一.需求分析
根据实验二软件工程个人项目所提要求进行分析后可知用户的需求主要有
1.程序可读入任意英文文本文件,该文件中英文词数大于等于1个,程序需要很壮健,能读取容纳英文原版《哈利波特》10万词以上的文章。
2.指定单词词频统计功能:用户可输入从该文本中想要查找词频的一个或任意多个英文单词,运行程序的统计功能可显示对应单词在文本中出现的次数和柱状图。
3.高频词统计功能:用户从键盘输入高频词输出的个数k,运行程序统计功能,可按文本中词频数降序显示前k个单词的词频及单词。
4.统计该文本所有单词数量及词频数,并能将单词及词频数按字典顺序输出到文件result.txt。
二、功能实现
基本功能
1.用户输入任意英文文本,显示对应单词在文本中出现的次数和对应的单词。
2.用户从键盘输入高频词输出的个数n,按文本中词频数降序显示前n个单词的词频及单词,用户也可输入文本查询其出现次数。
3.统计该文本所有单词数量及词频数,并能将单词及词频数按字典顺序输出到文件result.txt。
扩展功能
读入读出文件功能(将文件进行读取,存放),输入一个文件的文件路径及文件名可以找到该文件并对该文件中的文本进行单词分解和单词词频统计。
三、设计实现
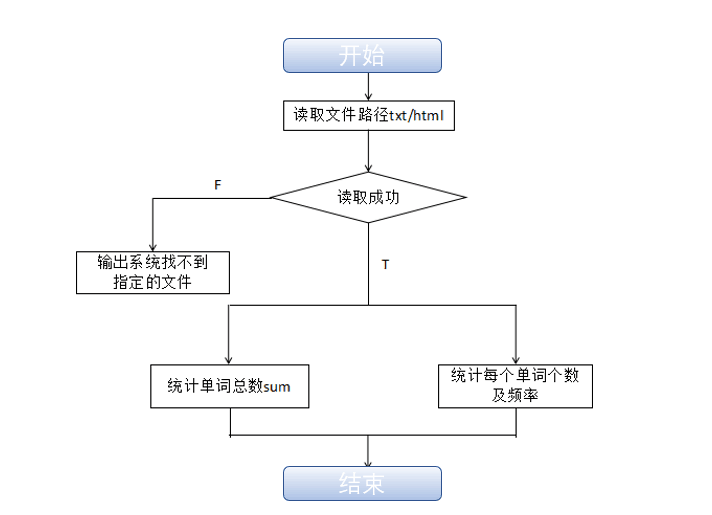
流程图如下
部分代码如下
任意英文文本文件的导入:
利用FileDialog类直接打开本地文件资源管理器,通过选择的方式导入任意英文文本文件。并将其保存在File中,通过BufferedReader读入到StringBuilder类的一个对象中。
实现代码如下:
open.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) { FileDialog jf = new FileDialog(frame, "打开文件", FileDialog.LOAD);
jf.setVisible(true);
String dirName = jf.getDirectory();
String fileName = jf.getFile();
File f = new File(dirName, fileName);
textFile = new StringBuilder();
String b = null;
BufferedReader br;
try {
br = new BufferedReader(new FileReader(f));
while ((b = br.readLine()) != null) {
textFile.append(b);
}
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
});统计该英文文件中单词数
通过字符串的切割使文本变成单词,其中在字符串的切割中遇到了一系列问题,比如文本中的标点符号多样,还有空格,我们需要按照标点符号切割后,在按照空格切换,在这个过程中,有字符串数组到字符串的转换时会自动添加逗号。为了解决这个问题,我使用了字符串的替换。将所有的标点符号用空格替换,然后按照空格切割。
实现代码如下:
public String[] Dell(StringBuilder b){
String s=String.valueOf(b);//转换为字符串
String s1=s.replace(',', ' ');//将逗号用空格替换
String s2=s1.replace('.', ' ');//将句号用空格替换
String s3=s2.replace(';',' ');//将分好用空格替换
String textArry[]=s3.split(" ");//按照空格切割字符串,得到存储着文本中所有英文单词的字符数组 for(int i=0;i<textArry.length;i++){
if( textArry[i].length()==0){//将字符串数组中为空的字符串删除
textArry[i]=textArry[i+1];
}
}
//统计英文单词的数量
String a=String.valueOf(textArry.length);
num.setText("文本中英文单词数量为:"+a);//设置标签的值,显示单词数量
return textArry;
}将单词按字典顺序输出:
使用冒泡排序将得到的字符数组进行排序输入即可,输出的显示采用了textArea
代码实现如下:order.addActionListener(new ActionListener(){
@Override
public void actionPerformed(ActionEvent e) {
JFrame f=new JFrame("排序结果");//新窗体的创建
f.setBounds(800,400,500,600);
JTextArea ta=new JTextArea(10,5);//显示多行文本
ta.setLineWrap(true);
f.add(ta);
String textArry[]=Dell(textFile);
for(int i=0;i<textArry.length;i++){ //冒泡排序
for(int j=0;j<textArry.length-i-1;j++){
if((textArry[j].compareTo(textArry[j+1]))>0){
String temp=textArry[j];
textArry[j]=textArry[j+1];
textArry[j+1]=temp;
}
}
}
StringBuilder sb=new StringBuilder();
for(int i=0;i<textArry.length;i++){
sb.append(textArry[i]);
sb.append(" \n");//每个单词之间添加一个换行
}
ta.setText(String.valueOf(sb));
f.setVisible(true);
}
});单词频率的统计代码如下:
check.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
String[] textArry=Dell(textFile);
CountDao cd=new CountDao();
int tenpCount=0;//单词频率
for(int i=0;i<textArry.length;i++){
for(int j=0;j<textArry.length;j++){
if(textArry[i].equals(textArry[j])){
tenpCount++;
}
}
cd.save( textArry[i],tenpCount);//将单词和出现的频率保存在数据库中
}
}
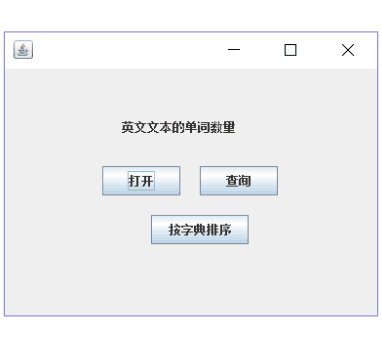
});最终运行结果如下

四、总结
在这次的词频统计软件开发过程中,主要将该软件分成三大模块:
1.文本的单词提取和词频统计、单词匹配后输出
2.根据单词词频排序后输出用户需要查看
3.根据单词字母表顺序排序后保存在文件中。
第一个模块在主函数中实现,而后面三个模块分别通过三个子函数来实现,之后在主函数中被调用,以此来达到软件设计的“模块化”设计。
PSP展示
| PSP2.1 | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 10 | 8 |
| Development | 开发 | 150 | 140 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 50 |
| Design Spec | 生成设计文档 | 10 | 15 |
| Design Review | 设计复审 (和同事审核设计文档) | 6 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| Design | 具体设计 | 15 | 13 |
| Coding | 具体编码 | 120 | 100 |
| Code Review | 代码复审 | 15 | 12 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 15 |
| Reporting | 报告 | 9 | 7 |
| Test Report | 测试报告 | 5 | 5 |
| Size Measurement | 计算工作量 | 1 | 2 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 5 | 4 |
从PSP表中可以看出在开发、需求分析和具体编程这些环节耗时最多而且计划时间和实际时间之间的差距比较大,让我深刻认识到软件开发的不易,单人操作非常困难,需要有几个人合作甚至一个团队来合作完成;
软件开发过程中计划往往赶不上变化,过程中浪费了很多的时间,如果在实际项目中可能浪费财力物力;
我也认识到基础知识的严重不足,需要在网上和教材上搜集相关知识点并重温,耗时较多。因此在后面的学习中,还需要勤加练习,更加熟练的掌握知识点。
该词频统计软件源码可在此处查看