基于在SVM中定义新的特征变量进行核函数讲解
- 使用核函数的目的:用以构造复杂的非线性分类器
Andrew NG的机器学习视频有提供比较易懂的讲解,上图:

在构建高阶特征的时候,我们并不知道这些特征是不是我们需要的。且高阶特征变量计算量巨大,因此构造新特征 f 辅助计算。
这里把高斯函数作为相似度函数来替代高阶特征变量


- 当x靠近标记的时候,f1的值逼近1
- 当x远离标记的时候,f1的值逼近0
- 所以这些新特征变量的作用就是度量 x 到标记 l 的相似度
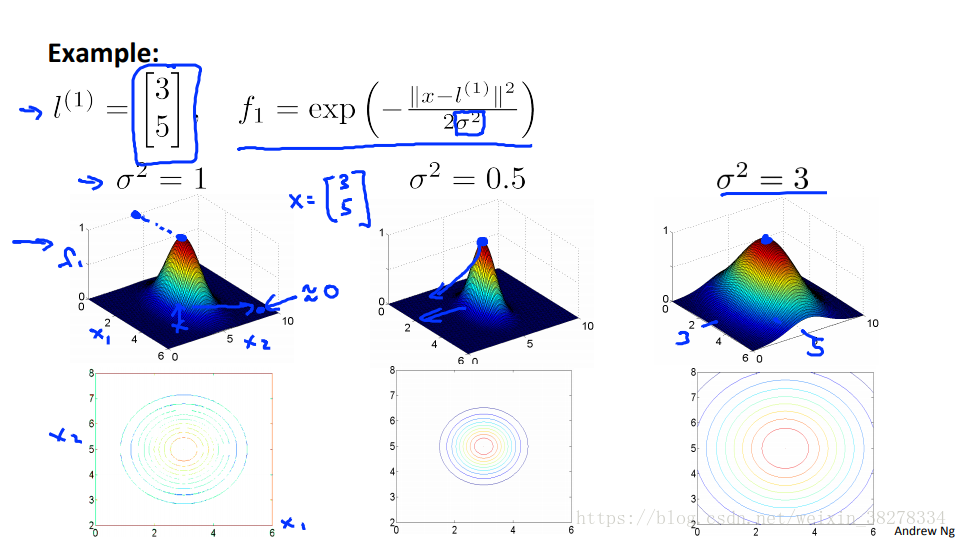
- 当x 与标记点重合的时候,f1值为1.
- 当 的值减小时,x从与 l 标记值重合的地方开始移动时,降到0的速度会加快。
- 当 的值增大时,x从与 l 标记值重合的地方开始移动时,降到0的速度会减慢。

- 将根据训练样本x 计算的 f 特征变量值代入预测函数,获取最后的分类结果。
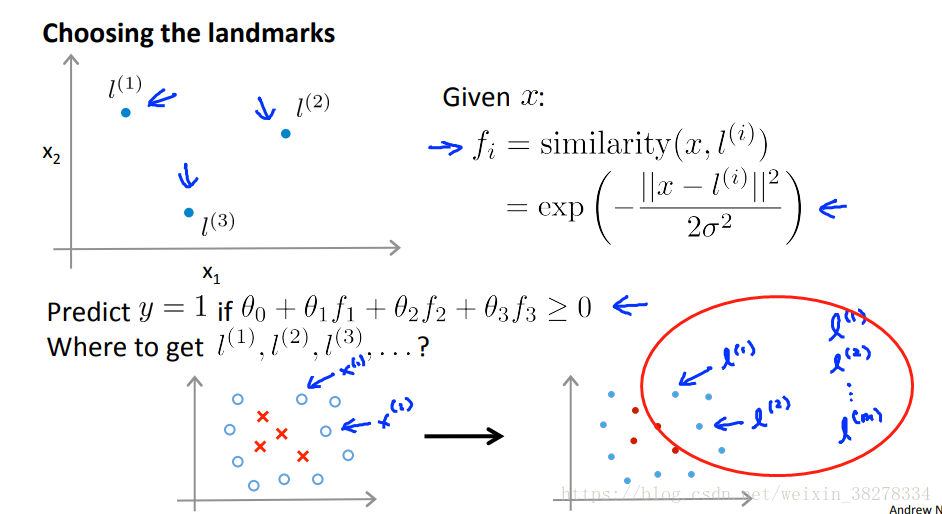

- 将训练样本作为标记点,样本x和每一个标记点计算相似度获取特征变量矩阵。

- 一般的SVM正则化项为 ,核函数中经常使用另一种略有区别的距离度量方法,即 M (M为某个矩阵),不直接用 的模的平方进行最小化,这是参数向量 的变尺度形式,这种变化和核函数相关,此细节可以使得SVM更有效率的运行。这么做可以使SVM适应超大的训练集,提高计算效率。

- 关于选择SVM中的参数问题 ——即偏差方差的关系
可以直观理解为:C值和 成反比关系,和 成正比关系。在判断C和 的变化趋势时,可依据 的变化做参考。

- 使用高斯核函数时,一定记得数据归一化

多分类问题
可以调包解决,也可使用one-vs-all,训练K次SVM
关于Logistic regression 和SVM使用选择问题如上图,根据特征和样本大小进行选择。
- Logistic regression和不带核函数的SVM函数是非常相似的算法,做相似的事情,表现相似。
- SVM的威力随着使用不同的核函数学习复杂的非线性函数发挥出来。
- 神经网络适用于上图所有维度的数据,但是如果有不选择神经网络的原因可能因为网络训练非常慢,而一个好的SVM包训练非常快。
- SVM的优化问题是凸优化问题,所有好的SVM包总是会找到全局最优或者接近全局最优的值,而不需要担心局部最优问题(神经网络需要考虑)。

Andrew NG课后习题【不确定题】题解笔记
题目:
Suppose you have a dataset with n = 10 features and m = 5000 examples.
After training your logistic regression classifier with gradient descent, you find that it has underfit the training set and does not achieve the desired performance on the training or cross validation sets.
Which of the following might be promising steps to take? Check all that apply.
A.Try using a neural network with a large number of hidden units.
A题解:A neural network with many hidden units is a more complex (higher variance) model than logistic regression, so it is less likely to underfit the data.
B.Reduce the number of examples in the training set.
C.Use a different optimization method since using gradient descent to train logistic regression might result in a local minimum.
C题解:The logistic regression cost function is convex, so gradient descent will always find the global minimum.
D.Create / add new polynomial features.
D题解:By using a Gaussian kernel, your model will have greater complexity and can avoid underfitting the data.
答案:AD