Set也是一种重要数据结构,其特点为不允许出现重复元素,不保证集合中的元素顺序,可以有元素为null但只允许出现一次。首先定义了一个Set接口,根据前面几篇文章实现的链表和二分收索树实现Set数据结构,下面是实现过程
Set接口
public interface Set<E> {
void add(E e); //添加一个元素
void remove(E e); //删除一个元素
boolean contain(E e);//判断是否包含元素
int getSize(); //获取集合大小
boolean isEmpty(); //判断是否为空
}
1.链表实现Set,可以保证元素的顺序,主要注意避免重复元素
public class LinkedListSet<E> implements Set<E> {
private LinkedList<E> list;
public LinkedListSet(){
list = new LinkedList<>();
}
@Override
public int getSize(){
return list.getSize();
}
@Override
public boolean isEmpty(){
return list.isEmpty();
}
@Override
public void add(E e){
if(!list.contain(e)) //避免重复元素
list.addFirst(e);
}
@Override
public boolean contain(E e){
return list.contain(e);
}
@Override
public void remove(E e){
list.removeElement(e);
}
}
2.二分搜索树实现Set,可以保证元素的唯一性
public class BSTSet<E extends Comparable<E>> implements Set<E>{
private BST<E> bst;
public BSTSet() {
bst = new BST<>();
}
@Override
public void add(E e) {
bst.add(e);
}
@Override
public void remove(E e) {
bst.remove(e);
}
@Override
public boolean contain(E e) {
return bst.contain(e);
}
@Override
public int getSize() {
return bst.size();
}
@Override
public boolean isEmpty() {
return bst.isEmpty();
}
}
由于前面自己实现了链表(https://blog.csdn.net/zhangjun62/article/details/82758823)和二分搜索树(https://blog.csdn.net/zhangjun62/article/details/82766695)这两个数据结构,所以实现Set集合比较容易.对于LinkedListSet 增、查、改时间复杂度都为O(n), 对于BSTSet 增、查、改时间复杂度为O(h),其中h为树的高度,二叉树元素最多的情况是满二叉树, 满二叉树每一层元素个数为2 ^( h - 1)(h = 0, 1, 2,..., h), genj据等比数列求和可知总的元素个数n = 2 ^ h - 1, 所以h为以2底n + 1的对数,所以Bs t增、查、改时间复杂度O(h) = O(log n), 优于LinkedListSet.写了一个测试用例,比较两者耗时操作,下面是比较读取文件文本内容并统计词汇量的耗时测试程序。首先实现读取文件的工具类
public class FileOperation {
public static boolean readFile(String filename, ArrayList<String> words){
if (filename == null || words == null){
System.out.println("filename is null or words is null");
return false;
}
Scanner scanner;
try {
File file = new File(filename);
if(file.exists()){
FileInputStream fis = new FileInputStream(file);
scanner = new Scanner(new BufferedInputStream(fis), "UTF-8");
scanner.useLocale(Locale.ENGLISH);
}
else
return false;
}
catch(IOException ioe){
System.out.println("Cannot open " + filename);
return false;
}
if (scanner.hasNextLine()) {
String contents = scanner.useDelimiter("\\A").next();
int start = firstCharacterIndex(contents, 0);
for (int i = start + 1; i <= contents.length(); )
if (i == contents.length() || !Character.isLetter(contents.charAt(i))) {
String word = contents.substring(start, i).toLowerCase();
words.add(word);
start = firstCharacterIndex(contents, i);
i = start + 1;
} else
i++;
}
return true;
}
private static int firstCharacterIndex(String s, int start){
for( int i = start ; i < s.length() ; i ++ )
if( Character.isLetter(s.charAt(i)) )
return i;
return s.length();
}
}
下面是测试程序,文本是傲慢与偏见英文版
public class Main {
private static double testSet(Set<String> set, String filename) {
long startTime = System.nanoTime();
System.out.println(filename);
ArrayList<String> words = new ArrayList<>();
if (FileOperation.readFile(filename, words)) {
System.out.println("Total words: " + words.size());
for (String word : words)
set.add(word);
System.out.println("Total different words: " + set.getSize());
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
String filename = "pride-and-prejudice.txt";
BSTSet<String> bstSet = new BSTSet<>();
double time1 = testSet(bstSet, filename);
System.out.println("BST Set: " + time1 + " s");
System.out.println();
LinkedListSet<String> linkedListSet = new LinkedListSet<>();
double time2 = testSet(linkedListSet, filename);
System.out.println("Linked List Set: " + time2 + " s");
}
}
每个人电脑配置和性能不一样,时间会不同,但两者差异还是会有体现的,以下是测试结果
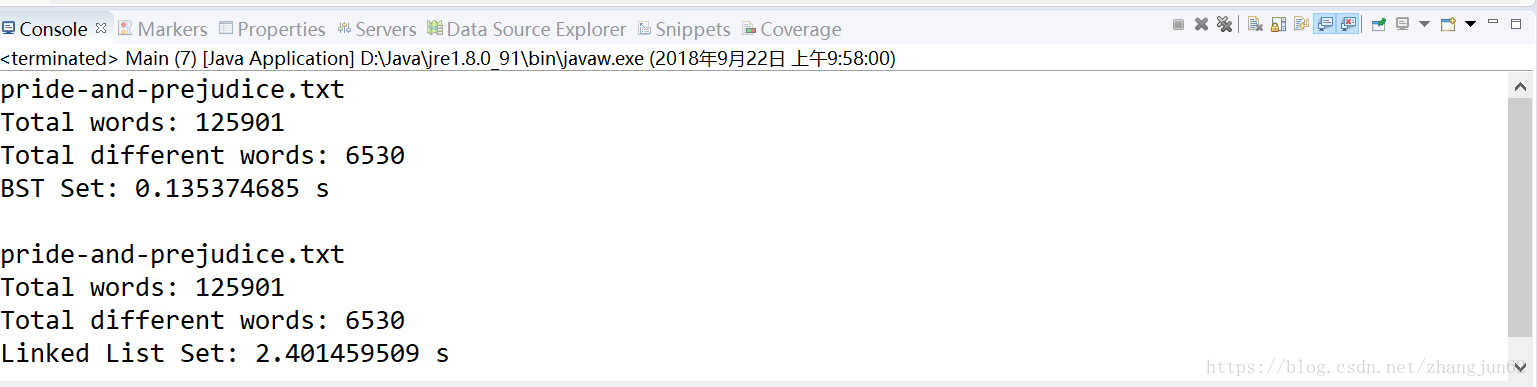
这个结果表明二分搜索树实现的Set的时间复杂度确实优于链表实现的Set,以上整个过程就实现Set基本功能。