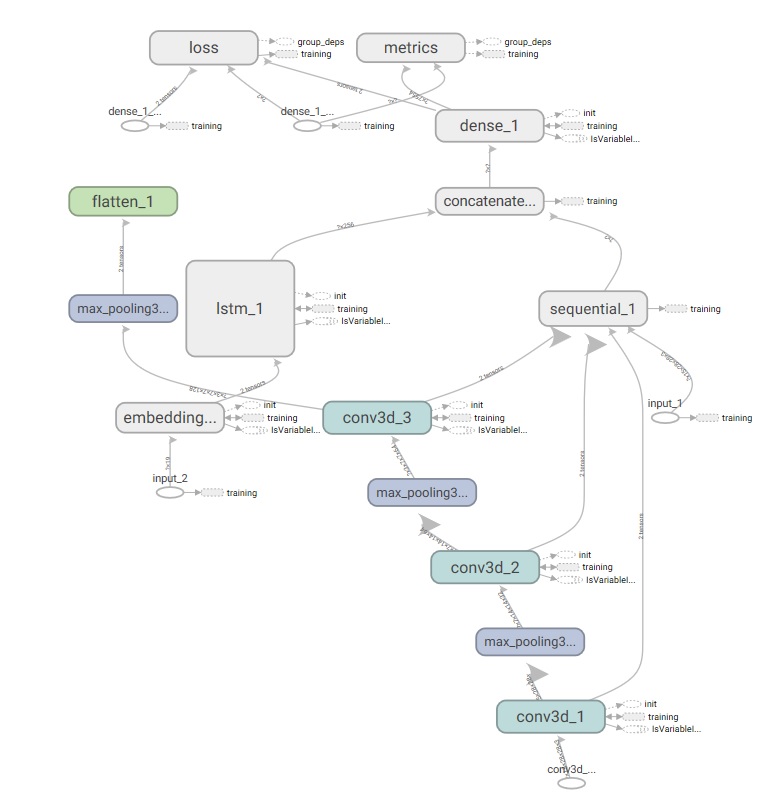
很遗憾没有在规定的时间点(2018-9-25 12:00:00)完成所有的功能并上传数据,只做到写了模型代码并只跑了一轮迭代,现将代码部分贴出。
import keras from keras.layers import Conv2D, MaxPooling2D, Flatten, Conv3D, MaxPooling3D from keras.layers import Input, LSTM, Embedding, Dense, Dropout, Reshape from keras.models import Model, Sequential from keras.preprocessing import image from keras.preprocessing.text import Tokenizer vision_model = Sequential() vision_model.add(Conv3D(32, (3, 3, 3), activation='relu', padding='same', input_shape=(15, 28, 28, 3))) vision_model.add(MaxPooling3D((2, 2, 2))) # vision_model.add(Dropout(0.1)) vision_model.add(Conv3D(64, (3, 3, 3), activation='relu', padding='same')) vision_model.add(MaxPooling3D((2, 2, 2))) # vision_model.add(Dropout(0.1)) vision_model.add(Conv3D(128, (3, 3, 3), activation='relu', padding='same')) vision_model.add(MaxPooling3D((2, 2, 2))) # vision_model.add(Conv3D(256, (3, 3, 3), activation='relu', padding='same')) # vision_model.add(MaxPooling3D((3, 3, 3))) vision_model.add(Flatten()) image_input = Input(shape=(15, 28, 28, 3)) encoded_image = vision_model(image_input) question_input = Input(shape=(19,), dtype='int32') embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=19)(question_input) encoded_question = LSTM(256)(embedded_question) merged = keras.layers.concatenate([encoded_image, encoded_question]) # output = Dense(500, activation='softmax')(merged) output = Dense(7554, activation='softmax')(merged) vqa_model = Model(inputs=[image_input, question_input], outputs=output) adam = keras.optimizers.adam(lr=0.00001, beta_1=0.9, beta_2=0.999, epsilon=1e-08) vqa_model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy']) vqa_model.summary()
import pandas as pd import numpy as np import os import random import collections FRAMES_NUM = 15 max_len = 5 def toarray(str, maxlen): arr = str.split(' ') length = len(arr) if (length < maxlen): for _ in range(maxlen-length): arr.append('$') return arr def tovector(qqarr): global max_len qq_all_words = [] qq_all_words += ['$'] for itv in qqarr: qq_all_words += [word for word in itv] max_len = max(max_len, len(itv)) print("maxlen:",max_len) qqcounter = collections.Counter(qq_all_words) print("qqcounter:",len(qqcounter)) qq_counter_pairs = sorted(qqcounter.items(), key = lambda x : -x[1]) qqwords,_ = zip(*qq_counter_pairs) qq_word_num_map = dict(zip(qqwords, range(len(qqwords)))) qq_to_num = lambda word:qq_word_num_map.get(word, len(qqwords)) qq_vector = [list(map(qq_to_num, word)) for word in qqarr] return qq_vector, qq_word_num_map, qq_to_num def tolabel(labels): all_words = [] for itv in labels: all_words.append([itv]) counter = collections.Counter(labels) print("labelcounter:",len(counter)) counter_pairs = sorted(counter.items(), key = lambda x : -x[1]) words, _ = zip(*counter_pairs) print(words) print("wordslen:",len(words)) word_num_map = dict(zip(words, range(len(words)))) to_num = lambda word: word_num_map.get(word, len(words)) vector = [list(map(to_num, word)) for word in all_words] return vector, word_num_map, to_num def randomsample(list, count, dicdir): if len(list) > count: sampleintlist = random.sample(range(len(list)), count) else: sampleintlist = [] for i in range(count): sampleintlist.append(i % len(list)) sampleintlist.sort() samplelist = [] for i in sampleintlist: samplelist.append(os.path.join(dicdir, str(i) + ".jpg")) return samplelist def getvideo(key): dicdir = os.path.join(r"D:\ai\AIE04\tianchi\videoanswer\image", key) list = os.listdir(dicdir) samplelist = randomsample(list, FRAMES_NUM, dicdir) return samplelist path = r"D:\ai\AIE04\VQADatasetA_20180815" data_train = pd.read_csv(os.path.join(path, 'train.txt'), header=None) length= len(data_train)*FRAMES_NUM frames = [] qqarr = [] aaarr = [] qq = [] aa = [] labels = [] paths = [] for i in range(len(data_train)): label, q1, a11, a12, a13, q2, a21, a22, a23, q3, a31, a32, a33, q4, a41, a42, a43, q5, a51, a52, a53 = data_train.loc[i] print(label) [paths.append(label) for j in range(15)] [qqarr.append(toarray(str(q1), 19)) for j in range(3)] [qqarr.append(toarray(str(q2), 19)) for j in range(3)] [qqarr.append(toarray(str(q3), 19)) for j in range(3)] [qqarr.append(toarray(str(q4), 19)) for j in range(3)] [qqarr.append(toarray(str(q5), 19)) for j in range(3)] labels.append(a11) labels.append(a12) labels.append(a13) labels.append(a21) labels.append(a22) labels.append(a23) labels.append(a31) labels.append(a32) labels.append(a33) labels.append(a41) labels.append(a42) labels.append(a43) labels.append(a51) labels.append(a52) labels.append(a53) qq_vector, qq_word_num_map, qq_to_num = tovector(qqarr) # print(labels) vector, word_num_map, to_num = tolabel(labels) # print(vector) # print(word_num_map) # print(to_num)
from nltk.probability import FreqDist from collections import Counter import train_data from keras.preprocessing.text import Tokenizer import numpy as np from PIL import Image from keras.utils import to_categorical import math import videomodel from keras.callbacks import LearningRateScheduler, TensorBoard, ModelCheckpoint import keras.backend as K import keras import cv2 def scheduler(epoch): if epoch % 10 == 0 and epoch != 0: lr = K.get_value(videomodel.vqa_model.optimizer.lr) K.set_value(videomodel.vqa_model.optimizer.lr, lr * 0.9) print("lr changed to {}".format(lr * 0.9)) return K.get_value(videomodel.vqa_model.optimizer.lr) def get_trainDataset(paths, question, answer, img_size): num_samples = len(paths) X = np.zeros((num_samples, 15, img_size, img_size, 3)) Q = np.array(question) for i in range(num_samples): # image_paths = frames[i] image_paths = train_data.getvideo(paths[i]) # print("len:",len(image_paths)) for kk in range(len(image_paths)): path = image_paths[kk] # print(path) img = Image.open(path) img = img.resize((img_size, img_size)) # print(img) X[i, kk, :, :, :] = np.array(img) img.close() Y = to_categorical(np.array(answer), 7554) # print(X.shape) # print(Q) # print(Y) return [X, Q], Y def generate_for_train(paths, question, answer, img_size, batch_size): while True: # train_zip = list(zip(frames, question, answer)) # np.random.shuffle(train_zip) # print(train_zip) # frames, question, answer = zip(*train_zip) k = len(paths) epochs = math.ceil(k/batch_size) for i in range(epochs): s = i * batch_size e = s + batch_size if (e > k): e = k x, y = get_trainDataset(paths[s:e], question[s:e], answer[s:e], img_size) yield (x, y) split = len(train_data.paths) - 6000 qsplit = split*15 print("split:", split) batch_size = 10 reduce_lr = LearningRateScheduler(scheduler) tensorboard = TensorBoard(log_dir='log', write_graph=True) checkpoint = ModelCheckpoint("max.h5", monitor="val_acc", verbose=1, save_best_only="True", mode="auto") h = videomodel.vqa_model.fit_generator(generate_for_train(train_data.paths[:split], train_data.qq_vector[:split], train_data.vector[:split], 28, batch_size), steps_per_epoch=math.ceil(len(train_data.paths[0:split]) / batch_size), validation_data=generate_for_train(train_data.paths[split:], train_data.qq_vector[split:], train_data.vector[split:], 28, batch_size), validation_steps=math.ceil(len(train_data.paths[split:]) / batch_size), verbose=1, epochs=100, callbacks=[tensorboard, checkpoint])
计算图如下: