目录
- 写在前面
- 分工
- 摘要
- 解题思路与设计实现
- 附加题设计与展示
- 关键代码解释
- 性能分析与改进
- 单元测试
- 贴出Github的代码签入记录【1'】
- 遇到的代码模块异常或结对困难及解决方法
- 评价队友
- 学习进度条
- PSP表格记录
写在前面
- 博客地址:
- 队友博客地址:
- GitHub地址:
分工
031602507:陈俞辛
- 词组权重功能、附加题构思实现
031602543:周政演 - 爬虫实现、附加题构思、单元测试、博客撰写
摘要
解题思路与设计实现
爬虫
该爬虫可以从CVPR的论文列表上爬取论文题目、摘要,并输出到一个.txt文件中。在此使用两种了工具实现了爬取功能:Java、python
思路
两种语言的实现思路大致相同:
- 发送http请求-
- 获取整个页面的html
- 寻找论文页面的URL
- 循环进入每篇论文页面
- 获取每篇论文的信息
- 输出到result.txt文件
- 其中实现的关键:是找出html的特征部分。也就是能够唯一确定title、abstract位置的html代码段。
- 例如,针对某段html代码;
<dt class="ptitle"><br><a href="content_cvpr_2018/html/Das_Embodied_Question_Answering_CVPR_2018_paper.html">Embodied Question Answering</a></dt>其中下段代码可以在整个html页面中确定url的位置
<dt class="ptitle">通过观察各个页面的url形式,a href = 后的双引号部分中间,加上一段url的头部,即是该篇论文的URL。
贴出python方法的部分代码作为示例:
def GetPaper(FullPaper,begin,end)://获取论文url
left = FullPaper.find('''<dt class="ptitle">''',begin,end)#特征代码首位置
right = FullPaper.find('''</a></dt>''',begin,end)#特征代码末位置
paper = FullPaper[left:right]
str1=paper.split('"') # 分割开该段文本
return str1[3]# 提取url链接- 同时,抓取的过程可以显示抓取进度

- 此部分是提取出来的 PaperList 的部分 url 列表
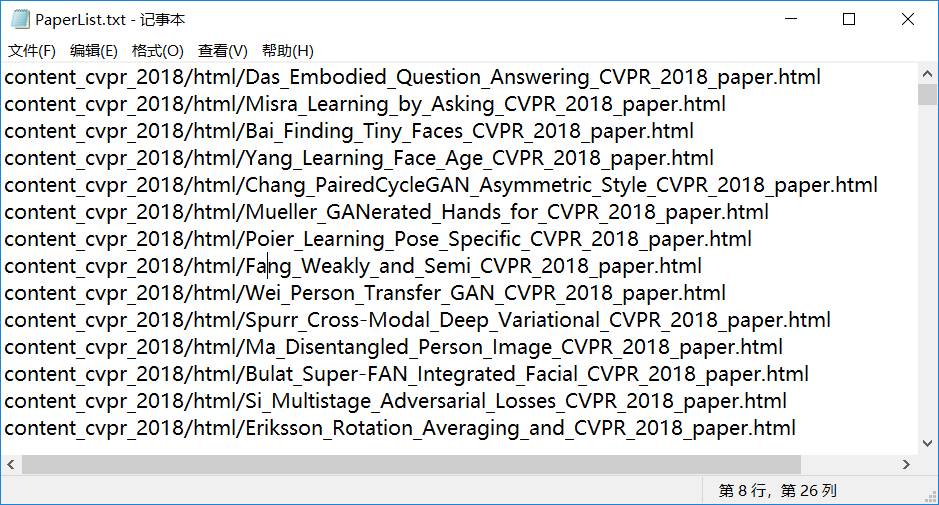

- 此部分为导出的 .txt 文本

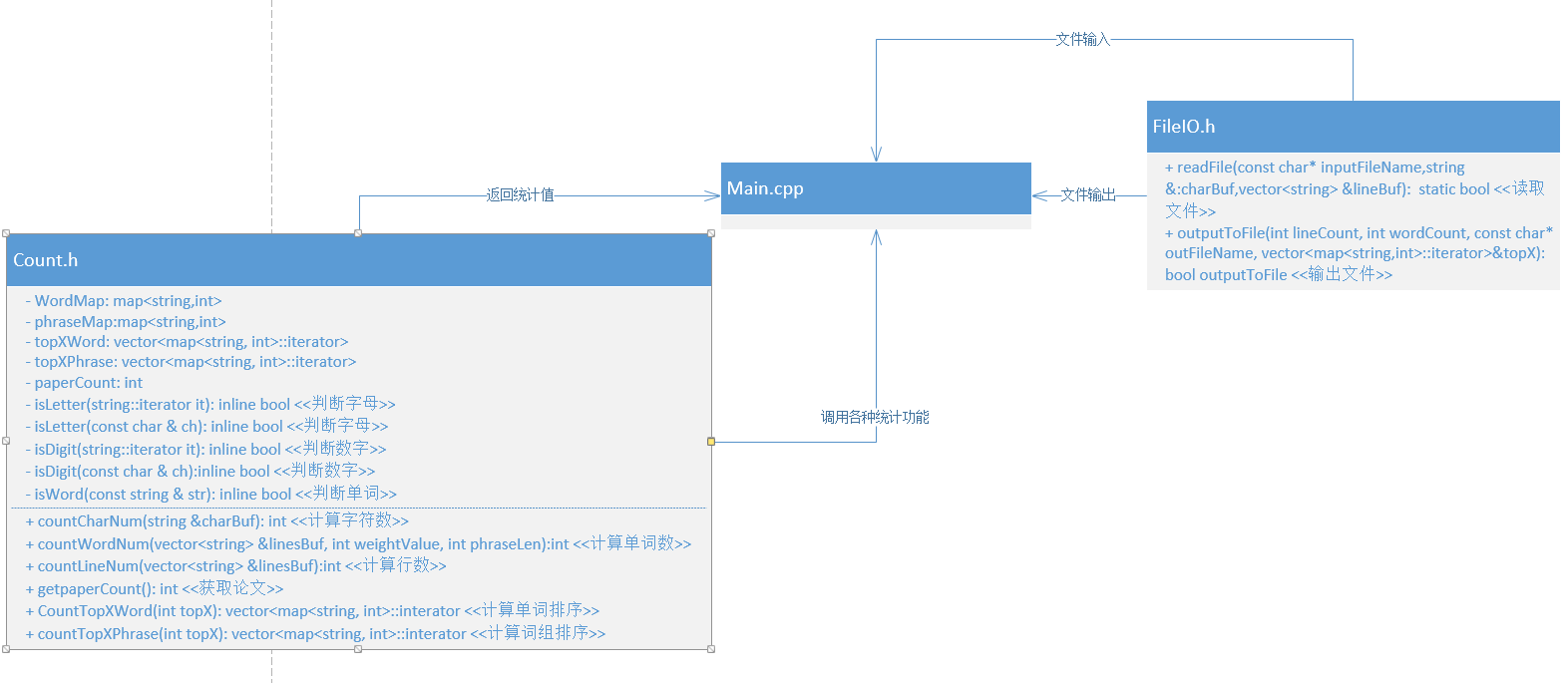
代码组织
- 代码主要由两个关键部分组成:Count类和FileIO.h
- Count类: 由
算法关键
关键代码一:统计出现频率最高的X个词组:
//统计出现频率最高的X个词组
vector<map<string, int>::iterator> & Count::countTopXPhrase(int topX)
{
int phraseMapSize = int(phraseMap.size());
for (int i = 0; i < phraseMapSize && i < topX; i++)
{
auto maxFrxPhrase = phraseMap.begin();
for (map<string, int>::iterator it = phraseMap.begin(); it != phraseMap.end(); it++)
{
if (it->second > maxFrxPhrase->second)
{
maxFrxPhrase = it;
}
}
topXPhrase.push_back(maxFrxPhrase);
maxFrxPhrase->second = -maxFrxPhrase->second;
}
return topXPhrase;
}代码思路
- map中存储的是词组和出现频次的 键-值 对,要统计出现频率最高的X个词组,主要有以下两种思路:
思路一
- 对所有 键-值 对进行排序,从高到低逐个输出词组,得到词组出现频次的排行榜。
- 由于不可直接对map进行排序,所以考虑将map的键值对提取,存入自定义的键值对结构体,然后对结构体进行排序。
- 优点:直接获得排好序的词组排行榜,以后可以根据需要,灵活输出前x个词组的排行。
- 缺点:使用结构体存储,带来空间资源的开销;对结构体数组进行排序,降低了算法性能。
思路二
- 不对 键-值 对进行排序,对map直接进行遍历,找到频次最高的词组。
- 无需对map排序,直接对map遍历,每遍历一次,找到频次最高的词组,然后将该词组置为负数。
- 优点:资源开销小,算法性能高。
二者比较
- 经过测试,思路二的方法性能明显高于思路一,且更不易出错。本次要求无需多次查找不同词组个数的排行榜,思路二更适用于本测试。故使用思路二。
- 思路二遍历 topX 遍的时间复杂度 O(n) , 而思路一若采用快排时间复杂度为 O(nlogn) 如果单词数 > 100,那么思路一更快。如果单词数 < 100,那么思路二更快,但单词数过少,性能的提升十分有限的。
- 算法关键:将每一次遍历找出的最高频词组频率置为负数,这样在下一次遍历的时候就不会被重复查找,并且在输出的时候只需要取负输出即可。
函数流程图:
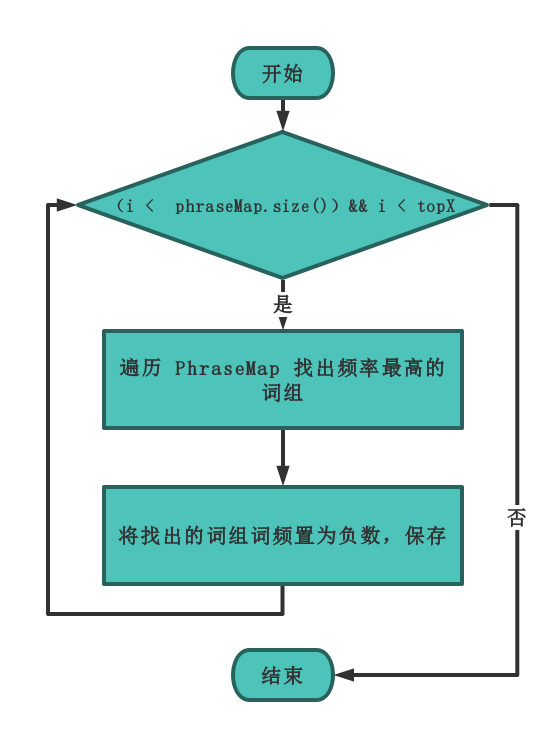
- 注:( 其中
topX指命令行输入的自定义词频,如果不指定默认为 10) 。
关键代码二:加入权重的词频统计(部分)
if (wordBuf == "title" && linesBuf[i][j] == ':' && j == 5)
{
paperCount++; //每出现一个 title: 说明是一篇论文
isTitle = true;
wordBuf = "";
continue;
}
if (wordBuf == "abstract" && linesBuf[i][j] == ':' && j == 8)
{
isTitle = false;
wordBuf = "";
continue;
}- 根据需求:属于 Title 的单词权重为10,属于 Abstract 单词权重为1 。首先要区分,单词是属于 Title 部分还是 Abstract 部分。
- 通过检测到文本中的 title 区分: (读取文件时已经都转为小写) 设置一个 flag 来标记 title 。
- 同时,为了避免文中本身有 title: 这样的串,必须是出现在行首的才设置flag
- 算法过程:对全文进行遍历操作,当文本为 title:串,且出现在行首时,设置一个flag作为标记,以此来确定,之后的单词属于 title 部分
附加题设计与展示
设计的创意独到之处
实现思路
实现成果展示
关键代码解释
本次算法的关键我认为是 词组的统计。因为这个功能算是这次的新加功能。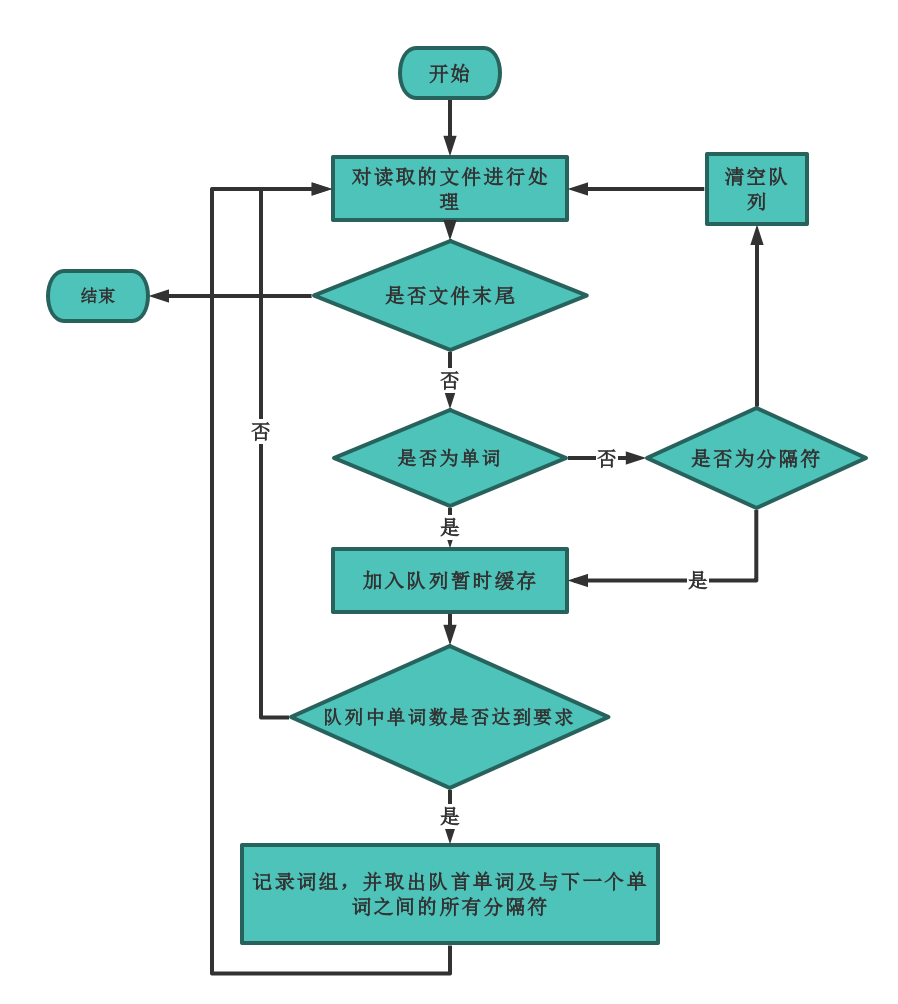
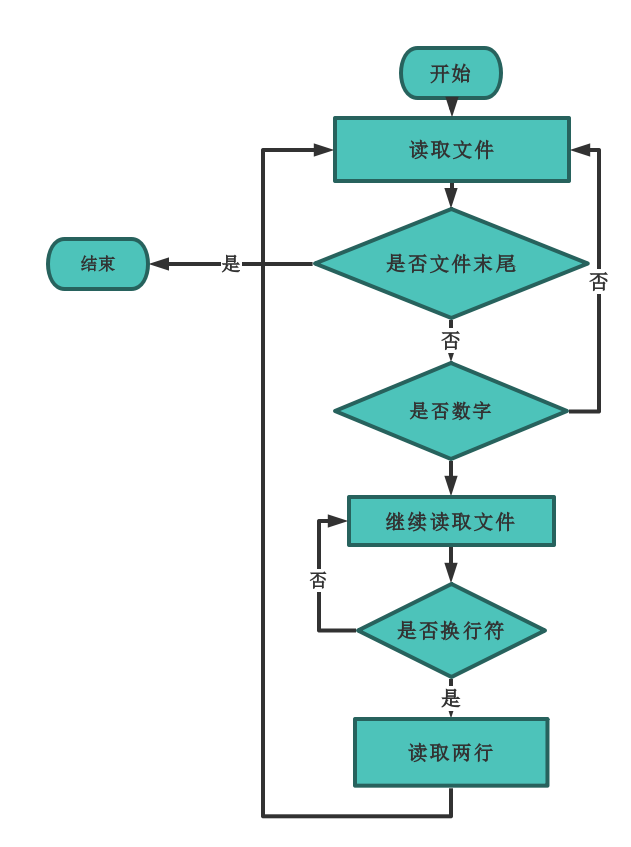
此外文件的读取同样重要,因为有部分的字符是不需要读取的并且有固定的格式,因此需要额外的处理。对于每一篇论文都只读取 title 和 abstract 两个字段的内容。每次开始读取前都先将论文编号跳过(也就是判断为数字则继续读取下一个字符直至换行符出现)然后读取两行。然后继续等待数字出现。
性能分析与改进
0
Title: Monday Tuesday Wednesday Thursday
Abstract: Monday Tuesday Wednesday Thursday Friday一开始,我是将词组统计功能加在了单词统计功能中。也就是说不论是否开启词组统计功能我都会进行统计,只不过不输出而已,那么很明显这样子的性能十分受影响。
在改进中,我将两个功能分离,分成了 countWordNum 和 countPhraseNum 两个函数,可以分别调用。
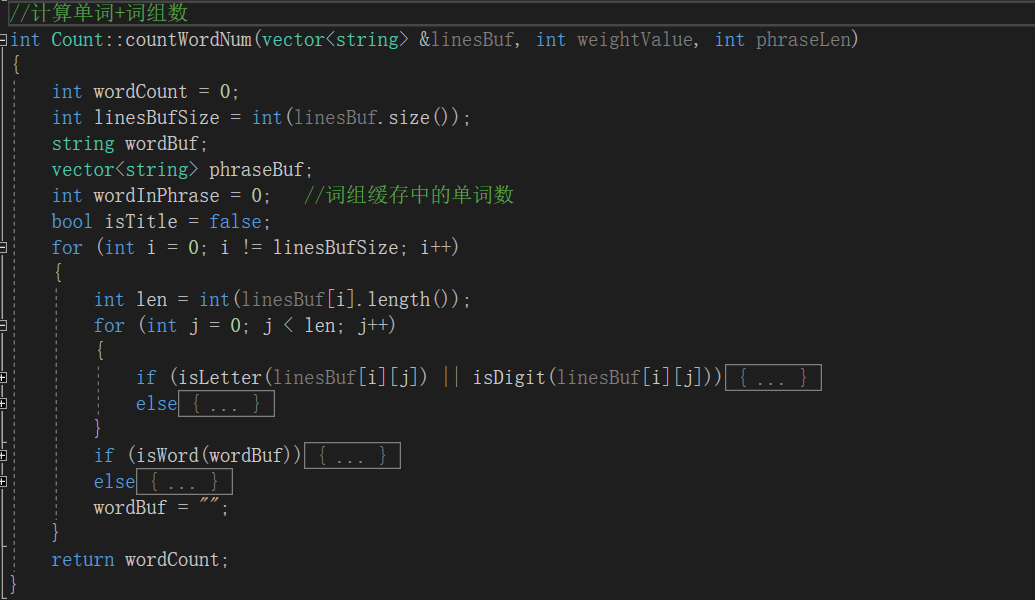
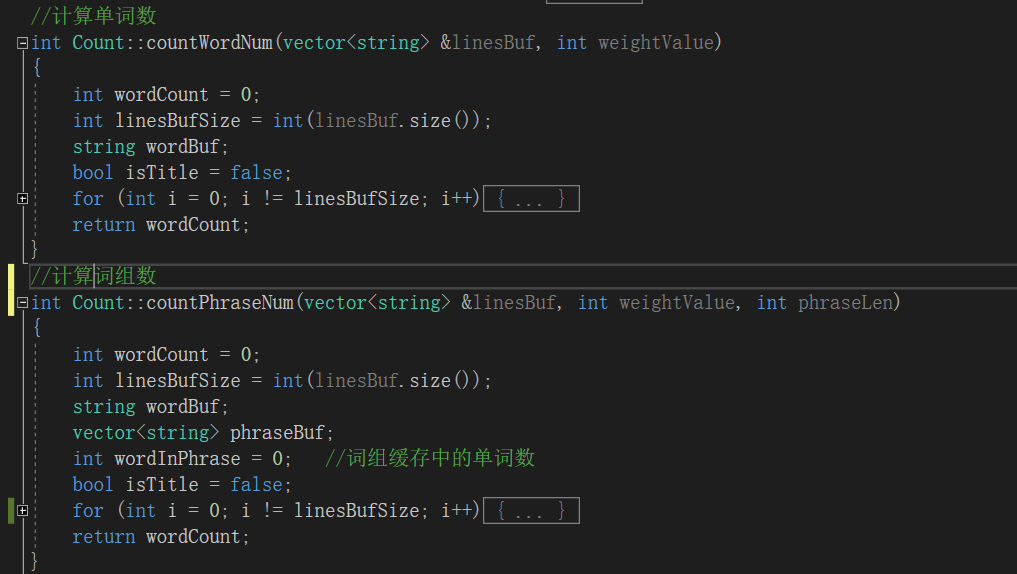
描述你改进的思路
展示性能分析图和程序中消耗最大的函数

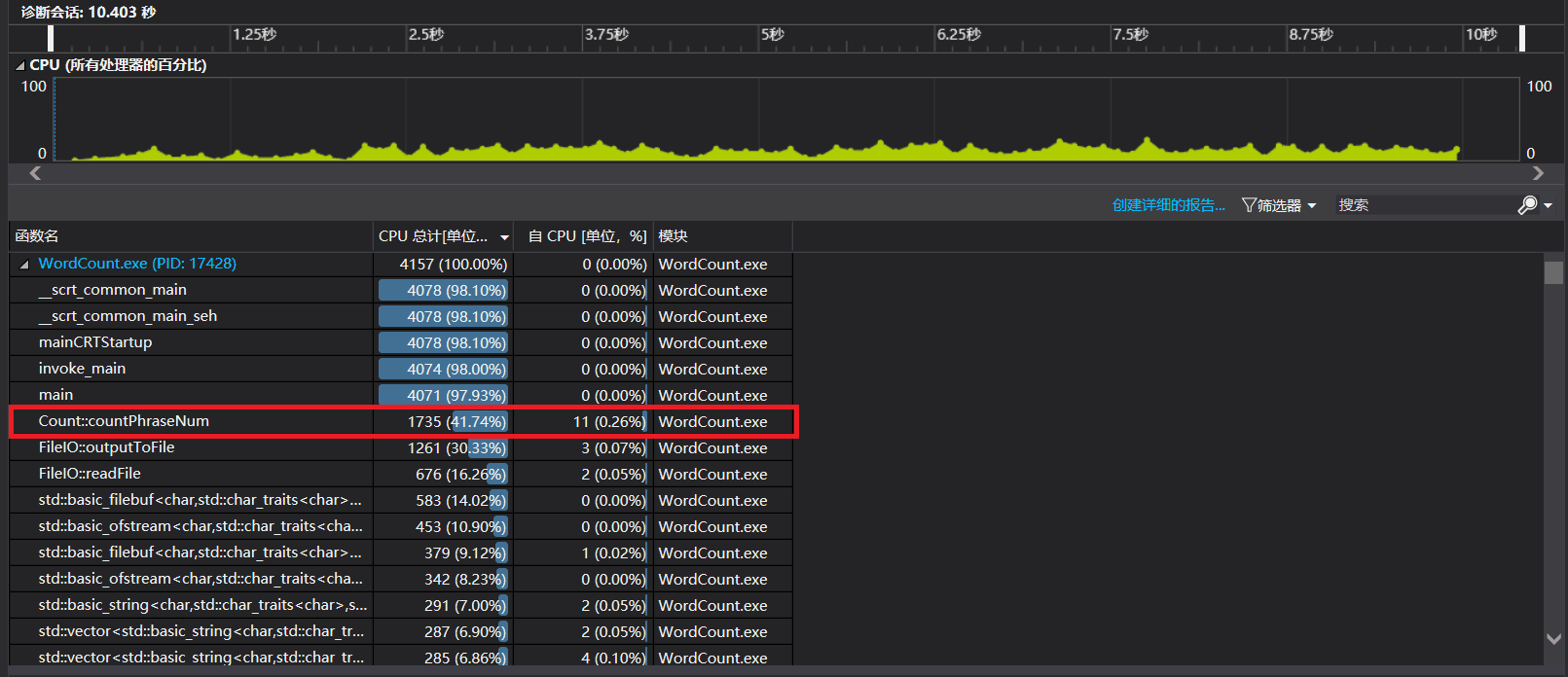
单元测试
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
序号 | 测试用例 |测试对象 | 测试意图 |测试结果
---|---|---|---|---
1 |文件名输入错误|readFile(inputFileName, charBuf, linesBuf)|测试读取文件函数|返回false,通过
2 |文件名输出错误|outputToFile(characterCount, wordCount, lineCount, outputFileName, topX)|测试输出文件函数|返回false,通过
3 |一篇论文测试|countCharNum(charBuf)|测试字符统计功能|通过
4 |一篇论文测试|countWordNum(linesBuf,weightValue)|测试单词统计功能|通过
5 |一篇论文测试|countWordNum(linesBuf, weightValue)|测试当加入权重时单词个数统计是否影响|通过
6 |多个词组测试|countTopXWord(topX)|测试无权重单词词频统计功能|通过
7 |多个词组测试|countWordNum(linesBuf, weightValue)|测试有权重单词词频统计功能|通过
8 |多篇论文测试|countPhraseNum(linesBuf, 0, 2)|测试词组统计功能|符合字典序
9 |更多词组测试|countLineNum(linesBuf)|测试行数统计功能|通过
10 |修改词组形式|countTopXWord(10))|文本为 cvpr2018 官网爬取结果,测试所有功能|迭代器崩溃,更改后通过
11 |增加特殊用例测试|count.countTopXPhrase(10)|测试单词之间有多个分隔符的词组|通过
12 |单个特殊用例测试|topXPhrase = count.countTopXPhrase(10)|测试单词之间有不合法单词的词组|输出为0,通过
其中,7号测试用例的代码,测试有权重单词词频统计功能:
TEST_METHOD(TestMethod7) //测试有权重单词词频统计功能
{
int weightValue = 1;
int topX = 10;
const char* inputFileName = "../WordCountTest/input5.txt";
string charBuf;
vector<string> linesBuf;
Assert::AreEqual(FileIO::readFile(inputFileName, charBuf, linesBuf), true);
Count count;
Assert::AreEqual(count.countWordNum(linesBuf, weightValue), 11);
vector<map<string, int>::iterator> topXWord = count.countTopXWord(topX);
Assert::AreEqual(topXWord[0]->first, string("abcd"));
Assert::AreEqual(-topXWord[0]->second, 31);
Assert::AreEqual(topXWord[1]->first, string("abce"));
Assert::AreEqual(-topXWord[1]->second, 10);
Assert::AreEqual(topXWord[2]->first, string("abcf"));
Assert::AreEqual(-topXWord[2]->second, 10);
Assert::AreEqual(topXWord[3]->first, string("abcg"));
Assert::AreEqual(-topXWord[3]->second, 10);
Assert::AreEqual(topXWord[4]->first, string("asda"));
Assert::AreEqual(-topXWord[4]->second, 3);
Assert::AreEqual(topXWord[5]->first, string("abch"));
Assert::AreEqual(-topXWord[5]->second, 1);
}12号测试用例,测试是否存在不合法词组,增强程序鲁棒性:
TEST_METHOD(TestMethod12) //测试单词之间有不合法单词的词组
{
const char* inputFileName = "../WordCountTest/input10.txt";
string charBuf;
vector<string> linesBuf;
Assert::AreEqual(FileIO::readFile(inputFileName, charBuf, linesBuf), true);
Count count;
Assert::AreEqual(count.countPhraseNum(linesBuf, 0, 2), 4);
vector<map<string, int>::iterator> topXPhrase = count.countTopXPhrase(10);
Assert::AreEqual(topXPhrase[0]->first, string("delicious apple"));
Assert::AreEqual(-topXPhrase[0]->second, 1);
}测试结果以及代码覆盖率附图
贴出Github的代码签入记录【1'】
请合理记录commit信息遇到的代码模块异常或结对困难及解决方法
- 爬虫部分,出现乱码的问题:上网查找正确编码的方式,使用 UTF-8 编码。
- 编码接口:在做单元测试时,需要了解需要测试部分的函数功能、接受参数、返回值、调用方式等等:写出详细的接口说明,介绍有关功能、参数等,对函数进行单元测试。
问题描述
- 爬虫部分,出现乱码的问题:
- 编码接口交互:在做单元测试时,需要了解需要测试部分的函数功能、接受参数、返回值、调用方式等等
- 单元测试,检测出队友代码的bug
做过哪些尝试
- 上网查找正确编码的方式,使用 UTF-8 编码。
- 写出详细的接口说明,介绍有关功能、参数等,对函数进行单元测试。
- 和队友详细介绍单元测试测出的问题,帮助队友改进源代码
是否解决
- 解决
- 解决
- 解决
有何收获
- 了解了爬虫相关的编码问题的解决策略
- 在和队友沟通中发现,分工并不是那么简单,若是没有合理到位的沟通,没有把接口等信息描述清的话,一加一或许未必大于二,甚至会小于二。幸亏及时预见了接口说明的重要性,在接口说明方面下了大的功夫,对各个接口详细报告,实现了单元测试的代码,达到了一加一大于二的效果。
- 当局者迷,旁观者请。有时候自己也未能发现代码中的bug,代码看似完美,实则需要经过多方的检验。而在编码功能不繁重的情况下,若是二人编码,编码功能存在耦合,则编码交互带来的效率损耗很可能大于肚子编码。所以,一人主要负责编码,一人主要负责单元测试,适当地兼顾了结对编程的优点,又规避了其缺点,做到相互裨补缺漏、相得益彰。
评价队友
值得学习的地方
需要改进的地方
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 68 | 68 | 6 | 6 | python字符处理复习、爬虫学习 |
| 2 | 78 | 146 | 7 | 13 | java爬虫学习 |
| 3 | 194 | 340 | 6 | 19 | 单元测试设计 |
PSP表格记录
| PSP2.1 | header 2 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 35 | 30 |
| · Estimate | ·估计这个任务需要多少时间 | 15 | 5 |
| Development | 开发 | 645 | 1220 |
| · Analysis | 需求分析(包括学习新技术) | 40 | 80 |
| · Design Spec | · 生成设计文档 | 40 | 120 |
| · Design Review | · 设计复审 | 10 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 120 | 180 |
| · Coding | · 具体编码 | 600 | 1200 |
| · Code Review | · 代码复审 | 30 | 180 |
| · Test | ·测试(自我测试,修改代码,提交修改) | 240 | 420 |
| Reporting | 报告 | 245 | 145 |
| · Test Repor | · 测试报告 | 240 | 120 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 2265 | 3785 |