架构
Apache Flink是一个用于对无边界和有边界数据流进行有状态计算的框架和分布式处理引擎。Flink设计为运行在所有常见的集群环境中,并且以内存速度和任何规模执行计算。
在这里,我们解释Flink架构的相关重要内容。
处理无边界和有边界数据
任何类型的数据都是作为事件流产生的。信用卡交易事务,传感器测量,机器日志以及网站或移动应用程序上的用户交互行为,所有这些数据都生成流。
数据可以作为无边界或有边界流处理。
- 无边界流定义了开始但没有定义结束。它们不会在生成时终止提供数据。必须持续地处理无边界流,即必须在拉取到事件后立即处理它。无法等待所有输入数据到达后处理,因为输入是无边界的,并且在任何时间点都不会完成。处理无边界数据通常要求以特定顺序(例如事件发生的顺序)拉取事件,以便能够推断结果完整性。
- 有边界流定义了开始和结束。可以在执行任何计算之前通过拉取到所有数据后处理有界流。处理有界流不需要有序拉取,因为可以随时对有界数据集进行排序。有边界流的处理也称为批处理。
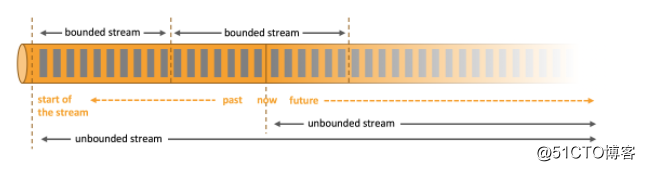
Apache Flink擅长处理无边界和有边界数据集。在事件和状态上的精确控制使得Flink运行时能在无边界流上运行任意类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而获得优秀的性能。随处部署应用程序
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以作为独立集群运行。
Flink旨在很好地适用于之前列出的每个资源管理器。这是通过特定于资源管理器的部署模式实现的,这些模式允许Flink以其惯用的方式与每个资源管理器进行交互。
部署Flink应用程序时,Flink会根据应用程序配置的并行度自动识别所需资源,并从资源管理器请求它们。如果发生故障,Flink会通过请求新的资源来替换发生故障的容器。提交或控制应用程序的所有通信都通过REST调用进行。这简化了Flink在许多环境中的集成。任意规模运行应用程序
Flink旨在以任意规模运行有状态流式应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,内存,磁盘和网络IO。而且,Flink可以轻松维护非常大的应用程序的状态。其异步和增量检查点算法确保对延迟处理的影响最小,同时保证精确一次的状态一致性。
用户报告了在其生产环境中运行的Flink应用程序的扩展数字令人印象十分深刻,例如:- 应用程序每天处理数万亿个事件
- 应用程序维护数个TB的状态
- 应用程序在数千个CPU核上运行
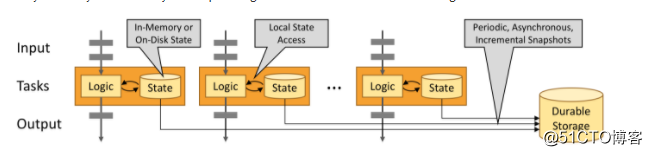
利用内存的性能
有状态的Flink应用程序针对本地状态访问进行了优化。任务状态始终驻留在内存中,或者,如果状态大小超过可用内存,则保存在访问高效的磁盘上的数据结构中。因此,任务通过访问本地(通常是内存中)状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期和异步检查点将本地状态到持久存储来保证在出现故障时的精确一次的状态一致性。