Map是一种映射类集合,相比于Set既有键也有值,以一对键值对形式存储,不能存在相同元素(键不能相同),首先和前面的Set一样,定义一个Map接口类,分别用链表和二分搜索树来实现,由于结点元素需要存储的是一对键值对,所以不用前面文章的链表和二分搜索树,重新定制一下结点信息和相应的数据结构,下面是实现过程。
1、Map接口
public interface Map<K, V> { //映射Map接口类
void add(K key, V value); //添加元素,需要键和值
V remove(K key); //根据键来删除值,并返回该元素
boolean contain(K key); //根据键判断是否存在某元素
V get(K key); //根据键获取相应值
void set(K key, V newValue);//根据输入更新元素
int getSize(); //获取大小
boolean isEmpty(); //判断是否为空
}
2、用链表实现Map
public class LinkedListMap<K, V> implements Map<K, V> {
private class Node { //定义一个私有结点内部类
public K key; //键
public V value; //值
public Node next; //指示结点
public Node(K key, V value, Node next) {
this.key = key;
this.value = value;
this.next = next;
}
public Node(K key, V value) {
this(key, value, null);
}
public Node() {
this(null, null, null);
}
@Override
public String toString() {
return key.toString() + " : " + value.toString();
}
}
private Node dummyHead; //声明虚拟头结点
private int size; //声明尺寸大小
public LinkedListMap() { //无参构造函数
dummyHead = new Node(); //实例化头结点
size = 0;
}
//辅助函数 根据键获取到相应结点
private Node getNode(K key) {
//生成当前结点指向虚拟头结点下一个结点
Node cur = dummyHead.next;
//从当前结点开始遍历
while (cur != null) {
//如果找到则返回当前结点
if (cur.key.equals(key))
return cur;
cur = cur.next; //指向下一结点
}
return null; //遍历整个Map集合都没找到,返回空
}
@Override
public void add(K key, V value) { //添加一个元素
Node node = getNode(key); //根据此键查找集合中是否存在此键
//如果返回为空说明传入此键不存在,则以此键值对构建一个结点
if (node == null) {
dummyHead.next = new Node(key, value, dummyHead.next);
size++;
} else
//否则,此键存在,则更新其值
node.value = value;
}
//删除元素
@Override
public V remove(K key) {
//建立以个指向虚拟头结点的前驱结点
Node prev = dummyHead;
//遍历整个集合
while(prev.next != null){
//如果条件成立,表明找到待删除结点的前驱结点
if(prev.next.key.equals(key))
break;
prev = prev.next; //不断指向下一个结点
}
if(prev.next != null){
Node delNode = prev.next; //保存一下待删除结点,保证后面返回
prev.next = delNode.next; //前驱结点指向待删除结点下一个结点
delNode.next = null; //待删除结点指向空,彻底断开此节点与集合的联系
size --;
return delNode.value;
}
return null;
}
@Override
public void set(K key, V newValue) {
Node node = getNode(key);
if (node == null)
throw new IllegalArgumentException(key + "does't exist!");
node.value = newValue;
}
@Override
public V get(K key) { //根据键返回值
Node node = getNode(key); //根据键去找相应结点
return node == null ? null : node.value; //根据返回值的不同返回相应结果
}
@Override
public int getSize() { //获取集合大小
return size;
}
@Override
public boolean isEmpty() { //查看集合是否为空
return size == 0;
}
@Override
public boolean contain(K key) { //判断含有某键的结点是否存在
return getNode(key) != null;
}
}
2、用二分搜索树实现Map
public class BSTMap<K extends Comparable<K>, V> implements Map<K, V> {
private class Node { //定义了一个私有结点内部类
public K key; //键
public V value; //值
public Node left, right;// 声明左右结点
public Node(K key, V value) { // 有参构造函数,根据传入键值生成结点
this.key = key;
this.value = value;
left = null;
right = null;
}
}
private Node root; //声明根结点
private int size; //声明尺寸大小
public BSTMap() { //无参构造函数
root = null; //根结点为空
size = 0; //初始尺寸为0
}
@Override
public int getSize() { //获取集合大小
return size;
}
@Override
public boolean isEmpty() { //判断集合是否为空
return size == 0;
}
//私有辅助函数,根据传入结点和键找到与其相应的结点,采取递归思想
private Node getNode(Node node, K key) {
//递归终止条件
if (node == null)
return null;
//键相等则返回结点
if (key.compareTo(node.key) == 0)
return node;
//如果小于当前结点键则在当前结点左子树寻找
else if (key.compareTo(node.key) < 0)
return getNode(node.left, key);
else
//如果大于当前结点键则在当前结点右子树寻找
return getNode(node.right, key);
}
@Override
public boolean contain(K key) { //根据键判断相应结点是否存在
return getNode(root, key) != null;//根据私有函数返回值判断
}
@Override
public void add(K key, V value) {//利用一个键值对向集合中添加一个元素
root = add(root, key, value);
}
//真正调用的添加元素,根据传入结点、键值对实现添加操作,私有化,递归思想
private Node add(Node node, K key, V value) {
//递归终止条件
if (node == null) { //当结点为空时以相应的键值对产生新结点,维护size,并返回
size++;
return new Node(key, value);
}
//如果键比当前结点键小则在左子树递归寻找
if (key.compareTo(node.key) < 0) {
node.left = add(node.left, key, value);
//如果键比当前结点键大则在右子树递归寻找
} else if (key.compareTo(node.key) > 0) {
node.right = add(node.right, key, value);
}
//如果该键已存在则以传入的值更新该结点的值
else {
node.value = value;
}
return node;
}
//找到最小键的结点的函数,私有化,递归思想,也就是一直找到树中最左边结点
private Node minimum(Node node) {
if (node.left == null)
return node;
return minimum(node.left);
}
//删除最小键结点函数,递归思想
private Node removeMin(Node node) {
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}
node.left = removeMin(node.left);
return node;
}
//根据键删除该结点
@Override
public V remove(K key) {
Node node = getNode(root, key);
if (node != null) {
root = remove(root, key);
return node.value;
}
return null;
}
//删除结点真正调用的函数,递归思想
private Node remove(Node node, K key) {
if (node == null)
return null;
if (key.compareTo(node.key) < 0) {
node.left = remove(node.left, key);
return node;
} else if (key.compareTo(node.key) > 0) {
node.right = remove(node.right, key);
return node;
} else {
// 待删除结点左子树为空的情况
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}
// 待删除结点右子树为空的情况
if (node.right == null) {
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
}
// 待删除节点左右子树均不为空的情况
// 找到比待删除节点大的最小节点, 即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点的位置
Node successor = minimum(node.right);
successor.right = removeMin(node.right);
successor.left = node.left;
node.left = node.right = null;
return successor;
}
}
//根据键为相应结点设置新值
@Override
public void set(K key, V newValue) {
Node node = getNode(root, key);
if (node == null)
throw new IllegalArgumentException(key + "does't exist!");
node.value = newValue;
}
//根据键获取相应的值
@Override
public V get(K key) {
Node node = getNode(root, key);
return node == null ? null : node.value;
}
}
以上是两种实现集合的方法,LinkedListMap对于增、查、删的时间复杂度都是O(n),BSTMap对于增、查、删平均时间复杂度为O(log n)优于LinkedListMap,但对于二分搜索树最坏的情况下是退化成链表所以其时间复杂度最坏情况是O(n).下面是与前面文章Set一样的方式读取文件分析词汇比较消耗时间,下面是整个过程。
首先是文件操作工具类
public class FileOperation {
public static boolean readFile(String filename, ArrayList<String> words){
if (filename == null || words == null){
System.out.println("filename is null or words is null");
return false;
}
Scanner scanner;
try {
File file = new File(filename);
if(file.exists()){
FileInputStream fis = new FileInputStream(file);
scanner = new Scanner(new BufferedInputStream(fis), "UTF-8");
scanner.useLocale(Locale.ENGLISH);
}
else
return false;
}
catch(IOException ioe){
System.out.println("Cannot open " + filename);
return false;
}
if (scanner.hasNextLine()) {
String contents = scanner.useDelimiter("\\A").next();
int start = firstCharacterIndex(contents, 0);
for (int i = start + 1; i <= contents.length(); )
if (i == contents.length() || !Character.isLetter(contents.charAt(i))) {
String word = contents.substring(start, i).toLowerCase();
words.add(word);
start = firstCharacterIndex(contents, i);
i = start + 1;
} else
i++;
}
return true;
}
private static int firstCharacterIndex(String s, int start){
for( int i = start ; i < s.length() ; i ++ )
if( Character.isLetter(s.charAt(i)) )
return i;
return s.length();
}
}
然后是测试程序
public class Main {
private static double testMap(Map<String, Integer> map, String filename){
long startTime = System.nanoTime();
System.out.println(filename);
ArrayList<String> words = new ArrayList<>();
if(FileOperation.readFile(filename, words)) {
System.out.println("Total words: " + words.size());
for (String word : words){
if(map.contain(word))
map.set(word, map.get(word) + 1);
else
map.add(word, 1);
}
System.out.println("Total different words: " + map.getSize());
System.out.println("Frequency of PRIDE: " + map.get("pride"));
System.out.println("Frequency of PREJUDICE: " + map.get("prejudice"));
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
String filename = "pride-and-prejudice.txt";
BSTMap<String, Integer> bstMap = new BSTMap<>();
double time1 = testMap(bstMap, filename);
System.out.println("BST Map: " + time1 + " s");
System.out.println();
LinkedListMap<String, Integer> linkedListMap = new LinkedListMap<>();
double time2 = testMap(linkedListMap, filename);
System.out.println("Linked List Map: " + time2 + " s");
}
}
下面是测试结果
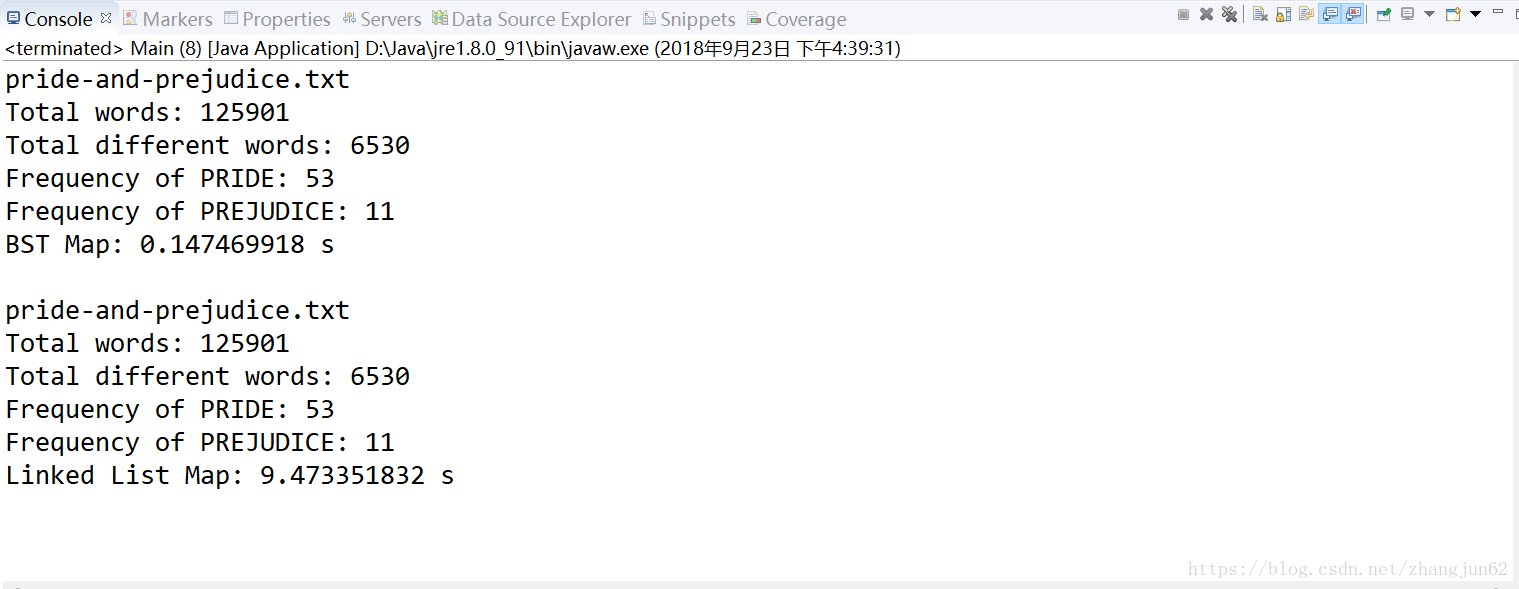
操作相同的词汇量的文本,正如预见性的一样BSTMap优于LinkedListMap,但是需要规避二分搜索树出现退化为单链表情况,所以有了后面的平衡二叉树等结构,以上整个过程实现了Map基本功能