在安装好Tensorflow models(参见我的AI之路(18)--Tensorflow的模型安装之object_detection)后,下载Object_Detection_Tensorflow_API.ipynb文件,这个文件相对于object_detection里自带的object_detection_tutorial.ipynb来说,除了对静态测试图片中的狗和人等物体的识别,后面增加了对mp4视频文件中的车、人、水果、狗等物体的识别。
我跟踪读了一下相关代码,其原理实际上是把mp4视频截取一段(起止时间在代码里指定),然后提取出视频的每个I帧图片,然后调用对静态图片中的物体识别的方法识别出模型能认识的物体并加以标记,然后把经过识别处理了的图片组合成视频输出成另一个文件,这些功能使用的moviepy来实现的,另外代码里使用到的那些mp4文件需要自己提供,github上并没有跟随源码一起提供代码里用到的那些mp4文件,需要自己提供,我自己用手机录制了个关于水果的mp4视频,另外懒得上街傻乎乎的去做街拍,随手到CNTV网站上使用了点小秘密技巧弄到了以往的央视新闻报道中有街道车流人流的短视频 (如果你对此感兴趣可以留言 ^_^ ),录制关于水果的mp4视频的I帧每秒30帧,18秒左右就有541张图片,识别代码处理起来有点工作量,执行识别代码时在我的机器上需要半个多小时。
需要注意的是需要把Object_Detection_Tensorflow_API.ipynb放到models/research下面,在我的机器上的Windows路径是D:\AI\tensorflow\models\research\Object_Detection_Tensorflow_API.ipynb,这个位置一定不能放错了,因为Object_Detection_Tensorflow_API.ipynb里代码默认的起始路径是这儿,并且在执行命令启动jupyter notebook前,也要把当前路径切换到D:\AI\tensorflow\models\research,我开始没注意这点,把Object_Detection_Tensorflow_API.ipynb放到下一级目录object_detection里去了并且在object_detection里执行命令启动jupyter notebook,结果出现了很多错误,最后面再说。
下载完Object_Detection_Tensorflow_API.ipynb放到models\research下后,还需要下载和安装一些支持包和文件:
(1)下载模型ssd_mobilenet_v1_coco_11_06_2017的压缩包解压后放到models\research\object_detection下(也可以改用其它模型,比如ssd_mobilenet_v1_coco_2017_11_17);
(2)然后安装moviepy: python -m pip install moviepy,这里要注意的是确保执行的python是anaconda下的python(我机器上安装的Anaconda3支持环境),以确保moviepy被安装到anaconda3\lib\site-packages下面(我使用的anaconda3的默认root env),如果你使用的是在Anaconda3里自己手工创建的env,那么执行安装前注意记得activate那个env,以确保安装位置正确;
(3) 手工下载ffmpeg-win32-v3.2.4.exe,并把它放到C:\Users\<user_name>\AppData\Local\imageio\ffmpeg下面(关于不同的OS上下载什么文件到什么地方,具体参见D:\Anaconda3\Lib\site-packages\imageio\plugins\ffmpeg.py中的get_exe()和D:\Anaconda3\Lib\site-packages\imageio\core\fetching.py中的get_remote_file()以及同目录下的util.py里的appdata_dir()),这是因为moviepy里依赖于ffmpeg实现视频和图片的处理功能,当执行到代码: from moviepy.editor import VideoFileClip 时,代码因为在C:\Users\<user_name>\AppData\Local\imageio\ffmpeg下找不到ffmpeg的可执行文件,所以试着去下载:
Imageio: 'ffmpeg-win32-v3.2.4.exe' was not found on your computer; downloading it now. Try 1. Download from https://github.com/imageio/imageio-binaries/raw/master/ffmpeg/ffmpeg-win32-v3.2.4.exe (34.1 MB) Downloading: 8192/35749888 bytes (0.024576/35749888 bytes (0.1%32768/35749888 bytes (0.1%49152/35749888 bytes (0.1%65536/35749888 bytes (0.2%81920/35749888 bytes (0.2%114688/35749888 bytes (0.3131072/35749888 bytes (0.4147456/35749888 bytes (0.4163840/35749888 bytes (0.5180224/35749888 bytes (0.5196608/35749888 bytes (0.5212992/35749888 bytes (0.6245760/35749888 bytes (0.7262144/35749888 bytes (0.7294912/35749888 bytes (0.8319488/35749888 bytes (0.9335872/35749888 bytes (0.9344064/35749888 bytes (1.0360448/35749888 bytes (1.0376832/35749888 bytes (1.1393216/35749888 bytes (1.1%)
但是这种下载方式超慢而且经常断掉又得重来,手工下载https://github.com/imageio/imageio-binaries/raw/master/ffmpeg/ffmpeg-win32-v3.2.4.exe很快就完了,然后把这个文件放到C:\Users\<user_name>\AppData\Local\imageio\ffmpeg下面即可。
做完了上面的准备,然后根据实际情况稍微修改一下Object_Detection_Tensorflow_API.ipynb:
# MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'

...
PATH_TO_TEST_IMAGES_DIR = 'object_detection\\test_images'
...
white_output = 'video1_fychen_out.mp4'
clip1 = VideoFileClip("video1_fychen.mp4").subclip(0,10)
...
white_output2 = 'fruits_2018_fychen_out.mp4'
clip2 = VideoFileClip("fruits_2018_fychen.mp4").subclip(0,18)
...
上面VideoFileClip()的参数就是你需要自己录制的视频的文件名,subclip()中的参数是以秒为单位,即截取视频的开始和终止时间,根据你录制的视频的长度合理设置起止时间,时间不用太长,太长处理时间很久,除非你的机器硬件配置超强悍。
后面关于cars.mp4和dogs.mp的测试以及把几个视频合并后的测试,如果你没有录制相应的文件可以把对应的代码都注释掉或者在jupyter notebook中单步执行时跳过去。
然后在命令行执行:
cd D:\AI\tensorflow\models\research
jupyter notebook
在弹出的浏览器页面中点击Object_Detection_Tensorflow_API.ipynb:

即进入notebook交互执行环境,点击run按钮一步一步往下执行代码,这样好及时发现错误。
最后执行的输出效果是:
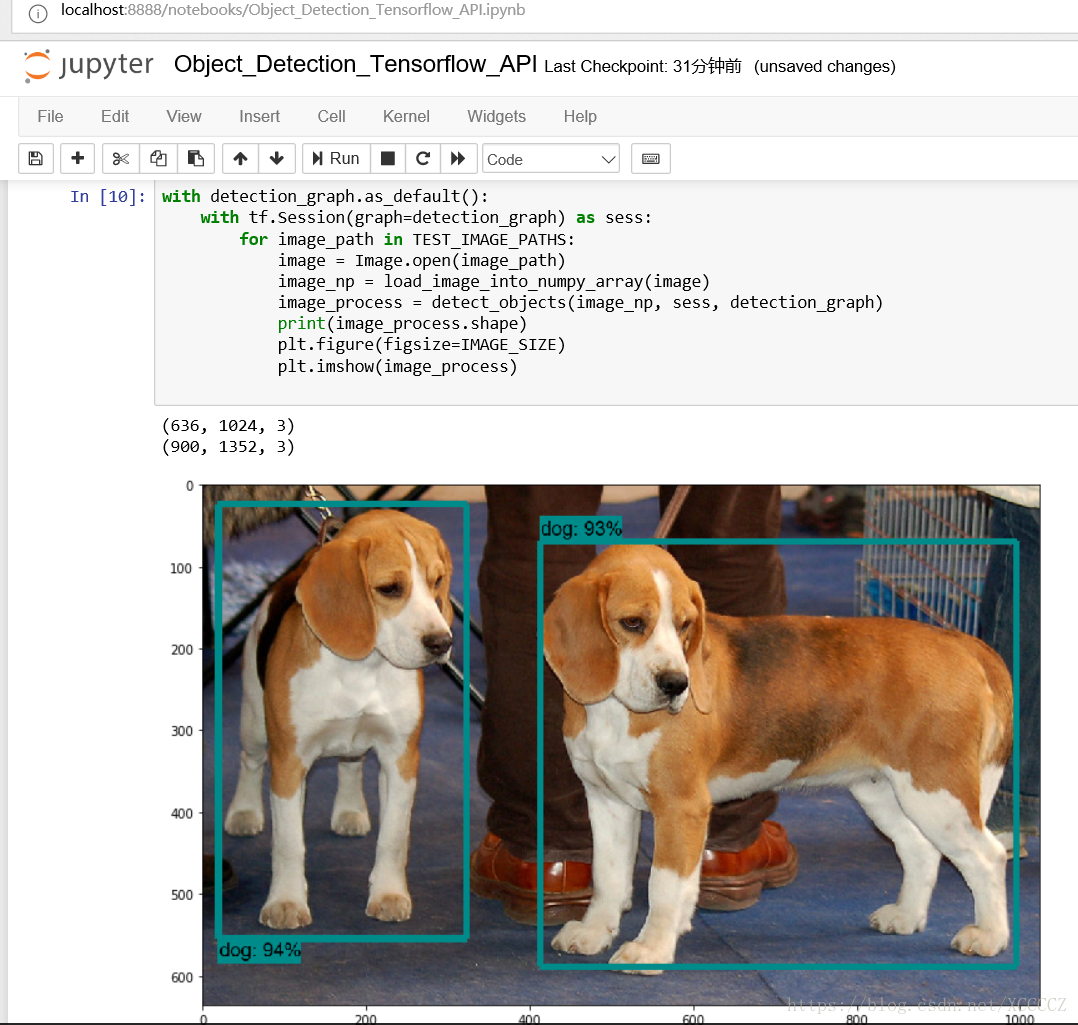
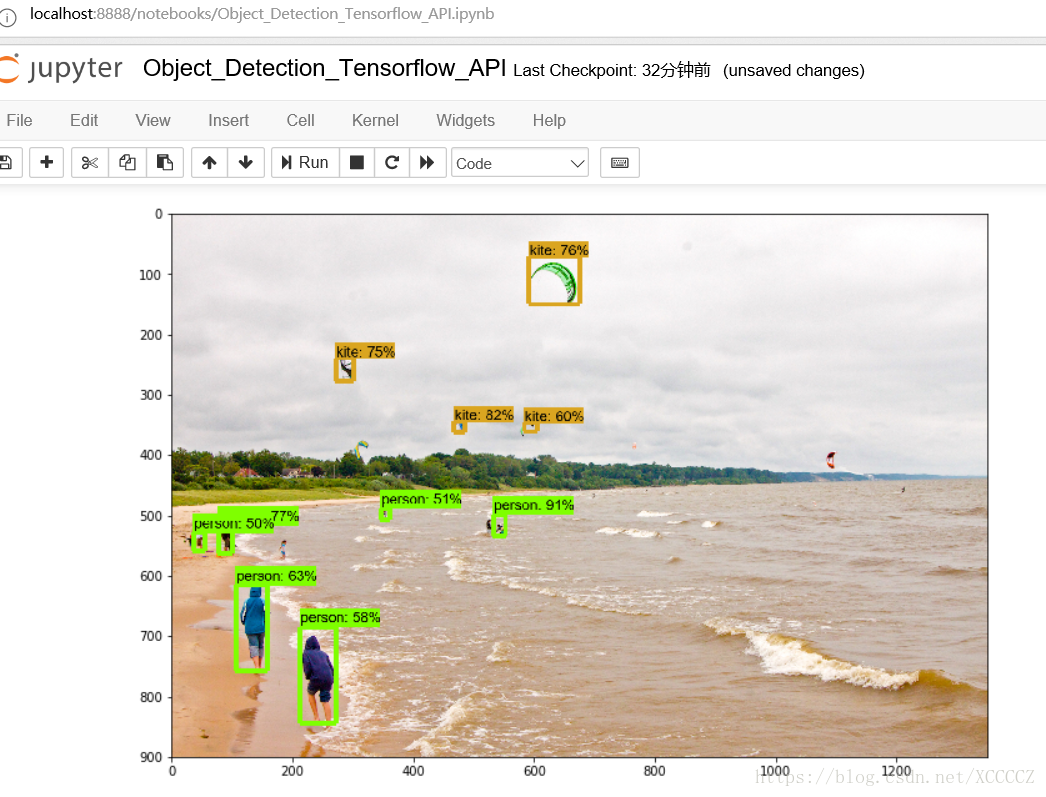
上面是静态图片中的物体识别效果,下面是视频中物体识别效果:
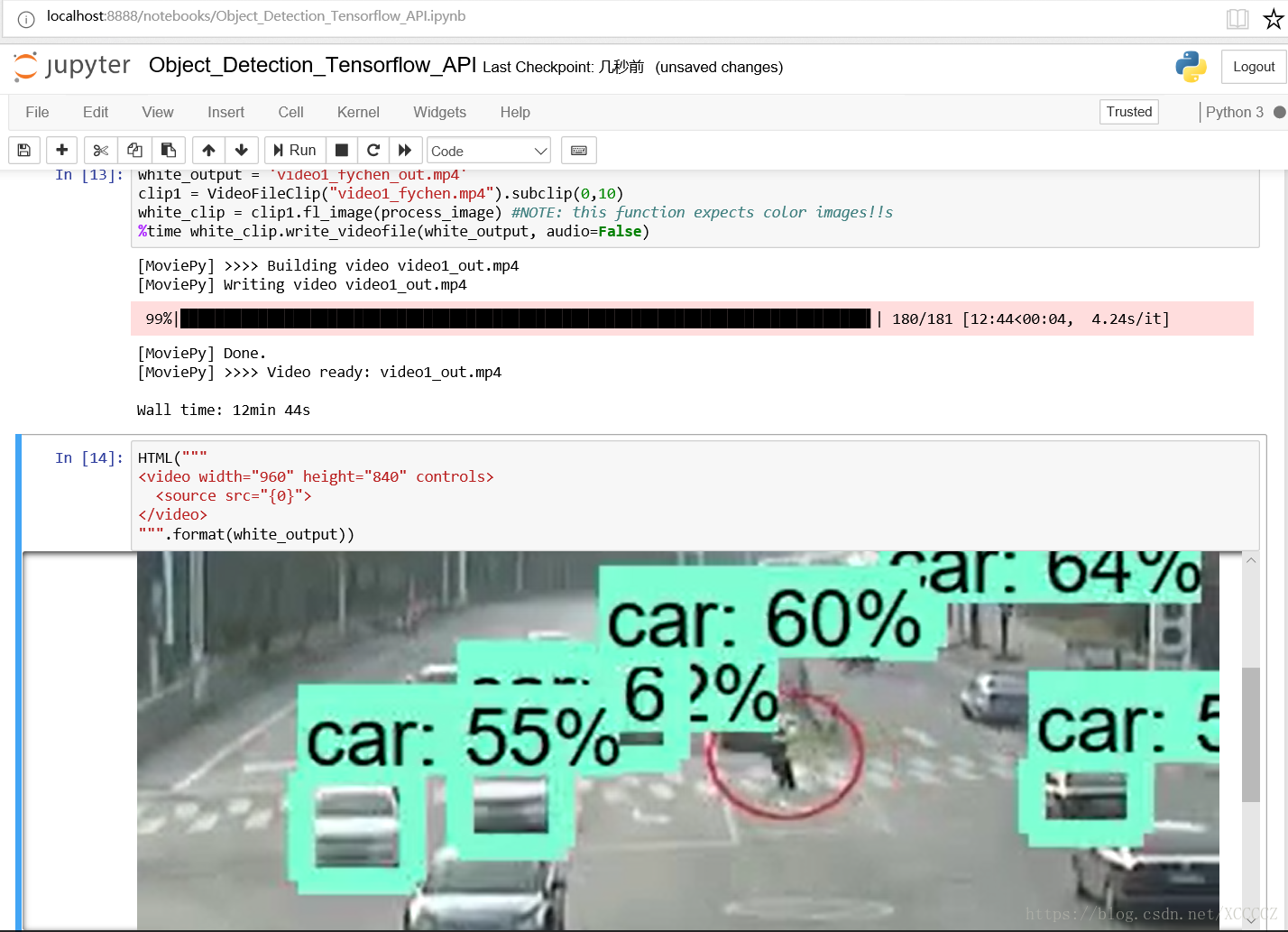
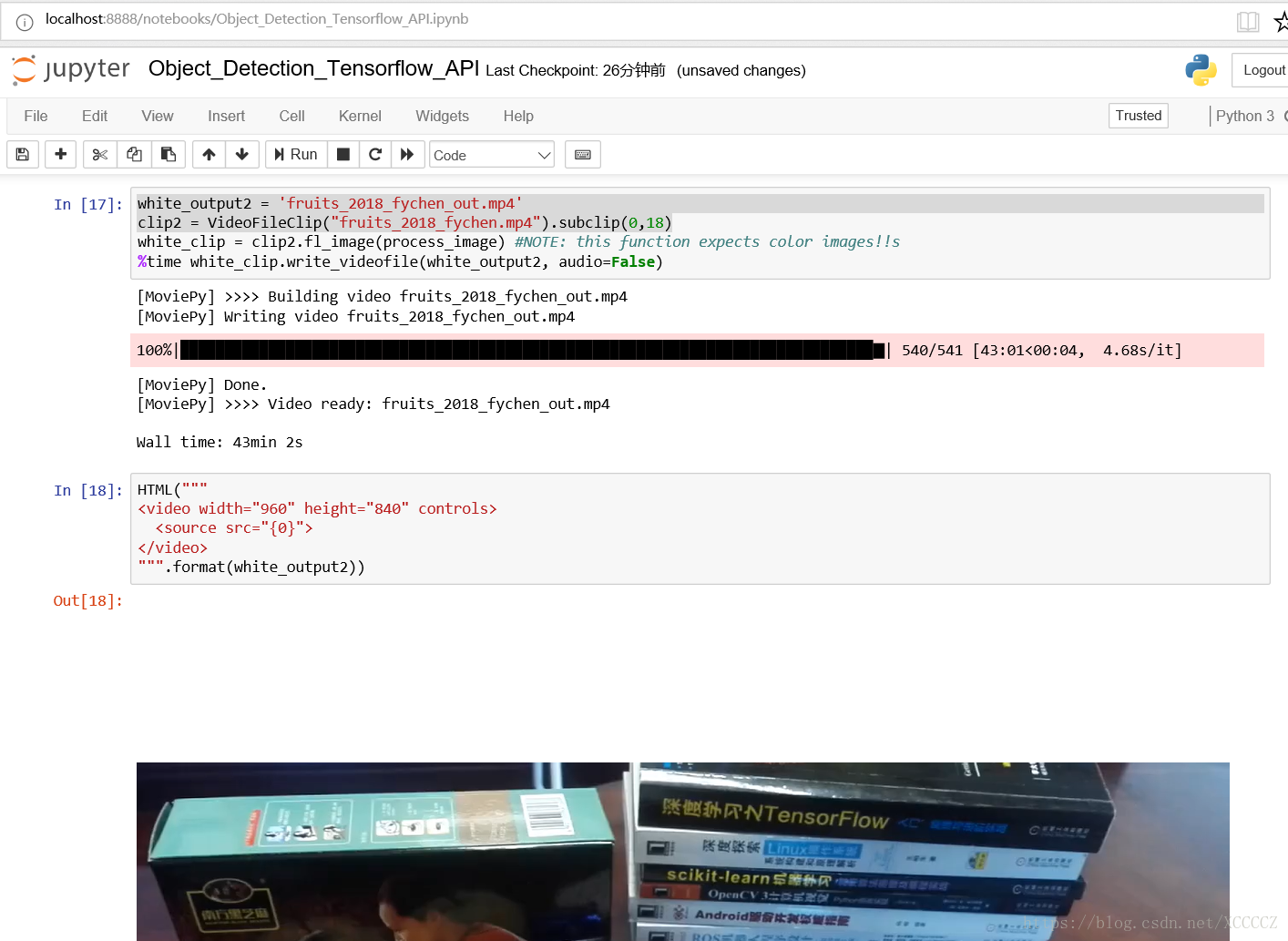
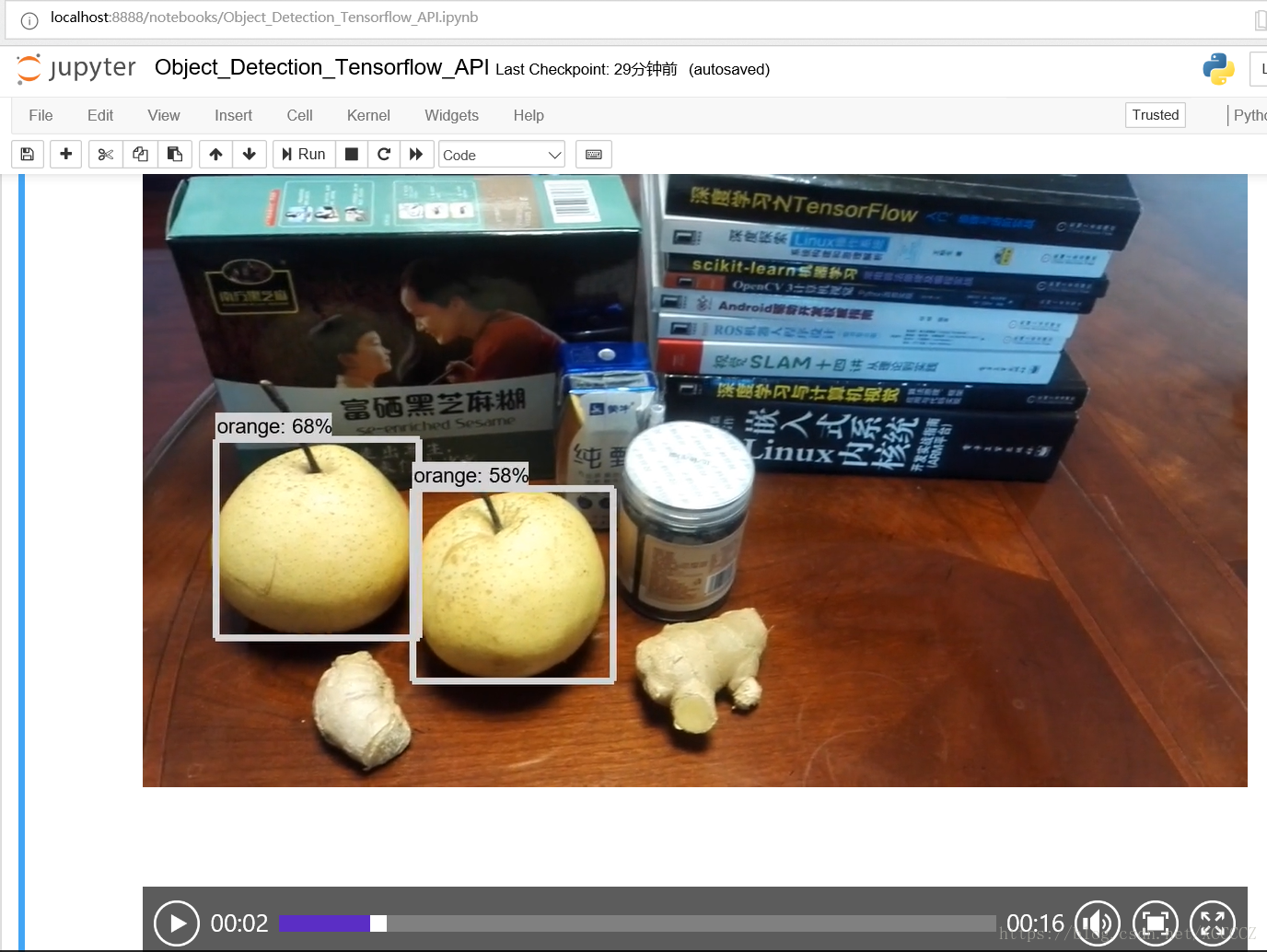
上面的视频中水果识别效果很差劲,怀疑模型训练数据中没有梨子?为啥把梨子识别成了Orange甚至是Sport Ball... 真是有点滑稽。 我把我使用的mp4视频文件和物体识别处理后输出视频文件上传到了个人下载页面可供使用和观看:
video1_fychen.zip fruits_2018_fychen.zip
如果Object_Detection_Tensorflow_API.ipynb位置放错了,会出现多种错误,首先是找不着object_detection\test_images下那些测试图片,这倒好办,修改一下代码里的路径设置即可,最头痛的是执行到函数detect_objects()的定义代码时就出现了莫名奇妙的错误:
ERROR! Session/line number was not unique in database. History logging moved to new session 23
这是ipython/ipython/blob/master/IPython/core/history.py里打出来的,大意是session在sqlite数据库里有重复,但分析代码看不出怎么造成的,按理这时还只是函数定义怎么会创建了session呢。
最让人晕倒的时,往后在执行下面的装载模型的代码时根本不报错:
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
按理,Object_Detection_Tensorflow_API.ipynb位置放错了,找不到PATH_TO_CKPT指定的模型文件frozen_inference_graph.pb应该要报错啊,居然毫无警告或错误打出来,所以导致开始没注意到是文件位置放错了。继续往下执行下面的代码:
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
image_np = load_image_into_numpy_array(image)
image_process = detect_objects(image_np, sess, detection_graph)
print(image_process.shape)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_process)
这时报错说graph里找不到image_tensor:0这个tensor,当时觉得很奇怪,模型应该没问题呀,怎么会说没有定义这个tensor呢,这个错误应该时执行到这里报的错:
def detect_objects(image_np, sess, detection_graph):
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
遇到这个错误时已是半夜了,先睡觉了 :),第二天一早起来突然想起tensor没定义是不是因为模型根本就没装载成功的原因,如果是这样,下载的模型文件应该没问题,估计是Object_Detection_Tensorflow_API.ipynb位置放错了,然后再仔细读一遍代码,果然应该是放到models\research下,而不是models\research\object_detection下,一挪动文件再重启jupyter notebook执行代码果然错误全消失了 ^_^
我的AI之路(4)--在Anaconda3 下安装Tensorflow 1.8
我的AI之路(5)--如何选择和正确安装跟Tensorflow版本对应的CUDA和cuDNN版本
我的AI之路(6)--在Anaconda3 下安装PyTorch
我的AI之路(7)--安装OpenCV3_Python 3.4.1 + Contrib以及PyCharm
我的AI之路(8)--体验用OpenCV 3的ANN进行手写数字识别及解决遇到的问题
我的AI之路(10)--如何在Linux下安装CUDA和CUDNN
我的AI之路(11)--如何解决在Linux下编译OpenCV3时出现的多个错误
我的AI之路(12)--如何配置Caffe使用GPU计算并解决编译中出现的若干错误
我的AI之路(13)--解决编译gcc/g++源码过程中出现的错误
我的AI之路(14)--Caffe example:使用MNIST数据集训练和测试LeNet-5模型
我的AI之路(15)--Linux下编译OpenCV3的最新版OpenCV3.4.1及错误解决
我的AI之路(16)--云服务器上安装和调试基于Tensorflow 1.10.1的训练环境
我的AI之路(17)--Tensorflow和Caffe的API及Guide
我的AI之路(18)--Tensorflow的模型安装之object_detection
我的AI之路(19)--如何在Windows下安装pycocotools PythonAPI
我的AI之路(20)--用Tensorflow object_detection跑raccoon数据集
我的AI之路(21)--用Tensorflow object_detection跑PASCAL VOC 2012数据集
我的AI之路(22)--使用Object_Detection_Tensorflow_API