HIVE-分区入门踩坑
hive 分区
概念在先:
1: 静态分区是把一个目录下面的很多【文件】分类存放起来 , 只能细化到【文件】,但是细化不到内容,一次操作只能指定一个类(区);
2: 动态分区一次操作可以根据字段具体内容分多类(区);
3: 分区目的是单表查询的时候缩小查询范围,提高单表的查询效率;
4: 静态分区因在命令行指定了分区,底层不执行mr程序(相对死板);动态分区执行mr程序,提取相应字段(相对智能一点)。
Demo步骤:
1.创建一个学生分区表
95001,李勇,男,20,CS
95002,刘晨,女,19,IS
95003,王敏,女,22,MA
95004,张立,男,19,IS
95005,刘刚,男,18,MA
95006,孙庆,男,23,CS
--分区表创建
create table t_students(id int,name string,sex string)
partitioned by (age int,class string)
row format delimited fields terminated by ',' ;
创建后看一下成功没有
hive> set hive.cli.print.header=true;
hive> select * from t_students;
OK
t_students.id t_students.name t_students.sex t_students.age t_students.class
2.添加内容
(1)load
--静态分区
load data local inpath '/root/logs/students.txt' into
table t_students partition (age=19,class='MA');
(2)insert
Hive 中 insert 主要是结合 select 查询语句使用.
--动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table t_students partition (age,class)
select * from t_student;
执行之后查看元数据SDS表 , 可以看到所有映射信息
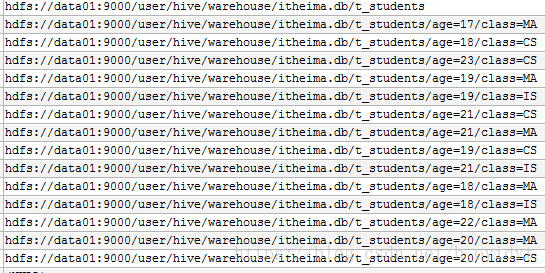
--使用同样的数据,再次追加insert一次数据
hive> insert into table t_students partition (age,class) select * from t_student;
再次追加一次数据后,元数据SDS表信息不变,每条分区路径下的文件变为两份

hive 分桶
分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
注意:
第一,分桶之前要执行命令hive.enforce.bucketiong=true;
第二,要使用关键字clustered by 指定分区依据的列名,还要指定分为多少桶,这里指定分为3桶。
第三,与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实的列而不是伪列。所以在指定分区依据的列的时候要指定列的类型,因为在数据表文件中不存在这个列,相当于新建一个列。而分桶依据的是表中已经存在的列,这个列的数据类型显然是已知的,所以不需要指定列的类型。
分3个桶就是将数据表由一个文件存储分为3个文件存储