Raccoon是一个小巧有趣的加标签了的数据集,总共200张图片,用来训练识别浣熊,我们用它来学习体验object_detection的训练测试过程是可以的。
到https://github.com/datitran/raccoon_dataset 下载zip压缩文件到本地解压到D:\AI\dataset\raccoon_dataset-master,可以看到,在images下就是图片,在annotations下面是对应的标签文件,data目录下是作者生成好的tensorflow支持的tfrecord格式的数据文件(*.record)和caffe等支持的csv格式的数据文件(*.csv),training目录下则是作者改写好的针对ssd_mobilenet_v1网络模型的配置文件(ssd_mobilenet_v1_pets.config)和识别类别ID和名称的配置文件(object-detection.pbtxt)以及作者训练出的模型文件(output_inference_graph.pb),这里我们自己做ssd网络配置和生成tfrecord数据,不直接使用作者的文件,以体验配置->训练->测试的全过程。
首先把200张图片划分成训练集和测试集,使用下面的脚本生成全体文件的名字列表写入文件file_list.txt:
import os
fd=r"D:\AI\dataset\raccoon_dataset-master\images"
image_name=os.listdir(fd)
f = open("file_list.txt", "w")
for temp in image_name:
if temp.endswith(".jpg"):
f.write(temp.replace('.jpg','\n'))
f.close()
然后,把列表按照 80%:20% 的一般划分规矩分成两部分分成两个文件保存:train.txt和eval.txt,分别用作训练和测试,
train.txt内容 :
raccoon-194
raccoon-101
raccoon-4
raccoon-105
raccoon-97
raccoon-113
raccoon-48
raccoon-108
raccoon-156
raccoon-55
raccoon-161
raccoon-2
raccoon-59
raccoon-18
raccoon-41
raccoon-126
raccoon-79
raccoon-23
raccoon-92
raccoon-58
raccoon-153
raccoon-165
raccoon-182
raccoon-122
raccoon-95
raccoon-86
raccoon-6
raccoon-99
raccoon-46
raccoon-130
raccoon-167
raccoon-186
raccoon-183
raccoon-177
raccoon-170
raccoon-179
raccoon-73
raccoon-82
raccoon-5
raccoon-10
raccoon-94
raccoon-30
raccoon-67
raccoon-85
raccoon-87
raccoon-112
raccoon-174
raccoon-196
raccoon-134
raccoon-133
raccoon-148
raccoon-13
raccoon-89
raccoon-16
raccoon-128
raccoon-150
raccoon-106
raccoon-120
raccoon-144
raccoon-137
raccoon-12
raccoon-140
raccoon-21
raccoon-141
raccoon-107
raccoon-47
raccoon-29
raccoon-115
raccoon-25
raccoon-124
raccoon-3
raccoon-1
raccoon-131
raccoon-50
raccoon-103
raccoon-80
raccoon-71
raccoon-42
raccoon-142
raccoon-176
raccoon-149
raccoon-33
raccoon-132
raccoon-118
raccoon-26
raccoon-65
raccoon-43
raccoon-200
raccoon-135
raccoon-154
raccoon-93
raccoon-22
raccoon-36
raccoon-69
raccoon-96
raccoon-114
raccoon-181
raccoon-84
raccoon-193
raccoon-68
raccoon-192
raccoon-70
raccoon-74
raccoon-88
raccoon-8
raccoon-34
raccoon-139
raccoon-91
raccoon-109
raccoon-27
raccoon-54
raccoon-52
raccoon-185
raccoon-136
raccoon-61
raccoon-127
raccoon-98
raccoon-155
raccoon-75
raccoon-28
raccoon-173
raccoon-57
raccoon-56
raccoon-187
raccoon-160
raccoon-35
raccoon-151
raccoon-175
raccoon-129
raccoon-20
raccoon-116
raccoon-66
raccoon-37
raccoon-180
raccoon-143
raccoon-40
raccoon-76
raccoon-111
raccoon-64
raccoon-24
raccoon-60
raccoon-168
raccoon-17
raccoon-32
raccoon-147
raccoon-117
raccoon-172
raccoon-189
raccoon-45
raccoon-81
raccoon-7
raccoon-63
raccoon-110
raccoon-198
raccoon-100
raccoon-39
raccoon-9
raccoon-19
raccoon-195
raccoon-197
eval.txt内容:
raccoon-138
raccoon-90
raccoon-44
raccoon-152
raccoon-162
raccoon-190
raccoon-191
raccoon-51
raccoon-62
raccoon-102
raccoon-119
raccoon-178
raccoon-49
raccoon-184
raccoon-72
raccoon-157
raccoon-14
raccoon-163
raccoon-53
raccoon-188
raccoon-104
raccoon-169
raccoon-146
raccoon-164
raccoon-31
raccoon-166
raccoon-171
raccoon-78
raccoon-77
raccoon-145
raccoon-199
raccoon-123
raccoon-11
raccoon-83
raccoon-158
raccoon-125
raccoon-15
raccoon-159
raccoon-38
raccoon-121
然后,把training目录下的object-detection.pbtxt文件拷贝到上层目录D:\AI\dataset\raccoon_dataset-master下,改名为raccoon_label_map.pbtxt即可,这个文件我们可以直接使用作者的。
从D:\AI\tensorflow\models\research\object_detection\dataset_tools目录下找到create_pascal_tf_record.py拷贝并复制一个文件,将复制文件改名文件为create_pascal_tf_record4raccon.py,并根据数据集的文件路径和命令执行参数修改内容如下:
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Convert raw PASCAL dataset to TFRecord for object_detection.
Example usage:
python object_detection\dataset_tools\create_pascal_tf_record4raccon.py ^
--data_dir=D:\AI\dataset\raccoon_dataset-master\images ^
--set=D:\AI\dataset\raccoon_dataset-master\train.txt ^
--output_path=D:\AI\dataset\raccoon_dataset-master\train.record ^
--label_map_path=D:\AI\dataset\raccoon_dataset-master\raccoon_label_map.pbtxt ^
--annotations_dir=D:\AI\dataset\raccoon_dataset-master\annotations
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import hashlib
import io
import logging
import os
from lxml import etree
import PIL.Image
import tensorflow as tf
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '', 'Root directory to raw PASCAL VOC dataset.')
flags.DEFINE_string('set', 'train', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('annotations_dir', 'Annotations',
'(Relative) path to annotations directory.')
flags.DEFINE_string('year', 'VOC2007', 'Desired challenge year.')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_string('label_map_path', 'data/pascal_label_map.pbtxt',
'Path to label map proto')
flags.DEFINE_boolean('ignore_difficult_instances', False, 'Whether to ignore '
'difficult instances')
FLAGS = flags.FLAGS
SETS = ['train', 'val', 'trainval', 'test']
YEARS = ['VOC2007', 'VOC2012', 'merged']
def dict_to_tf_example(data,
dataset_directory,
label_map_dict,
ignore_difficult_instances=False,
image_subdirectory='JPEGImages'):
"""Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
dataset_directory: Path to root directory holding PASCAL dataset
label_map_dict: A map from string label names to integers ids.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
image_subdirectory: String specifying subdirectory within the
PASCAL dataset directory holding the actual image data.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
img_path = os.path.join(dataset_directory, data['filename'].replace('.png','.jpg').replace('.PNG','.jpg'))
full_path = img_path
with tf.gfile.GFile(full_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'JPEG':
raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
width = int(data['size']['width'])
height = int(data['size']['height'])
xmin = []
ymin = []
xmax = []
ymax = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
if 'object' in data:
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
xmin.append(float(obj['bndbox']['xmin']) / width)
ymin.append(float(obj['bndbox']['ymin']) / height)
xmax.append(float(obj['bndbox']['xmax']) / width)
ymax.append(float(obj['bndbox']['ymax']) / height)
classes_text.append(obj['name'].encode('utf8'))
classes.append(label_map_dict[obj['name']])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}))
return example
def main(_):
#if FLAGS.set not in SETS:
# raise ValueError('set must be in : {}'.format(SETS))
#if FLAGS.year not in YEARS:
# raise ValueError('year must be in : {}'.format(YEARS))
data_dir = FLAGS.data_dir
years = ['VOC2007', 'VOC2012']
if FLAGS.year != 'merged':
years = [FLAGS.year]
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
for year in years:
logging.info('Reading from PASCAL %s dataset.', year)
examples_path = FLAGS.set
# 'aeroplane_' + FLAGS.set + '.txt')
annotations_dir = FLAGS.annotations_dir
examples_list = dataset_util.read_examples_list(examples_path)
for idx, example in enumerate(examples_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(examples_list))
path = os.path.join(annotations_dir, example + '.xml')
with tf.gfile.GFile(path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
tf_example = dict_to_tf_example(data, FLAGS.data_dir, label_map_dict,
FLAGS.ignore_difficult_instances)
writer.write(tf_example.SerializeToString())
writer.close()
if __name__ == '__main__':
tf.app.run()
对照原来的create_pascal_tf_record.py,你会发现主要是修改了图片文件的获取路径和名字以及命令执行参数set,因为原来的代码中写的跟数据集实际情况不符。
做好了上面的准备,下面可以执行命令生成tfrecord格式的训练和测试/验证数据了,执行下面命令生成训练数据文件train.record:
cd D:\AI\tensorflow\models\research
python object_detection\dataset_tools\create_pascal_tf_record4raccon.py ^
--data_dir=D:\AI\dataset\raccoon_dataset-master\images ^
--set=D:\AI\dataset\raccoon_dataset-master\train.txt ^
--output_path=D:\AI\dataset\raccoon_dataset-master\train.record ^
--label_map_path=D:\AI\dataset\raccoon_dataset-master\raccoon_label_map.pbtxt ^
--annotations_dir=D:\AI\dataset\raccoon_dataset-master\annotations
执行下面命令生成测试/验证数据文件eval.record:
python object_detection\dataset_tools\create_pascal_tf_record4raccon.py ^
--data_dir=D:\AI\dataset\raccoon_dataset-master\images ^
--set=D:\AI\dataset\raccoon_dataset-master\val.txt ^
--output_path=D:\AI\dataset\raccoon_dataset-master\eval.record ^
--label_map_path=D:\AI\dataset\raccoon_dataset-master\raccoon_label_map.pbtxt ^
--annotations_dir=D:\AI\dataset\raccoon_dataset-master\annotations
如果执行上面第一个命令时出现下面的错误:

这说明你忘了设置PYTHONPATH环境变量,最好把这个环境变量设置到系统的用户环境变量里去(linux下当然设置到.bashrc里):
临时设置的话,执行下面命令即可:
set PYTHONPATH=D:\AI\tensorflow\models\research;D:\AI\tensorflow\models\research\slim
每次执行命令时最后打印输出 if not xml:,这是正常输出:


执行完上面的pascal voc转化成tfrecord数据的命令后,D:\AI\dataset\raccoon_dataset-master\eval.record下面可以看到train.record和eval.record生成了。
下面下载ssd_mobilenet_v1 网络模型文件ssd_mobilenet_v1_coco ,解压到D:\AI\tensorflow\models\research\object_detection下面:

然后,把D:\AI\tensorflow\models\research\object_detection\samples\configs下的ssd_mobilenet_v1_coco.config 复制到 D:\AI\dataset\raccoon_dataset-master下,重命名为ssd_mobilenet_v1_raccoon.config,并修改如下以指定网络模型文件和数据文件以及指定类别数等:
# SSD with Mobilenet v1 configuration for MSCOCO Dataset.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
num_classes: 1
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v1'
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid {
}
}
localization_loss {
weighted_smooth_l1 {
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 0
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 24
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
fine_tune_checkpoint: "D:\\AI\\tensorflow\\models\\research\\object_detection\\ssd_mobilenet_v1_coco_2017_11_17\\model.ckpt"
from_detection_checkpoint: true
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 200000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "D:\\AI\\dataset\\raccoon_dataset-master\\train.record"
}
label_map_path: "D:\\AI\\dataset\\raccoon_dataset-master\\raccoon_label_map.pbtxt"
}
eval_config: {
num_examples: 40
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "D:\\AI\\dataset\\raccoon_dataset-master\\eval.record"
}
label_map_path: "D:\\AI\\dataset\\raccoon_dataset-master\\raccoon_label_map.pbtxt"
shuffle: false
num_readers: 1
}
model_main.py默认并没有打开tensorflow日志,所以需要在初始化部分加一句:
tf.logging.set_verbosity(tf.logging.INFO)
另外,如果你使用的笔记本只有一块内存不大的GPU的话,可能会出现GPU内存溢出(run out of memory)的情况导致后面计算出错(Model diverged with loss = NaN)进行不下去:
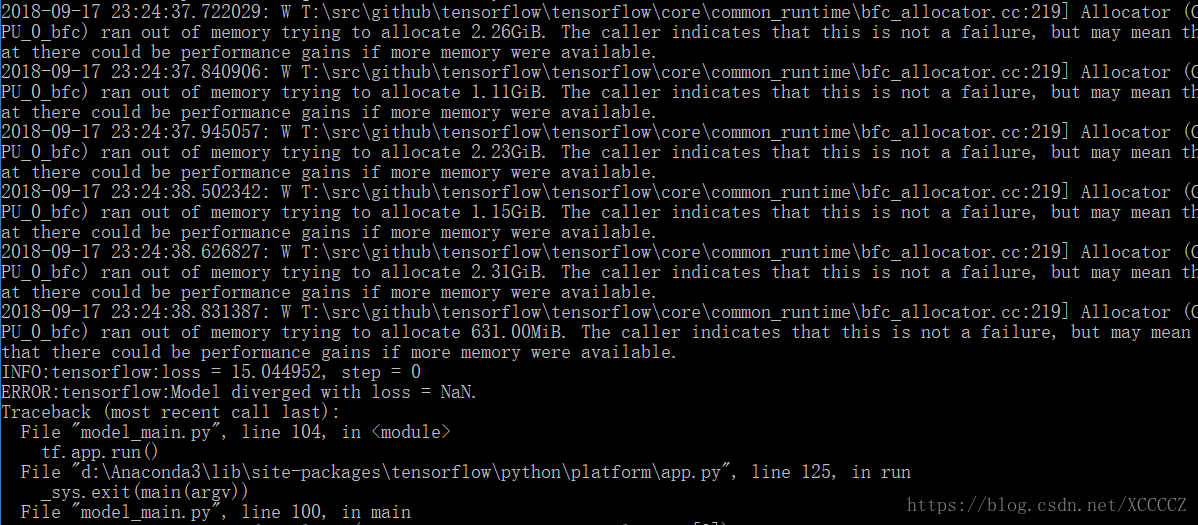
这时可以在model_main.py的main()函数里限制GPU的使用率:
from tensorflow.core.protobuf import config_pb2
gpu_options= config_pb2.GPUOptions(per_process_gpu_memory_fraction=0.5)
session_config = config_pb2.ConfigProto(log_device_placement=True,gpu_options=gpu_options)
config = tf.estimator.RunConfig(model_dir=FLAGS.model_dir,session_config=session_config)
或者可以禁止GPU的使用(当然会变慢点),在model_main.py的初始化部分增加:
import os
os.environ['CUDA_VISIBLE_DEVICES']='-1'
然后,在D:\AI\dataset\raccoon_dataset-master下创建train_result和eval_result两个目录,然后执行下面的命令进行训练和测试/验证:
python model_main.py ^
--logtostderr ^
--model_dir=D:\AI\dataset\raccoon_dataset-master\train_result ^
--pipeline_config_path=D:\AI\dataset\raccoon_dataset-master\ssd_mobilenet_v1_racoon.config ^
--num_train_steps=10000
python model_main.py ^
--logtostderr ^
--model_dir=D:\AI\dataset\raccoon_dataset-master\eval_result ^
--checkpoint_dir=D:\AI\dataset\raccoon_dataset-master\train_result ^
--pipeline_config_path=D:\AI\dataset\raccoon_dataset-master\ssd_mobilenet_v1_racoon.config ^
--num_eval_steps=1000
训练过程中另外打开一个cmd窗口,执行
tensorboard --logdir=D:\AI\dataset\raccoon_dataset-master\train_result
然后在输出日志中找到TB的监听端口:
TensorBoard 1.10.0 at http://fychen-T470P:6006 (Press CTRL+C to quit)
然后在Chrome浏览器(不支持IE哦)中输入http://fychen-T470P:6006即可实时监视训练情况。
如果训练一段时间后最终还是发生OOM错误导致训练终止:


说明笔记本2G的GPU是实在不够跑这个训练的,需要转到GPU内存大的PC服务器上去做。
我的AI之路(4)--在Anaconda3 下安装Tensorflow 1.8
我的AI之路(5)--如何选择和正确安装跟Tensorflow版本对应的CUDA和cuDNN版本
我的AI之路(6)--在Anaconda3 下安装PyTorch
我的AI之路(7)--安装OpenCV3_Python 3.4.1 + Contrib以及PyCharm
我的AI之路(8)--体验用OpenCV 3的ANN进行手写数字识别及解决遇到的问题
我的AI之路(10)--如何在Linux下安装CUDA和CUDNN
我的AI之路(11)--如何解决在Linux下编译OpenCV3时出现的多个错误
我的AI之路(12)--如何配置Caffe使用GPU计算并解决编译中出现的若干错误
我的AI之路(13)--解决编译gcc/g++源码过程中出现的错误
我的AI之路(14)--Caffe example:使用MNIST数据集训练和测试LeNet-5模型
我的AI之路(15)--Linux下编译OpenCV3的最新版OpenCV3.4.1及错误解决
我的AI之路(16)--云服务器上安装和调试基于Tensorflow 1.10.1的训练环境
我的AI之路(17)--Tensorflow和Caffe的API及Guide
我的AI之路(18)--Tensorflow的模型安装之object_detection