参考:数据结构(严蔚敏)
选择类排序有两个经典算法,一个是之前总结过的直接选择排序,另一个则是今天要讲的堆排序
0.什么是堆
对于Java中的一个数组Array,如果对于其中所有的元素其下标index满足:Array[index]>=Array[2index+1] && Array[index]>=Array[2index+2](或者Array[index]<=Array[2index+1] && Array[index]<=Array[2index+2])
满足Array[index]>=Array[2index+1] && Array[index]>=Array[2index+2]的数组称为大顶堆,反之则称为小顶堆。
这样讲可能比较抽象,用树的结构可以有助于理解。对于任意数组,都可以模拟成树形结构:
比如数组{12,36,27,65,40,34,98,81,73,55,49}
可以写成如下形式

使用堆的定义,可以发现该数组满足堆的条件。
我们可以发现堆的定义其实就是对于所有元素,满足:根节点比孩子节点大,叶子节点默认满足条件(此时构成大顶堆)
1.堆排序原理
以数组5,6,4,7,2,1,9,10,3为例,堆排序过程如下:

简单描述就是
1.将数组堆化
2.while(无序size>0){
交换下标为0和当前最后一个元素
无序部分总数-1(有序size+1)
对无序部分重新堆化
}
如何将数组堆化?(对一组元素堆化)
首先,叶子节点可以算作已经满足堆的定义,那么可以从第一个非叶子节点(arr.length-1)/2向前调整,使每个元素满足堆的定义。比如数组1,7,8,2的堆化过程如下:
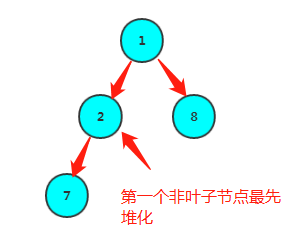
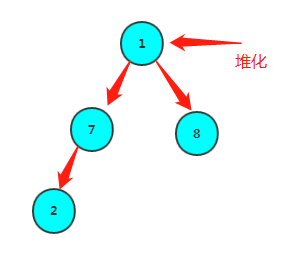
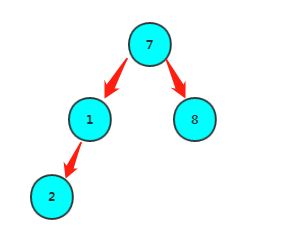
1继续堆化
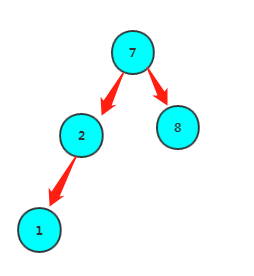
对一个元素的堆化过程为:
将它跟max(左孩子,右孩子)比较,如果比子节点较大者大,那么已经满足堆的定义,循环结束,否则,跟较大者交换,继续跟max(左孩子,右孩子)比……直到没有孩子节点终止。
如何对无序部分重新堆化?(对一个元素堆化)
已经堆化过的数据,交换下标为0和当前最后一个元素,无序部分只有第零个元素不一定满足堆的定义,问题演化成:
如何重新构建堆的问题。这个其实就是上面的一组元素堆化的拆分,现在只是一个元素。
因此,堆排序的基本操作是对一个元素进行堆化。
2.堆排序Java实现
public class heapSort {
public static void main(String[] args) {
long arr[] = {5,6,4,7,2,1,9,10,3};// 数组index从0开始
// (arr.length-1)/2表示第一个非叶子节点
for (int i = (arr.length - 1) / 2; i >= 0; i--) {// 构建大顶堆
fixHeapTop(arr, i, arr.length - 1);
}
long tem = 0;
for (int index = arr.length - 1; index > 0;) {//每趟堆排序,无序数-1,有序数+1
//swap
tem = arr[index];
arr[index] = arr[0];
arr[0] = tem;
fixHeapTop(arr, 0, --index);
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+",");
}
}
// 检查index为startIndex的数据与孩子是否满足大顶堆,如果不满足,调整
public static void fixHeapTop(long a[], int startIndex, int endIndex) {
long temp;
int leftChildIndex;
//startIndex * 2 + 1表示下标为startIndex的左孩子节点index
for (leftChildIndex = startIndex * 2 + 1; leftChildIndex <= endIndex; leftChildIndex = leftChildIndex * 2 + 1) {
if (leftChildIndex < endIndex && a[leftChildIndex] < a[leftChildIndex + 1]) {
leftChildIndex++;//此时代表右孩子index
}
// compare
if (a[startIndex] > a[leftChildIndex]) {//如果当前比较值比孩子中较大的还大,满足大顶堆,循环结束
break;
}
//swap
temp = a[startIndex];
a[startIndex] = a[leftChildIndex];
a[leftChildIndex] = temp;
startIndex = leftChildIndex;
}
}
}3.堆排序时间复杂度
堆排序主要分为两部分(其他部分省略,如交换,size-1等等)
1.对数组进行堆化
对长度为n的数组进行堆化从(arr.length - 1) / 2遍历到0,经历了(n-1)/2次
而对一个元素进行堆化的时间复杂度和深度有关,比较次数最多为2(h-1),根据之前二叉树的学习可知深度k=
,因此对数组进行堆化的时间复杂度<(n-1)
(因为比较次数最多为2(h-1)中,不是每次n都是最大值,n会递减直到1)
2.对无序部分堆化
进行了n-1趟堆排序,每趟堆排序又是对一个元素进行堆化,因此,时间复杂度和上面类似,都是
级别,两个操作,时间复杂度相加,最终堆排序时间复杂度