文章目录
1.概念
hive的分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
2.创建分区表
create table dept_partition(
id int, name string
)
partitioned by (month string)
row format delimited fields terminated by '\t'
stored as textfile;

3.加载数据到分区表
在/home/hive下有一个srcdata.txt:
 加载数据:
加载数据:
load data local inpath '/home/hive/srcdata.txt' into table default.dept_partition partition(month='202001');


4.分区数据查询
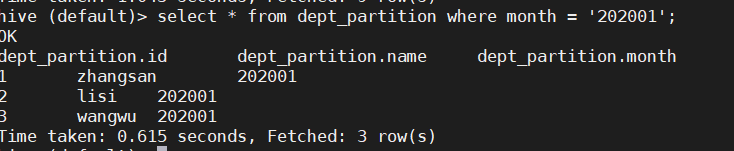
- 单个分区查询:
select * from dept_partition where month = '202001';
- 多分区联合查询:
select * from dept_partition where month = '202001'
union
select * from dept_partition where month = '202002';

5.添加分区
- 创建单个分区:
alter table dept_partition add partition(month='202008');
- 创建多个分区:
alter table dept_partition add partition(month='202005') partition(month='202006');

6.删除分区
- 删除单个分区
alter table dept_partition drop partition (month='202008');

- 删除多个分区
alter table dept_partition drop partition(month='202005'),partition(month='202006');
 注意:
注意:
删除分区的时候多个分区需要加上逗号,添加多个分区的时候则不需要。
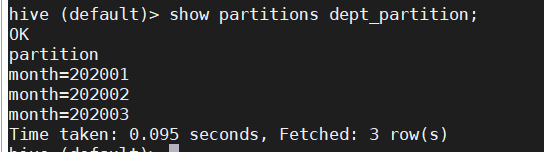
7.查看分区表有多少个分区
show partitions dept_partition;
8.查看分区表结构
show partitions dept_partition;

8.二级分区表
- 创建二级分区表:
create table dept_partition2(
id int, name string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t'
stored as textfile;

- 加载数据到分区表
load data local inpath '/home/hive/srcdata.txt' into table dept_partition2 partition(month='202011', day='01');


- 查询分区数据
select * from dept_partition2 where month='202011' and day='01';

9.把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
- 上传数据后修复
先创建分区表:
create table dept_partition2(
id int, name string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t'
stored as textfile;
添加分区:
alter table dept_partition2 add partition(month='202001',day='01');
上传数据:
hadoop fs -put srcdata.txt /user/hive/warehouse/dept_partition2/month=202001/day=01
直接查询:

2. 上传数据后添加分区
也可以按照步骤一里面,先在指定位置创建文件夹,在上传数据,最后添加分区也可以;
dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=202002/day=02;
hadoop fs -put srcdata.txt /user/hive/warehouse/dept_partition2/month=202002/day=02/
alter table dept_partition2 add partition(month='202002',day='02');

3. 创建文件夹后load数据到分区
alter table dept_partition2 add partition(month='202003',day='03');
load data local inpath '/home/hive/srcdata.txt' into table dept_partition2 partition(month='202003',day='03');

