决策树作为一种分类算法,由于其强解释性与低学习成本,而广受欢迎,本篇文章仅从理论层面解释该算法的实现逻辑与数学推导过程。
说起决策树,离不开对信息熵的理解,该词来源于信息论,信息熵这个词对于我们来说比较陌生,用书面语说,信息熵就是所有可能发生事件所带来的信息量的期望。我用自己的通俗理解将其解释为:获取一个结论所需要的信息量(或者说获取结论而需要付出的代价)。举个例子,我需要判断一只鸡是公鸡还是母鸡,很简单,只需要观察它的鸡冠,鸡冠大的肯定是公鸡,而母鸡的鸡冠则非常小。对于我来说,获取一只鸡是公鸡还是母鸡所需的信息量非常小,只是因为在鸡群中多看了你一眼,再也无法忘掉你容颜。那么我可以说对于获取鸡的雌雄所需的信息熵很小。而另一种情况,我需要判断一个人的性格是外向还是内向,光看他一眼可能就难以判断了,我还需要和他交往,听他说话的语气,看他的兴趣爱好以及工作性质,甚至还要去深入了解他的朋友圈。这实代价实在太大了,则对于断定一个人是外向还是内向这件事的信息熵就很大。
用通俗的语言解释了信息熵之后,接下来我们先回到统计学的一个概念上来——二项分布。
我们知道抛一枚硬币,结果只有两种——要么正面,要么反面。对于抛硬币这样一件事来说,就符合二项分布。这个比较好理解,一件事的发生情况只有两种(我们可以记为0和1),0发生的概率为P,那么1发生的概率自然就是(1-P)。我们将出现正面记为1,出现反面为0,出现正面概率为P1,出现反面概率为P0。则我们可以将一次某一次抛硬币事件的概率表述为:

其中
 。
。
有了这个二项分布的理解之后,再回到我们需要讨论的信息熵上面来。首先找到一个数据集,该数据集来自一位博友的文章:
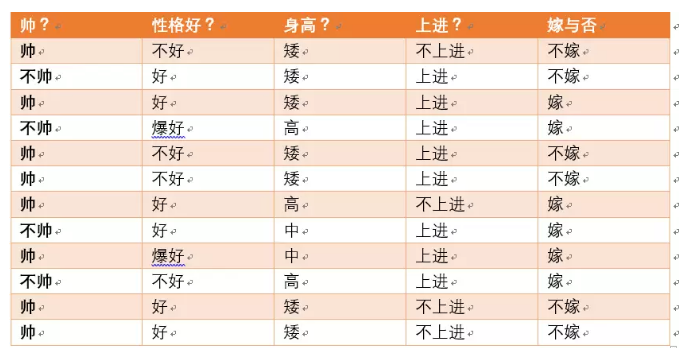
对于以上12个样本来说,第i个单独样本的模型结果pi的事件概率(靠谱程度)就是上面的二项分布的概率公式。根据这个公式,我们可以求取整个数据集的似然函数(在这里,可以把似然函数简单地理解为整个事件发生的可能性):

我们构建模型的目的,就是要让该似然函数代表的概率达到最大。我们求信息熵的最终步骤就是要求整个函数的最大值。我个人最开始在这里理解起来很吃力(毕竟我不是统计学专业的,可能脑子也不太好使),我是这样笨拙地理解的:首先,上面的样本数据是真实发生了的,但真实也只是所有可能发生的情况的其中一种,虽然已经发生了(对于已经发生的事,我们可能会下意识地认为这件事的概率就是1,因为已经发生了的事情就已经是必然的了),但这件事情在发生之前出现的概率就不是1,而应该是上述的似然函数(站在二项分布的角度也就是抛硬币的例子去理解,会更容易一些)。下面是求取该函数的最大值的过程:
我们先对目标函数两边分别取对数并取反得到:

求原函数的最大值等价于求该函数的最小值。
求取该函数的二阶导数,我们可以发现,二阶导恒大于0:

因此,这是一个仅有一个最小值的凸函数,为求极值对应的函数参数,只需求其一阶导等于0即可,即求 pi 使得其一阶导数为0。
在这里,由于pi是一个定值,因此我们可以将公式转化为如下求导,其中pk是第k个数据的概率预测值(即pi):
公式展开如下:

化解得到:

求解可得:

其中m为该节点样本总数,分子部分为该节点正样本数,则pk即为该节点正样本的比例。将pk带入公式得到:

进一步为了消除节点样本个数对该值的影响,使用节点样本数对该结果做归一化,得到:

最后这个结果就是我们所看到的信息熵公式,当然这里因为是二项分布,是比较特殊的,而真正的通用信息熵公式为:
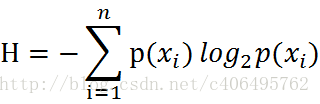
然后我们将样本中的数据代入此公式,则可以得到一个信息熵,该信息熵称为经验信息熵(也就是根据样本数据计算出来的一个信息熵)。
在该数据集中,最终分类结果只有两类,即嫁和不嫁。根据表中的数据统计可知,在12个数据中,6个数据的结果为嫁,6个数据的结果为不嫁。
可以统计出,嫁的个数为6/12 = 1/2
不嫁的个数为6/12 = 1/2
所以数据集D的经验熵H(D)为:
H(Y) = -1/2log1/2 -1/2log1/2
好了,到此,对于信息熵的解释已经完成了。接下来,我们需要理解的是条件熵。
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
以下为条件熵的公式:
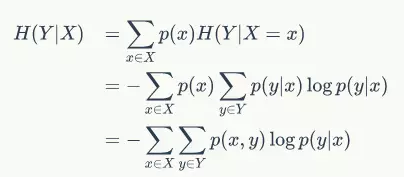
还是以该例子来说明,我们将同样Y表示为:随机变量Y={嫁,不嫁}
为了引入条件熵,我们引入一个新的变量,即帅或不帅, 将X设为:随即变量X={帅,不帅}
如下图:
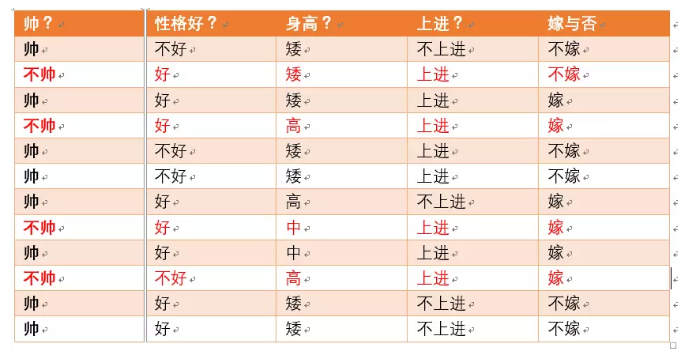
当已知不帅的条件下,对应了4个结果,这四个结果中,不嫁的个数为1个,占1/4;嫁的个数为3个,占3/4
那么此时: H(Y|X = 不帅) = -1/4log1/4-3/4log3/4
同时可知,长得不帅的概率为:p(X = 不帅) = 4/12 = 1/3
当已知帅的条件下,则对应了8个结果,这八个结果中,不嫁的个数为5个,占5/8;嫁的个数为3个,占3/8
那么此时的H(Y|X = 帅) = -5/8log5/8-3/8log3/8
同时可知,长得不帅的概率为:p(X = 帅) = 8/12 = 2/3
于是最后条件熵的最终结果就是:
H(Y|X=长相) = p(X =帅)*H(Y|X=帅)+p(X =不帅)*H(Y|X=不帅)
将数据代入即可,这里就不具体算了。
最后我们来解释信息增益,就非常简单了。
用公式理解就是:
信息增益 = 经验熵 - 条件熵
用通俗的话理解就是,当加入了一个判断条件之后,我需要判定一个结论所需要的信息熵相比之前就有所减少了,这减少的量就是信息增益。回到最初的例子,我要判断一个人是外向还是内向,原本需要的信息量特别大,这个信息量可以看做是经验熵。但是,当我知道了他的爱好和朋友圈之后,我对他性格的判断就非常容易了,而此时我所需要的信息量就只是条件熵了,该条件带给我的好处(这里的好处就是我判断他的性格变得比之前容易多了)就可以看做是信息增益。
决策树模型最终就是要求取信息增益最大的那个特征作为最有特征项,因为只有该特征才能让我最容易地对信息作出结论的判断。
以上就是我对决策树里的信息熵、条件熵以及信息增量的粗浅理解。本人很少写博客,技术也属于菜鸟级别,有不对的地方,还望各位博友多多指点与纠正,在此谢过。
本篇文章涉及的小案例和数学公式推导部分摘自博友的博客,文章末尾将注明出处。
通俗理解条件熵:https://blog.csdn.net/xwd18280820053/article/details/70739368
决策树的数学原理:https://blog.csdn.net/xsqlx/article/details/51120485