普通队列是按照先进先出的顺序执行,出队顺序与入队顺序有关,优先队列出队顺序和入队顺序无关,与优先级相关.优先队列与动态选择优先级高的任务执行的需求有关,普通队列无法满足。首先说堆,堆也是种树形结构,比如二叉堆。二叉堆是一颗完全二叉树,完全二叉树是把元素顺序排成树形结构,从左至右依次排,如果元素不够也是右侧未排满。二叉堆除了要求完全二叉树,还有对元素大小有要求,有最大堆和最小堆之分,对于最大堆,堆中某个结点最大值总是不大于其父结点值,而最小堆则是相反,最大堆结构示意图如下图所示
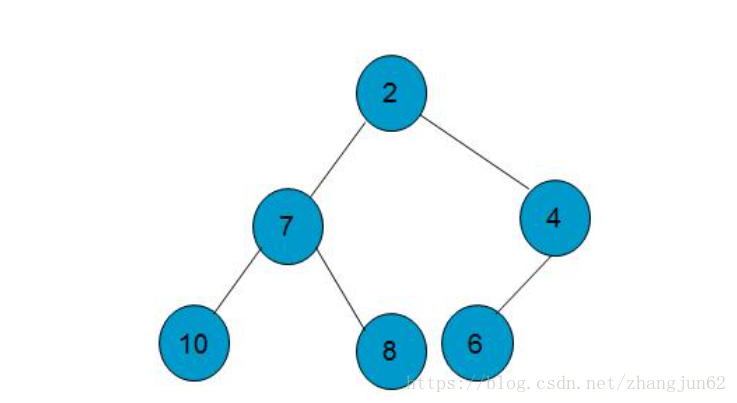
而实现时用数组保存二叉堆的数据,所以要弄清楚父结点即左右孩子结点索引关系.从1开始计算索引,则关系是parent(i) = i / 2,i表示当前索引,parent(i)是其父结点索引,相应的是left child (i) = 2 * i,right child (i) = 2 * i + 1, 对于索引从0开始计算则parent(i) = (i - 1) / 2, left child (i) = 2 * i + 1,right child (i) = 2 * i + 2.堆有sift up、sift down、replace和heapify,sift down上浮操作主要用于向堆中添加一个元素,首先添加在末尾,为了保证堆结构所以不断与其父结点及以上的父结点,直到符合最大堆要求叫上浮;sift down下沉操作,提取最大元素也就是最大值元素,首先将最大值元素与堆末尾元素对调位置,然后删掉最大元素,为保证堆结构,需要将此时的堆首元素下沉,不断与左右孩子最大的比较,直到符合要求;replace是提取首元素插入新元素,也需要用到sift down操作;heapify是实例化时堆时把传入的普通数据生成堆结构,就是从最后一个元素的父结点开始,往上,将每个父结点sift down 相应的位置以形成相应的堆结构.具体的实现过程如下,利用前面文章(https://blog.csdn.net/zhangjun62/article/details/82720572)实现的Array.
public class MaxHeap<E extends Comparable<E>> { //最大堆类 使用数组保存数据
private Array<E> data; //声明数组用于存储数据
public MaxHeap(int capacity) { //有参构造函数,以输入容量大小生成堆数组
data = new Array<>(capacity);
}
public MaxHeap(E[] arr) { //有参构造函数,以传入数组生成最大堆也就是heapify操作
data = new Array<>(arr); //根据传入数组赋给data
//上述数据是直接赋给data的,不符合堆的定义,需要进行相应操作
//从最后一个结点的父结点开始往上遍历进行sift down操作,以保证堆的数据结构
for(int i = parent(arr.length -1); i >= 0; i--) {
siftDown(i);
}
}
public MaxHeap() { //无参构造函数, 已默认大小生成data数组
data = new Array<>();
}
public int size() { //获取堆尺寸大小
return data.getSize();
}
public boolean isEmpty() {//判断堆是否为空
return data.isEmpty();
}
//辅助函数, 根据索引找其父结点索引,根结点无父结点
private int parent(int index) {
if(index == 0)
throw new IllegalArgumentException("Index zero does't hava parent");
return (index - 1) / 2;
}
//辅助函数,根据索引寻找左孩子索引
private int leftChild(int index) {
return index * 2 + 1;
}
//辅助函数,根据索引寻找右孩子索引
private int rightChild(int index) {
return index * 2 + 2;
}
//向堆中添加一个元素
public void add(E e) {
data.addLast(e); //在堆末尾添加一个元素
siftUp(data.getSize() - 1);//为了符合堆结构定义,做sift up 操作也就是上浮操作
}
//辅助函数 数据上浮操作
private void siftUp(int k) {
//循环遍历整个堆,如果该元素的父结点值比当前元素值小则进行相应循环
while(k > 0 && data.get(parent(k)).compareTo(data.get(k)) < 0) {
//交换两个元素
data.swap(k, parent(k));
//索引等于父结点索引,继续循环比较
k = parent(k);
}
}
//寻找最大值 由于是最大堆 首元素就是最大值
public E findMax() {
//如果此时堆为空,则抛出异常
if(data.getSize() == 0)
throw new IllegalArgumentException("Can not find maxvalue when heap is empty.");
return data.get(0); //返回最大值
}
//抽取最大堆中最大值
public E extractMax() {
E ret = findMax(); //找到最大值,并保存
data.swap(0, data.getSize() - 1);//交换堆首元素与最后一个元素交换位置
data.removeLast(); //将最后一个元素删除,这时是真正删除最大值元素
siftDown(0); //由于是将堆末尾元素放在堆首,所以需要做sift down操作也就是下沉操作
return ret; //返回保存的最大值元素
}
//辅助函数, sift down 操作,保证堆数据结构
private void siftDown(int k) {
//遍历堆,调整数据位置,以保证堆的数据结构
while(leftChild(k) < data.getSize()) {
//首先保存该结点的左孩子索引
int j = leftChild(k);
//j + 1是该结点的有孩子索引
//如果右孩子索引没越界并且 右孩子的元素大于左孩子元素 则将右孩子索引赋给j,表明j是左右结点值大的元素的索引
if(j + 1 < data.getSize() && data.get(j + 1).compareTo(data.get(j)) > 0) {
j = rightChild(k);
}
//如果当前结点结点元素不小于j代表的元素, 则直接跳出循环,下沉结束
if(data.get(k).compareTo(data.get(j)) >= 0)
break;
data.swap(k, j); //交换两个元素
k = j; //将j赋给K, 循环继续
}
}
//replace操作 取出堆顶元素(最大元素),放入新元素
public E replace(E e) {
E ret = findMax(); //找到最大元元素
data.set(0, e); //将堆顶元素设置为新元素
siftDown(0); //由于设置的新元素会破坏堆结构,将堆顶元素执行下沉操作
return ret; //返回最大值元素
}
}
以上是最大堆实现过程,下面是利用最大堆实现优先队列,首先也是定义一个Queue接口,再利用上面的最大堆实现此接口.
1、Queue接口
public interface Queue<E> { //队列接口
int getSize(); //获取队列大小
boolean isEmpty(); //判断队列是否为空
void enqueue(E e); //入队
E dequeue(); //出对
E getFront(); //获取队首元素
}
2、PriorityQueue
public class PriorityQueue<E extends Comparable<E>> implements Queue<E>{
private MaxHeap<E> maxHeap; //声明一个最大堆用于保存数据
public PriorityQueue() { //无参构造函数,生成默认大小的堆
maxHeap = new MaxHeap<>();
}
@Override
public int getSize() { //获取队列尺寸大小
return maxHeap.size();
}
@Override
public boolean isEmpty() { //判断队列是否为空
return maxHeap.isEmpty();
}
@Override
public E getFront() { //获取队首元素
return maxHeap.findMax();
}
@Override
public void enqueue(E e) { //入队
maxHeap.add(e);
}
@Override
public E dequeue() { //出队
return maxHeap.extractMax();
}
}
以上就是实现堆和优先队列的总过程,对于堆和优先队列还有许多内容需要学习,继续努力