目录
摘 要 I
Abstract II
第1章 绪论 1
1.1 课题研究的背景以及意义 1
1.2 视频问答的国内外研究现状 3
1.3 课题的来源及研究内容 5
1.4 论文的组织结构与内容安排 6
第2章 深度学习基础知识 7
2.1 有监督学习 7
2.1.1 目标函数 7
2.1.2 优化算法 7
2.1.2.1 随机梯度下降(SGD) 8
2.1.2.2 Adagrad算法 8
2.1.2.3 RMSprop算法 9
2.1.2.4 Adam算法 9
2.2 卷积神经网络 CNN 10
2.2.1 卷积层 10
2.2.2 池化层 11
2.2.3 Dropout 11
2.3 递归神经网络 RNN 12
2.3.1 “Vanilla” RNN 12
2.3.2 LSTM 12
2.4 注意力机制 13
2.5 本章小结 13
第3章 视频问答相关技术概述 14
3.1 图像与视频 14
3.1.1 基本术语 14
3.1.2 视频消除冗余 15
3.1.2.1 视觉特性 15
3.1.2.2 时间上的重复 16
3.1.2.3 图像内的重复 16
3.2 视觉问答 17
3.2.1 图像问答 17
3.2.2 文本问答 19
3.2.3 视频问答 19
3.3 公开数据集 20
3.3.1 视频问答公开数据集 20
3.3.2 ZJB问答数据集 21
3.4 本章小结 22
第4章 先验MASK的多注意力机制的视频问答方案 23
4.1 对视频和问题进行处理(编码) 23
4.1 视频编码表示 23
4.1.1.1 关键帧 24
4.1.1.2 ResNet-101和Faster-RCNN 24
4.1.1.3 自底向上注意力 25
4.1.2 问题编码表示 26
4.1.2.1 对问题进行NLTK处理 26
4.1.2.2 对问题进行LSTM编码表示 26
4.2 评价标准 28
4.3 先验MASK的多注意力机制模型 28
4.3.1 视频与问题文本注意力temporal-attention 29
4.3.2 视频与视频对象标签注意力 attr-block-attention 30
4.3.3 问题与对象标签注意力 time-spatial-attention 30
4.3.4 先验MASK 31
4.3.5 答案生成 31
4.3.6 Loss函数选择 31
4.4 实验评估 32
4.4.1 3.6.1 模型参数以及环境设置 33
4.4.2 模型对比实验分析 33
4.4.3 实例展示 38
4.5 本章小结 39
第5章 先验MASK的图注意力机制的视频问答方案 40
5.1 相关工作 40
5.2 图注意力网络 42
5.2.1 节点选择 42
5.2.2 图构建 43
5.2.3 图嵌入 44
5.2.4 先验MASK 45
5.3 实验 45
5.4 本章小结 46
第6章 总结与展望 47
6.1 全文总结 47
6.2 未来工作与展望 47
致谢 48
参考文献 49
1.3课题的来源及研究内容
2018年,作者参加了阿里巴巴下面的之江实验室举办的全球人工智能大赛[ https://tianchi.aliyun.com/competition/entrance/231676/introduction],受该大赛的吸引,作者对该课题非常感兴趣,并进行研究,最终拿到了该大赛视频问答组的冠军,并作为作者的攻读学术型硕士研究课题。比赛结束后,数据集仍然可以继续下载,供学术研究。
在现有的视频问答任务方法中,要么只是将视频的帧进行全部提取出来进行训练,这对机器的要求非常高,因为一个短视频帧数是非常多的,因此将一个视频中所有的帧全部提取进行深度学习训练是不现实的;要么将视频使用3D卷积进行训练,这对机器的要求也非常高,尤其是显存,3维卷积的参数量比2维卷积多一个数量级,因此迭代速度慢且精度不高。
针对这种情况,本文提出了两个模型,分别为先验MASK的多注意力机制网络模型以及先验MASK的图注意力机制的网络模型。在先验MASK的注意力机制的模型中,首先采用FFmpeg[29]进行视频的关键帧的提取,然后采用bottom-up-attention[30]进行关键帧特征的提取,这一步的提取仅仅能够得到帧的特征,更能够得到帧中所有对象的特征以及标签,对于文本的处理本文采用了word2vec进行词嵌入,然后采用双向LSTM[31]进行问题文本的特征表达,当获得视频以及问题文本的特征以后,本文提出了3中注意力机制以及先验MASK进行不同角度的加权,使得神经网络从各种方向获得视频与文本的信息。在先验MASK的图注意力机制的模型中,采用Faster R-CNN抽取视频的物体标签并建立图数据结构,通过图神经网络[32]的嵌入表达,最后使用先验MASK,从而得到模型的结果。
本文对视频问答任务的工作有以下几点
•提出了使用更加先进的buttom-up-attention来进行视频特征的提取。
•提出了先验MASK进行问题答案的预测。
•本文将提出的两种模型在ZJB数据集中与现有的方法进行对比,实验表明,本文的两种方法均能够取得很好的效果。
•首次采用图注意力机制应用在视频问答任务上。
1.4论文的组织结构与内容安排
本文主要研究先验注意力机制的视频问答方案,本文的组织结构如图1-5所示:第一章主要阐述了课题研究的目的,分析了现有各种方法的不足,引入先验MASK模型。第二章主要简要介绍了视频问答所需要的深度学习基础。第三章主要描述了图像、图像问答和视频问答相关领域的知识。第四章主要介绍了先验MASK的多注意力机制的视频问答方案。第五章主要介绍了先验MASK的图注意力机制的视频问答方案。第六章对之前的两个工作进行了总结和概括,并对视频问答领域未来可能的发展方向进一步展望。本论文的整体流程图如下:
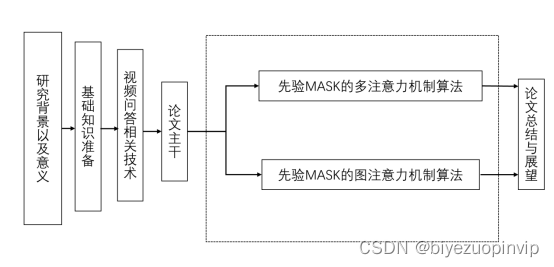
图1-5 论文总体框架
import os
# os.environ['CUDA_VISIBLE_DEVICES'] = '2'
import tensorflow as tf
import keras.backend.tensorflow_backend as KTF
tf_cfg = tf.ConfigProto(allow_soft_placement=True)
tf_cfg.gpu_options.allow_growth=True
session = tf.Session(config=tf_cfg)
KTF.set_session(session)
from utils import *
from model import *
from keras import backend as K
from sklearn.cross_validation import StratifiedKFold
import warnings
warnings.filterwarnings('ignore')
from config import *
def main(cfg,output_name='submit3.txt'):
def select_bestepoch(result):
submit = 0
for answers in result:
ans_ = sorted(answers, key=lambda x: x[1])
pred = (ans_[-3][0] + ans_[-2][0] + ans_[-1][0]) / 3
submit += pred
submit /= len(result)
return submit
bs = cfg['bs']
patience = cfg['patience']
cfg['frame_size'] = 2048
tr, te, y, embed_matrix, cfg = load_data('glove42',cfg)
num_fold = 5
folds = StratifiedKFold(select_label(y,True), num_fold, shuffle=True, random_state=cfg['seed'])
te_g = DataLoader(False, te,None,cfg)
print(cfg)
for n_fold, (tr_idx, val_idx) in enumerate(folds):
if n_fold not in cfg['fold']:
continue
print('fold :', n_fold)
tr_x = [tr[i] for i in tr_idx]
tr_y = y[tr_idx]
tr_g = DataLoader(True, tr_x, tr_y, cfg)
val_x = [tr[i] for i in val_idx]
val_y = y[val_idx]
val_g = DataLoader(False, val_x, val_y,cfg)
model = cfg['model'](embed_matrix)
best_iter = 0
best_score = 0
te_pred = []
for i in range(1,1000):
print(i)
if cfg['use_rc'] and i < cfg['rc_max_iter']:
if i % 2 == 1:
g = tr_g.random_concat()
else:
g = tr_g.get_data()
steps = (tr_g.num_samples + bs - 1) // bs
else:
g = tr_g.get_data()
steps = (tr_g.num_samples + bs - 1) // bs
model.fit_generator(
g,
steps_per_epoch=steps,
epochs=1,
verbose=0,
workers=32,
)
print(model.evaluate_generator(val_g.get_data(),
steps=(val_g.num_samples + bs - 1) // bs,workers=32))
val_pred = model.predict_generator(val_g.get_data(),
steps=(val_g.num_samples + bs - 1) // bs, workers=32)
score = val_g.evaluate(val_pred)
if score > best_score:
best_iter = i
best_score = score
model.save_weights('../model/'+ 'vqa' + str(n_fold) + '.h5')
if i > 15:
pred = te_g.test_aug(model)
te_pred.append((pred, score))
if i > 20 and i - best_iter > patience:
break
K.clear_session()
tf.reset_default_graph()
submit_fold = select_bestepoch([te_pred])
np.save(output_dir+output_name+'fold'+str(n_fold),submit_fold)
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--fold", type=int, required=True)
parser.add_argument("--name", type=str, required=True)
args = parser.parse_args()
cfg['fold'] = [args.fold]
cfg['atten_k'] = 0
cfg['bs'] = 8
cfg['seed'] = 47
cfg['num_frame'] = 16
cfg['patience'] = 5
cfg['dim_q'] = 256
cfg['dim_v'] = 384
cfg['dim_a'] = 256
cfg['dim_attr'] = 300
cfg['attr_num'] = 96
cfg['use_rc'] = True
cfg['rc_max_iter'] = 12
cfg['alpha'] = 0.65
cfg['attention_avepool'] = True
cfg['attention'] = 'coa'
cfg['lr'] = 0.0002
cfg['loss'] = focal_loss_fixed
cfg['model'] = attention_model
main(cfg, args.name)



















