
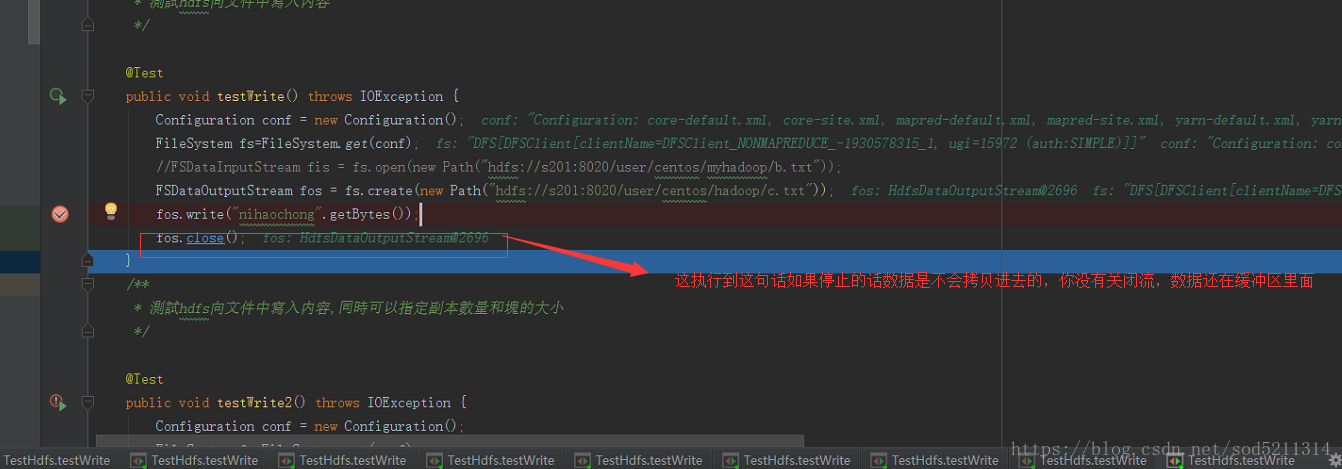
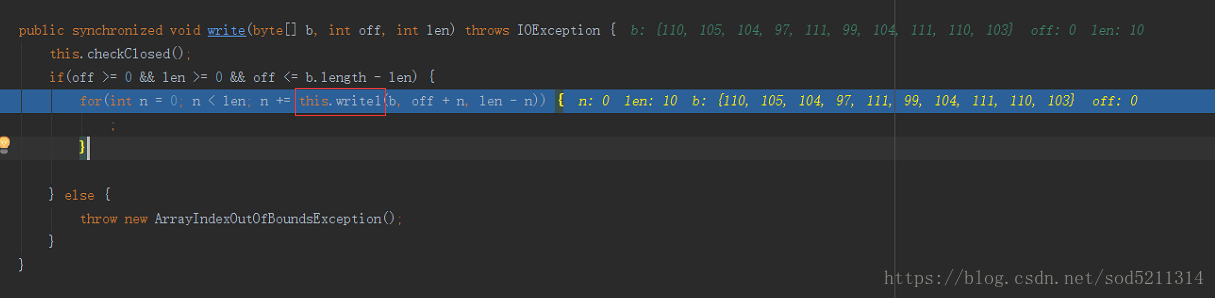

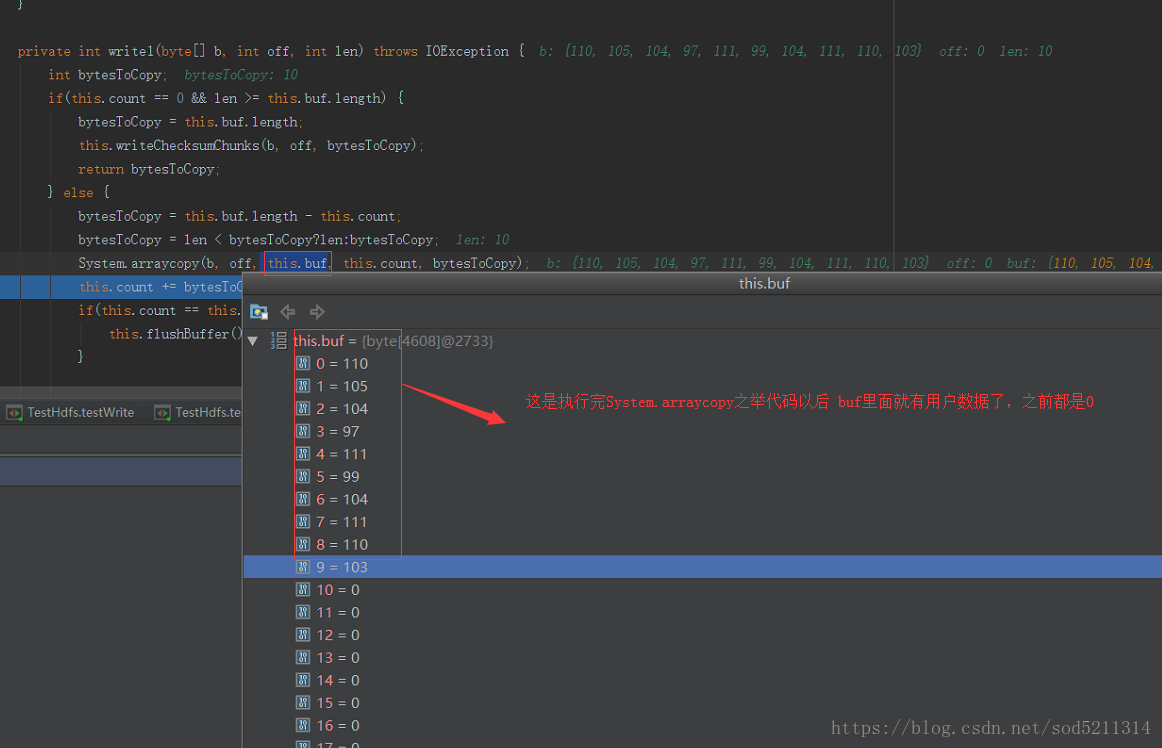
buf:就是本地缓冲区

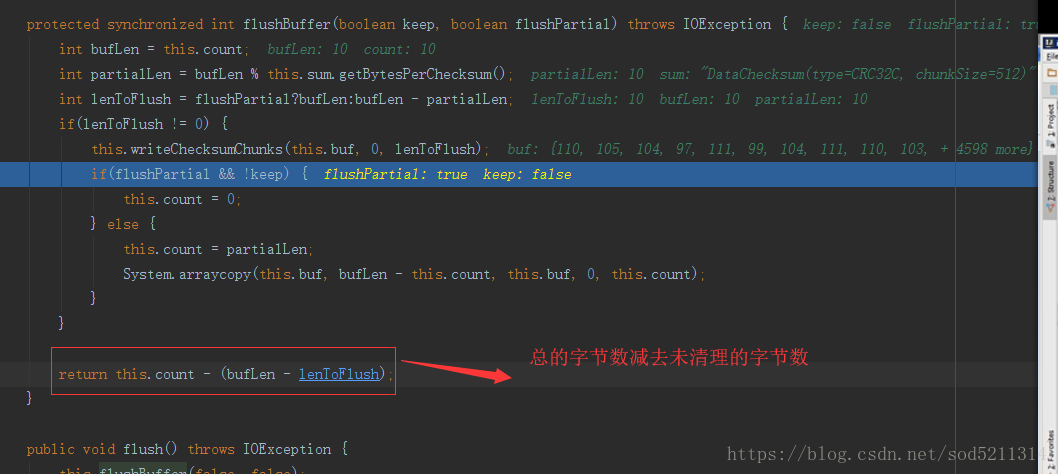
最后返回你所拷贝的量
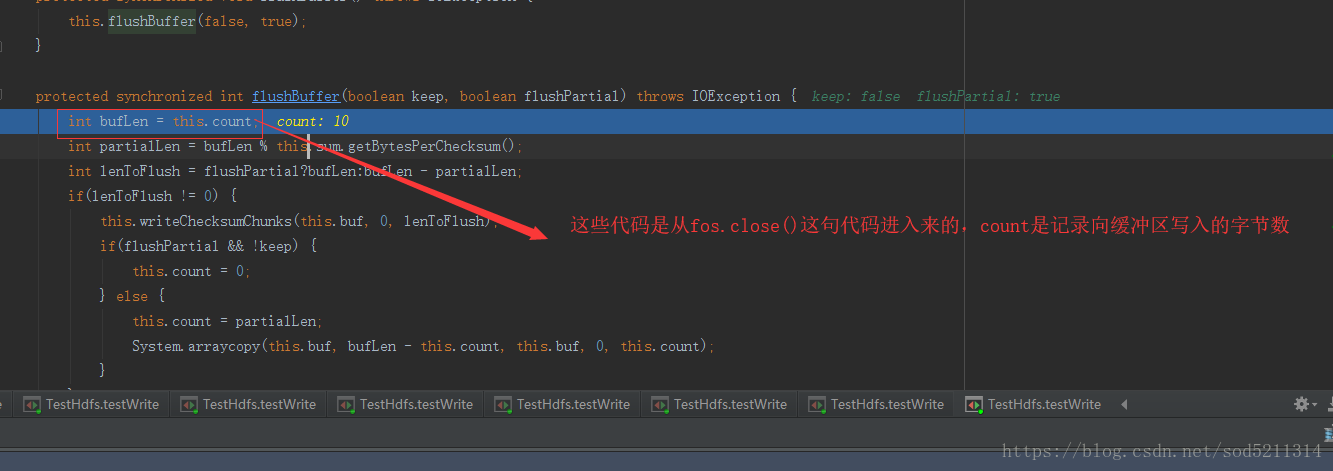
进入sum.getBytesPerChecksum()这个方法可以看出bytesPerChecksum是个成员变量

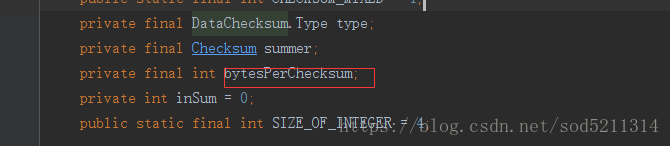
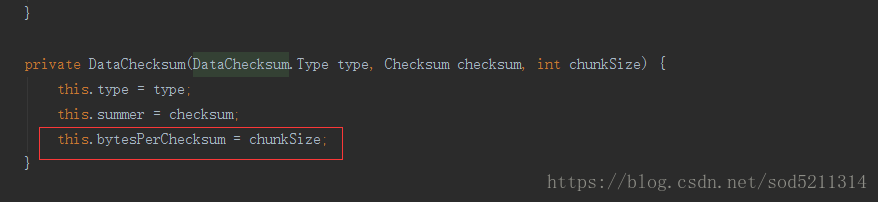
这个成员变量的值就等于chunksize
传输过程中要进行校验,从data1向data2传输数据的过程中要进行校验处理,把你要传输的数据和你要算的码放在一起,data2拿到你的数据后,再拿到你的校验和,我们通过算法来比较,如果发现码不对,说明数据就被篡改过。
每个校验和对应的字节,就是512一校验,校验和本身占4个字节,所以在清理缓冲区的时候它有个校验和处理,它计算每个校验和所对应的字节数这个
数是512



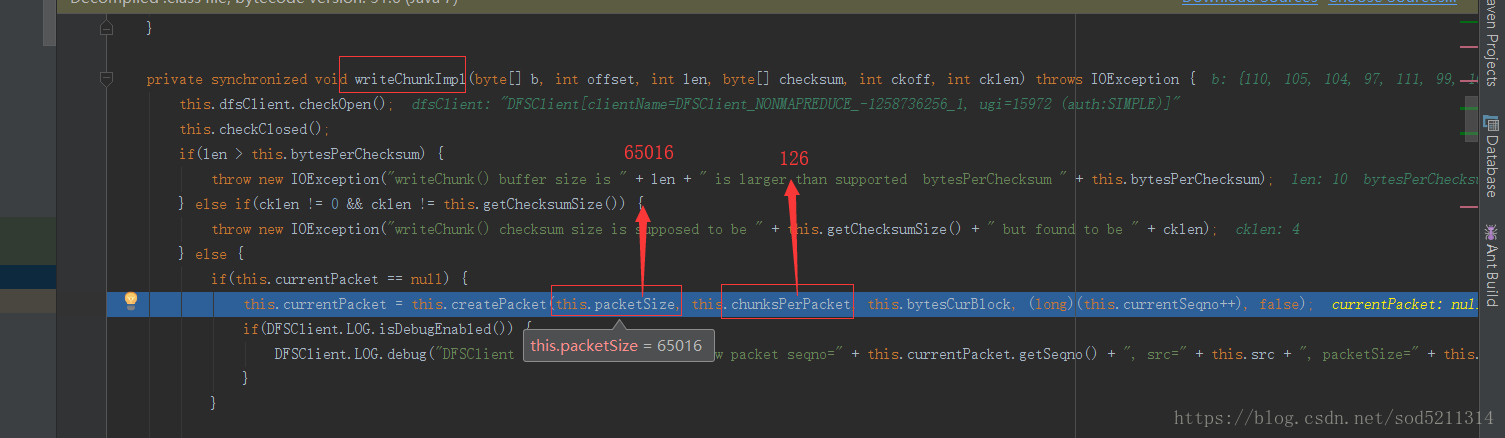
这个65016跟126是怎么来的呢?
65016除于126=516

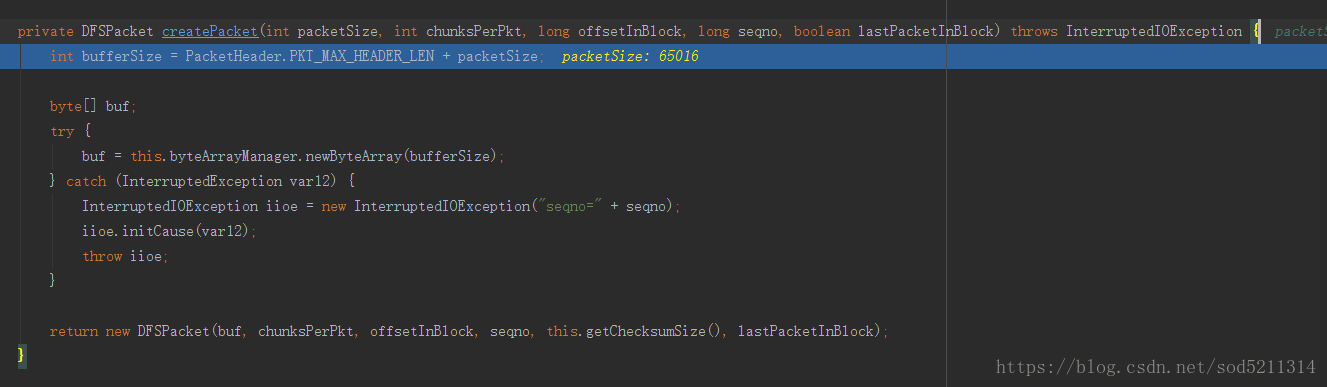
单步进入这个方法,里面是计算缓冲区大小的

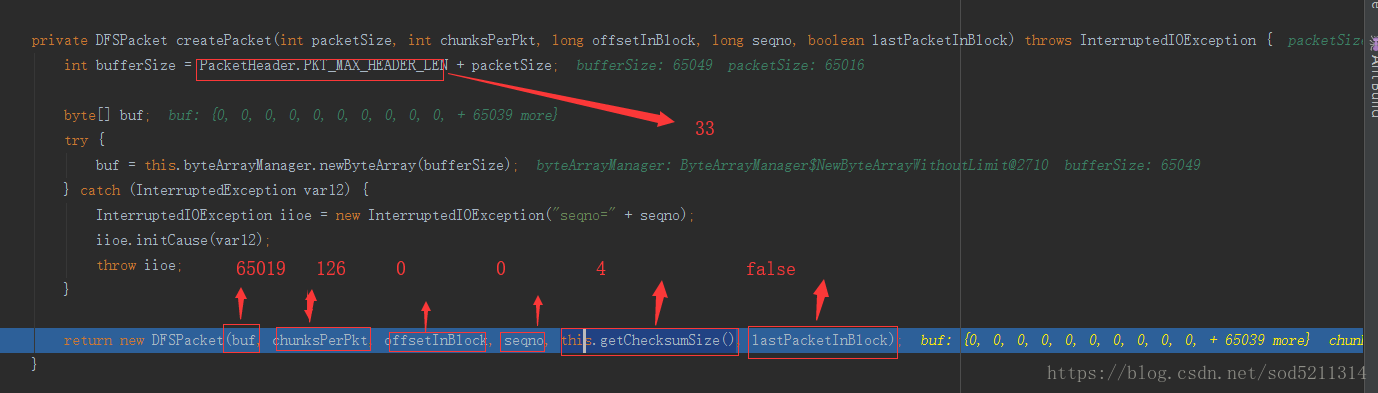
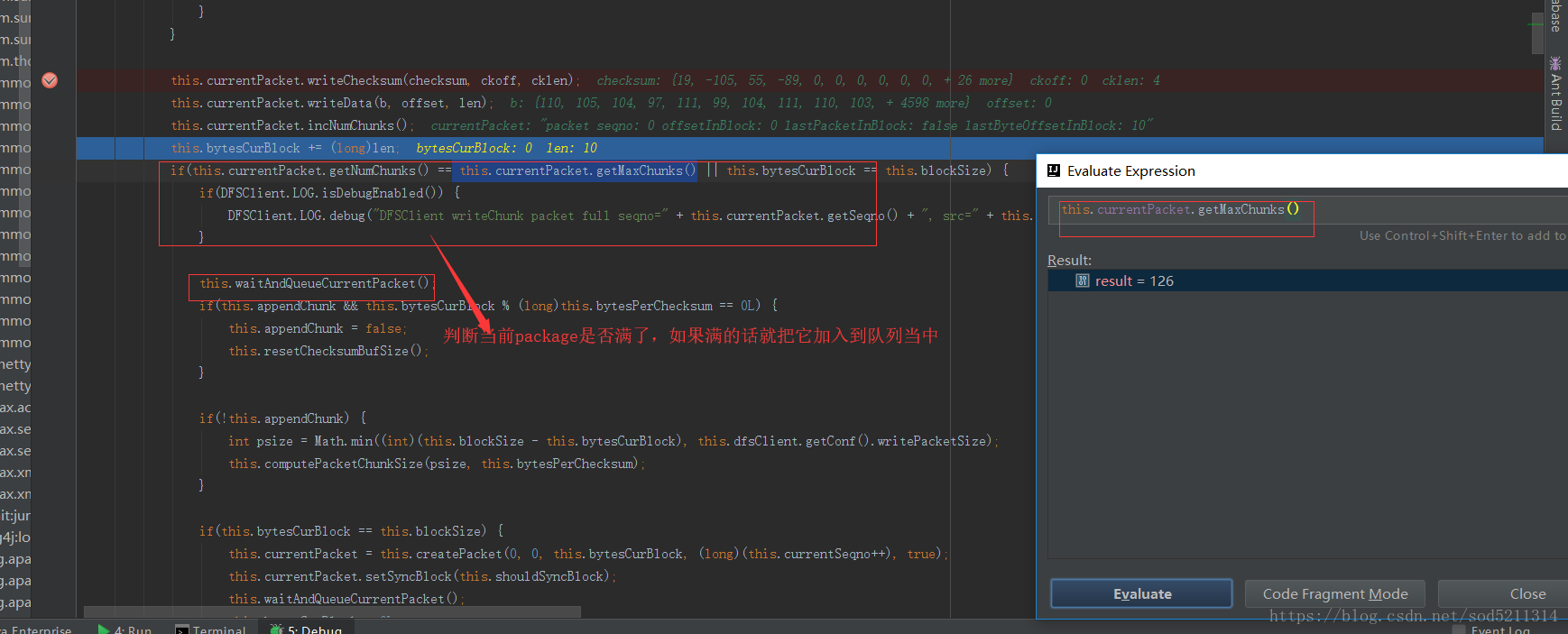
DFSPacket内部有四个指针,分别为
1、checksumStart:标记数据校验和区域起始位置
2、checksumPos:标记数据校验和区域当前写入位置
3、dataStart:标记真实数据区域起始位置
4、dataPos:标记真实数据区域当前写入位置
数据包是按照一组组数据块写入的,先写校验和数据块,再写真实数据块,然后再写下一组校验和数据块和真实数据块,最后再写上header头部信息,至此整个数据包写完。
每个DFSPacket都对应一个序列号seqno,还存储了数据在数据块中的位置offsetInBlock、数据包中的数据块(chunks)数量numChunks、数据包中的最大数据块数maxChunks、是否为block中最后一个数据包lastPacketInBlock等信息。

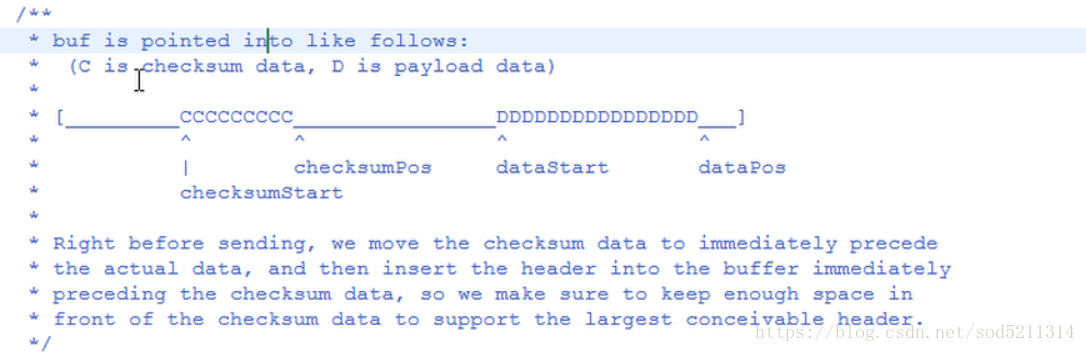


给出个DFSoutputStream的成员变量
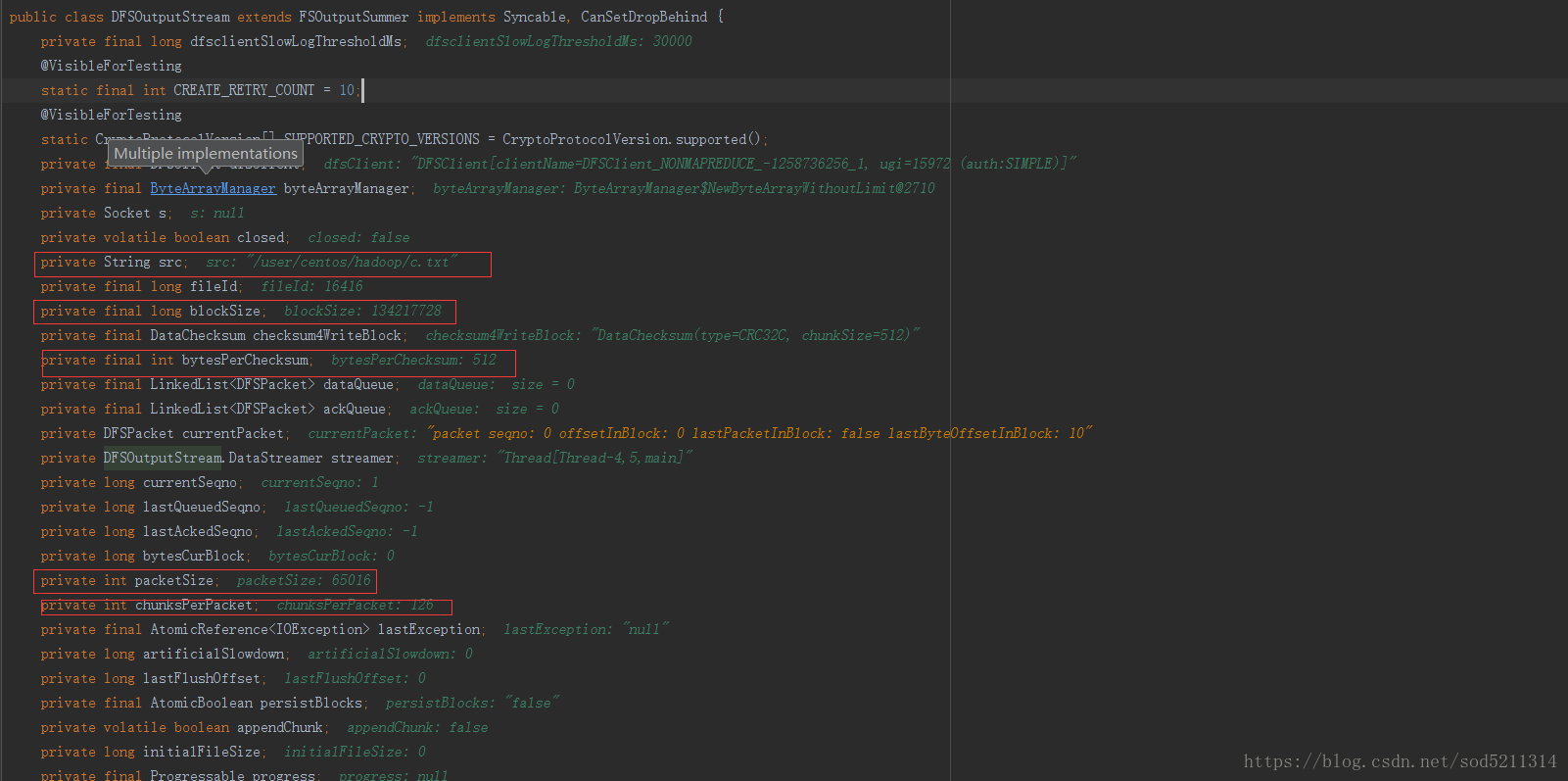
checksumPos=33
下


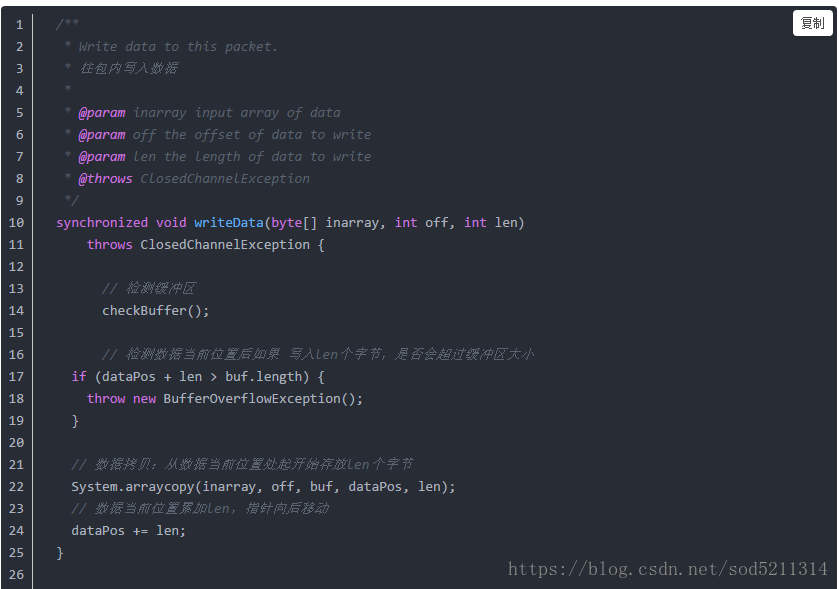
//send an empty package to mark the end of the block 发送一个空包来标记块的结束,每个块结束的时候还要发送一个空包
到这里数据包里面的数据已经准备好了,setSyncBlock设置同步块,即哪个块是同步点,接着this.flushInternal(); 即 flush all data to datanode


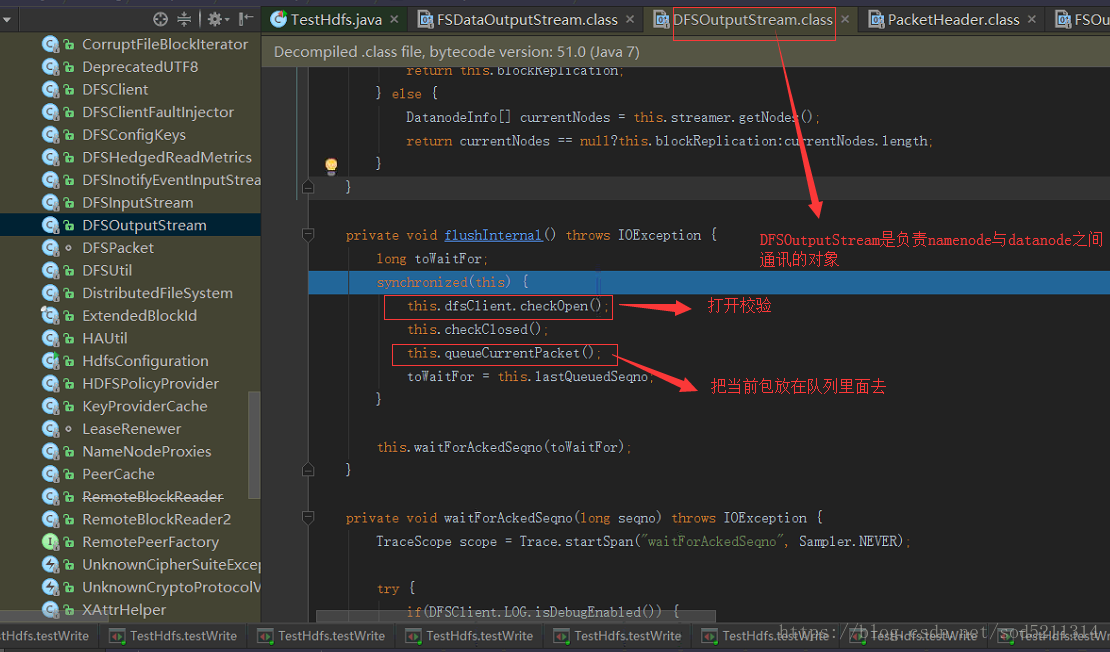
然后进入到这个方法里面去
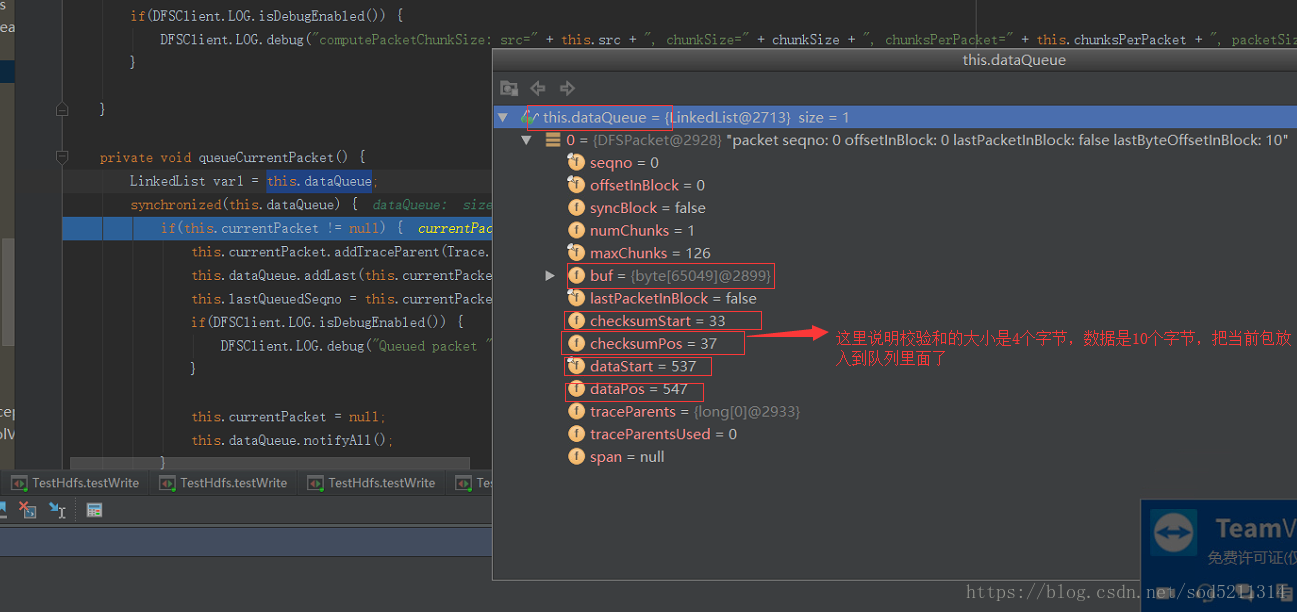

这个是为2的时候的截图

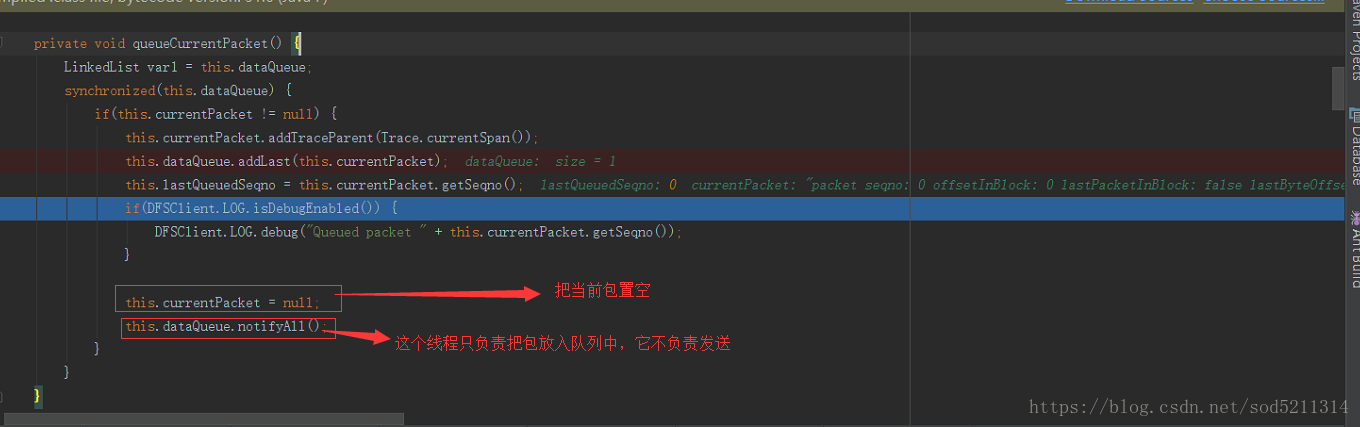
唤起消费进程
上面说到的data queue (数据队列) DataStreamer负责树立数据队列,它的职责是根据datanode列表来要求namenode分配合适的新块来存储数据副本,这一组
2、DataStreamer
DataStreamer是一个后台工作线程,它负责在数据流管道中往DataNode发送数据包。它从NameNode申请获取一个新的数据块ID和数据块位置,然后开始往DataNode的管道写入流式数据包。每个数据包都有一个序列号sequence number。当一个数据块所有的数据包被发送出去,并且每个数据包的确认信息acks被接收到的话,DataStreamer关闭当前数据块,然后再向NameNode申请下一个数据块。

所以,才会有上述发送数据包和确认数据包这两个队列。
DataStreamer内部有很多变量,大体如下:
datanode构成一个管线
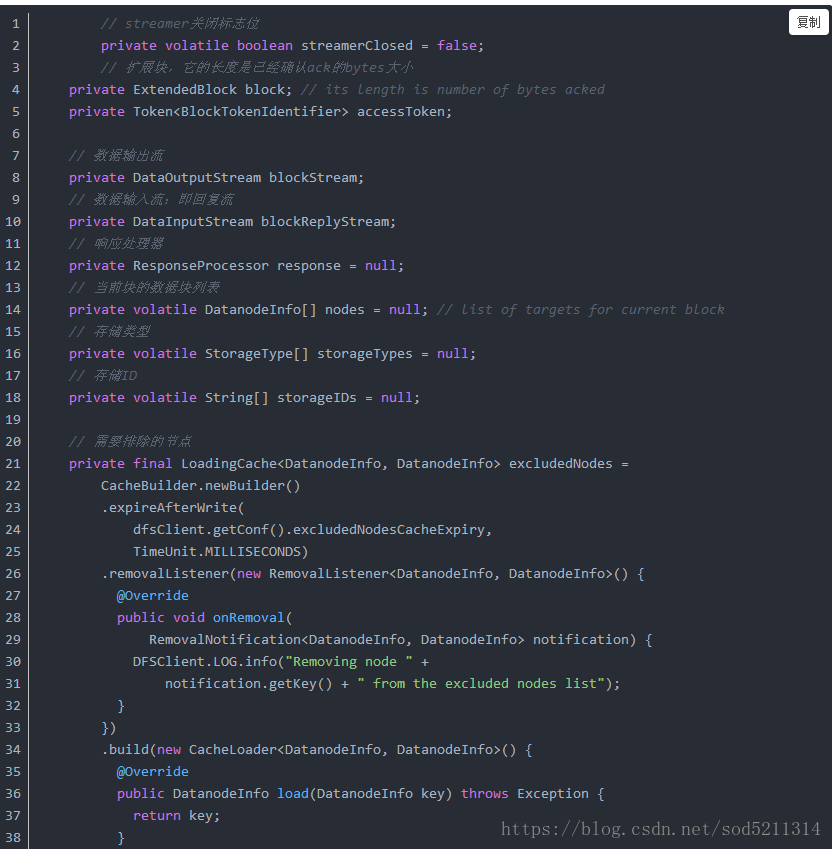
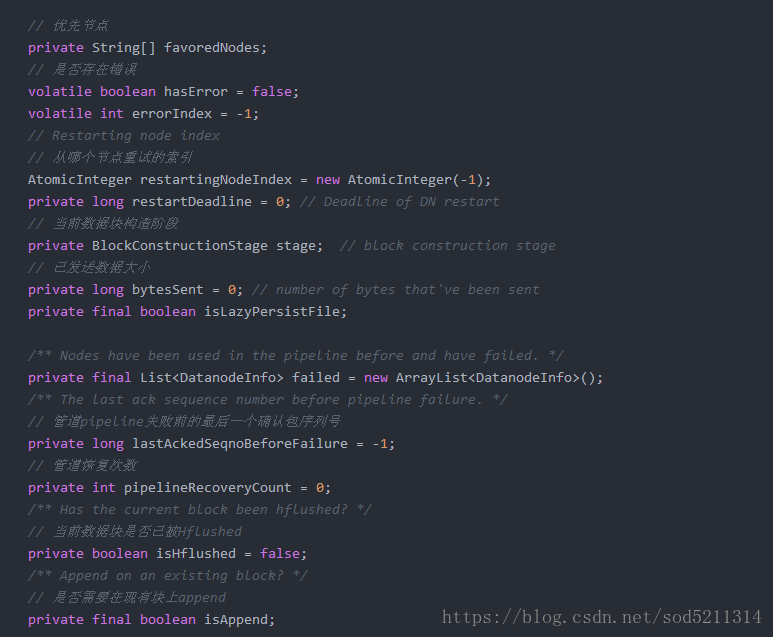


数据块存储在datanode中,但是fsimage并不描述datanode,取而代之的是,namenode将这种映射关系存放在内存当中,当datanode假如集群的时候,namenode向datanode索取块列表,以建立块的映射关系,namenode还将定期的征询datanode以确保它有最新的块映射