第一部分 概览
2. 教程
本章针对Calcite的连接建立提供了循序渐进的教程,使用一个简单的适配器来将一个CSV文件目录以包含Schema信息的tables形式呈现,并提供了一个完全SQL接口。
Calcite-example-CSV是一个Calcite中的一个功能完备的适配器,它可以读取CSV格式(以逗号分隔)的文本文件。值得称赞的是,几百行的java代码就足够提供完全的SQL查询功能。
CSV适配器同样作为一个其他数据格式的适配器构建参考模板。尽管代码量不大,但它覆盖了一些重要的概念:
1) 用户通过使用SchemaFactory和Schema interfaces来自定义schema
2) 以JSON模型文件声明schemas
3) 以JSON模型文件声明视图views
4) 通过Table interface自定义table
5) 定义table的record类型
6) 使用Scannable Table interface作为Table的简单实现,来直接枚举所有的rows
7) 进阶实现FilterableTable,来根据简单的谓词predicates过滤rows
8) 以Translatable Table进阶实现Table,将关系型算子翻译为执行计划规则
2.1 源码搭建
版本依赖:Java (1.7 or higher; 1.8 preferred), git and maven (3.2.1 or later).
$ git clone https://github.com/apache/calcite.git
$ cd calcite
$ mvn install -DskipTests -Dcheckstyle.skip=true
$ cd example/csv2.2 查询测试
可以通过工程内置的sqlline脚本来连接到Calcite
$ ./sqlline
sqlline> !connect jdbc:calcite:model=target/test-classes/model.json admin admin(如果使用Windows操作系统,命令为sqlline.bat)
执行一个metadata 查询
sqlline> !tables
+------------+--------------+-------------+---------------+----------+------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE |
+------------+--------------+-------------+---------------+----------+------+
| null | SALES | DEPTS | TABLE | null | null |
| null | SALES | EMPS | TABLE | null | null |
| null | SALES | HOBBIES | TABLE | null | null |
| null | metadata | COLUMNS | SYSTEM_TABLE | null | null |
| null | metadata | TABLES | SYSTEM_TABLE | null | null |
+------------+--------------+-------------+---------------+----------+------+ JDBC提示:sqlline中的 !tables 命令实际上等于执行 DatabaseMetaData.getTables() , 还有其他命令来查询JDBC metadata, 例如 !columns 和 !describe。

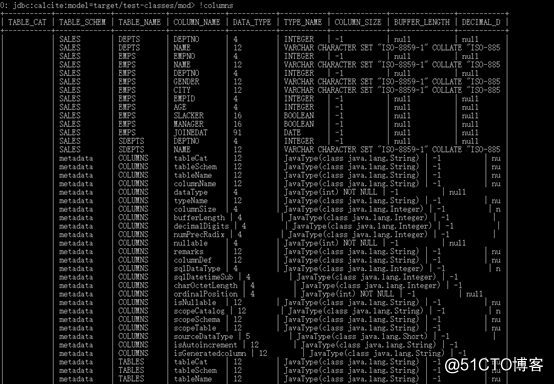
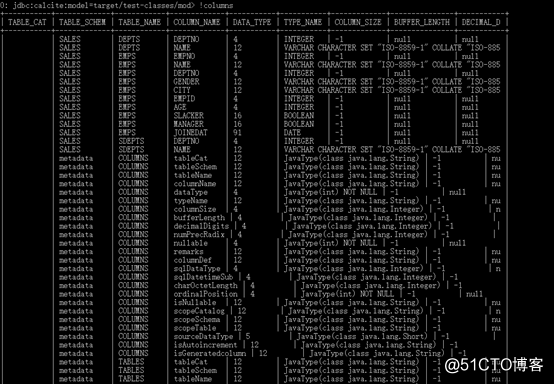

如结果所示,该系统中共有5个table: SALES schema下的EMPS, DEPTS, HOBBIES 和系统自带的 metadata schema下的COLUMNS和TABLES。系统table在Calcite中会一直展示,但其他表是由schema的指定实现而来,在本例中,EMPS和DEPTS表来源于target/test-classes路径下的EMPS.csv和DEPTS.csv文件。
通过在这些表上执行一些查询,我们可以验证Calcite提供了完整的SQL功能实现。
首先,scan table:
sqlline> SELECT * FROM emps;
+--------+--------+---------+---------+----------------+--------+-------+---+
| EMPNO | NAME | DEPTNO | GENDER | CITY | EMPID | AGE | S |
+--------+--------+---------+---------+----------------+--------+-------+---+
| 100 | Fred | 10 | | | 30 | 25 | t |
| 110 | Eric | 20 | M | San Francisco | 3 | 80 | n |
| 110 | John | 40 | M | Vancouver | 2 | null | f |
| 120 | Wilma | 20 | F | | 1 | 5 | n |
| 130 | Alice | 40 | F | Vancouver | 2 | null | f |
+--------+--------+---------+---------+----------------+--------+-------+---+
同时支持JOIN和GROUP BY
sqlline> SELECT d.name, COUNT(*)
. . . .> FROM emps AS e JOIN depts AS d ON e.deptno = d.deptno
. . . .> GROUP BY d.name;
+------------+---------+
| NAME | EXPR$1 |
+------------+---------+
| Sales | 1 |
| Marketing | 2 |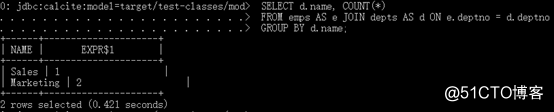
最后,VALUES操作符可以聚合生成单独一行数据,我们可以通过这种简便的方法来测试表达式和SQL内嵌函数:
sqlline> VALUES CHAR_LENGTH('Hello, ' || 'world!');
+---------+
| EXPR$0 |
+---------+
| 13 |
+---------+
Calcite具有其他许多SQL特性。我们来不及在这里一一举例,使用者可以编写更多的查询来进行验证。
2.3 Schema发现
现在,我们来探索一下Calcite是如何发现这些table的。记住,最核心的Calcite不知道CSV文件的任何信息。(像一个“没有存储层的databse”一样,Calcite不会去了解任何文件格式)Calcite能识别这些table是因为我们告诉它去运行calcite-example-csv工程下的代码。
运行链中有一系列的步骤。首先,我们在一个schema 工程类中以model file的格式定义一个schema。然后schema工厂类创建一个schema,schema创建多个table,这些table都知道如何通过scan CSV文件来获取数据。最后,在Calcite解析完查询并将查询计划映射到这几个table上时,Calcite会在查询执行时触发这些table去读取数据。接下来我们更深入地解析其中的细节步骤。
在JDBC连接字符串中,我们会给出以JSON格式定义的model的路径。model具体定义如下
{
version: '1.0',
defaultSchema: 'SALES',
schemas: [
{
name: 'SALES',
type: 'custom',
factory: 'org.apache.calcite.adapter.csv.CsvSchemaFactory',
operand: {
directory: 'target/test-classes/sales'
}
}
]
}
这个model定义了一个名为SALES的schema。这个schema是由一个plugin类支持的,org.apache.calcite.adapter.csv.CsvSchemaFactory,这个类是calcite-example-csv工程里的一部分并且实现了Calcite中的SchemaFactory接口。它的create方法将一个schema实例化了,将model file中的directory参数传递过去了。
public Schema create(SchemaPlus parentSchema, String name,
Map<String, Object> operand) {
String directory = (String) operand.get("directory");
String flavorName = (String) operand.get("flavor");
CsvTable.Flavor flavor;
if (flavorName == null) {
flavor = CsvTable.Flavor.SCANNABLE;
} else {
flavor = CsvTable.Flavor.valueOf(flavorName.toUpperCase());
}
return new CsvSchema(new File(directory), flavor);
} 根据model的配置,这个schema 工程类实例化了一个名为SALES的schema。这个schema是org.apache.calcite.adapter.csv.CsvSchema的一个实例,实现了Calcite中的Schema接口。
一个schema的职责是产生一系列的tables(它也可以列举出子schema和table-function,但这些高级的特性在calcite-example-csv中没有支持)。这些table实现了Calcite的Table接口。CsvSchema生成了一些tables,它们是CsvTable以及CsvTable的子类的实例。
下面是CsvSchema的一些相关代码,对基类AbstractSchema中的getTableMap()方法进行了重载。
protected Map<String, Table> getTableMap() {
// Look for files in the directory ending in ".csv", ".csv.gz", ".json",".json.gz".
File[] files = directoryFile.listFiles(
new FilenameFilter() {
public boolean accept(File dir, String name) {
final String nameSansGz = trim(name, ".gz");
return nameSansGz.endsWith(".csv")|| nameSansGz.endsWith(".json");
}
});
if (files == null) {
System.out.println("directory " + directoryFile + " not found");
files = new File[0];
}
// Build a map from table name to table; each file becomes a table.
final ImmutableMap.Builder<String, Table> builder = ImmutableMap.builder();
for (File file : files) {
String tableName = trim(file.getName(), ".gz");
final String tableNameSansJson = trimOrNull(tableName, ".json");
if (tableNameSansJson != null) {
JsonTable table = new JsonTable(file);
builder.put(tableNameSansJson, table);
continue;
}
tableName = trim(tableName, ".csv");
final Table table = createTable(file);
builder.put(tableName, table);
}
return builder.build();
}
/** Creates different sub-type of table based on the "flavor" attribute. */
private Table createTable(File file) {
switch (flavor) {
case TRANSLATABLE:
return new CsvTranslatableTable(file, null);
case SCANNABLE:
return new CsvScannableTable(file, null);
case FILTERABLE:
return new CsvFilterableTable(file, null);
default:
throw new AssertionError("Unknown flavor " + flavor);
}
}schema会扫描指定路径,找到所有以".csv”结尾的文件。在本例中,指定路径是 target/test-classes/sales,路径中包含文件EMPS.csv和DEPTS.csv,这两个文件会转换成EMPS和DEPTS表。