此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
根据所给任务要求进行需求分析:本次作业要求统计英文书籍中出现的英文单词数量,在计算出每个单词的出现频率同时排序出出现次数最高的10个单词(少于10个则记录全部单词)。并能够实现文本的批量处理,利用linux 重定向方法改变程序的执行方法。
代码地址:https://git.coding.net/doubanjiang73/coding.git
代码片段一:
该片段首先使用getText函数获取文本并打开文本。将英文文本中的大写字母变成小写字母,并将特殊符号转化成空格利于统计英文字数的统计。
def getText(name): #去掉特殊符号 txt = open(name, "r",encoding = 'utf-8').read() txt = txt.lower() for ch in '\'!"#$%&()*+,./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, " ") #将文本中特殊字符替换为空格
代码片段二:
该片段的含义是遍历所有英文单词。在字典中查询每一个单词,如果在没查到此单词word下标的数值加一。如果get函数查询到此单词,就在word的值上加1,并同时更新字典,并利用sort函数进行排序。
def p_count(words,nn=5): counts = {} for word in txt: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True)
代码片段三:
os.path是python中常用的模块,用dirname函数来实现删除文件名,返回目录所在的文件。所以这段代码的主要就是用于添加绝对路径,将绝对路径用split函数分开并存放于test中。
if com_list[1] == '-s': # wf -s test.txt com_list[2] = os.path.dirname(os.path.realpath(__file__)) + '\\' + com_list[2] # 加绝对路径 txt = getText(com_list[2]).split() if len(txt) > 15: print('total', len(txt), '\n') else: print('total', len(set(txt)), '\n') p_count(txt, min(10, len(set(txt))))
功能一测试:
完成文件读取,输出测试的英文小文本(用控制台输出)。

功能二测试:
支持命令行输入英文作品的文件名(以the_dead_return.txt为例)。
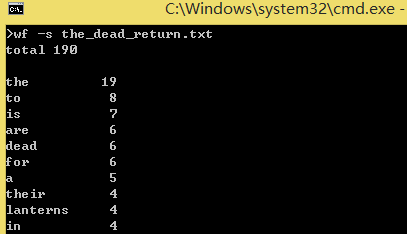
功能三测试:
在功能三中要求对所有输入的英文文本进行批量处理并统计字数,输出每个文本单词出现频率最高的10个单词。在测试中,我发现目前我所编写的代码并不能实现这该功能,每次只能单独处理一个文本。

功能四测试:
功能四要求利用linux 重定向方法,经过查询我对于这种方法的理解是利用这种方法是通过修改系统原本默认的某些参数来改变系统默认的执行方法,但具体操作方法仍不理解。
以下是将py格式文件转换为exe格式文件的过程,其前提为已安装pyinstaller。



psp阶段表
| 类别 |
预计时间(分钟) |
实际时间(分钟) |
时间差(min) |
| 功能一 |
120 |
192 |
+72 |
| 功能二 |
120 |
273 |
+153 |
| 功能三 |
120 |
|
|
| 功能四 |
120 |
|
|
| 测试 |
10 |
52 |
+42 |
注:由于功能三、功能四未能实现,无法记录实际时间。
原因分析:
在设计程序的过程中发现对python掌握不够娴熟,对于函数嵌套、文件读取等内容都有些生疏。因此,重新进行学习耽误了许多时间。而且在实现作业功能的过程中,出现了由于读不懂题目而导致的所编写的程序并非作业要求的情况,导致实际编写时间增长许多。在代码的实现过程也出现了因格式不规范、标点错误等原因导致的运行错误。在测试时,由于老师要求将py格式改为exe格式增加了测试时间。