版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38038143/article/details/83144840
1.在virtualbox上设置共享目录
将 JDK 和 hadoop 压缩包上传到Ubuntu:
参考链接:https://blog.csdn.net/qq_38038143/article/details/83017877

2.JDK安装
- 在 /usr/local/ 下创建目录 java,将 JDK 解压到 java 目录,执行命令:
sudo tar -zxvf /usr/local/lib/jdk-8u152-linux-x64.tar.gz -C /usr/local/java/
查看 java目录:

- 配置环境变量:
执行命令:
sudo vim /etc/profile
在文件末尾添加以下内容:
JAVA_HOME=/usr/local/java/jdk1.8.0_152
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH
使配置生效:
source /etc/profile
- 查看JDK配置是否成功:
JDK安装完成。

3.hadoop安装
3.1. 解压hadoop
执行命令,分别为:解压hadoop、修改目录名称、修改目录拥有者(根据自己linux用户)
sudo tar -zxvf /usr/local/lib/hadoop-2.7.3.tar.gz -C /usr/local/
sudo mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
sudo chown hadoop /usr/local/hadoop
3.2. 配置 JDK 路径
进入目录:

修改文件:hadoop-env.sh
将第25行的 export JAVA_HOME=${JAVA_HOME} 修改为:

3.3. 配置 Hadoop 环境变量:
在文件末尾添加,修改文件:
vim ~/.bashrc
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
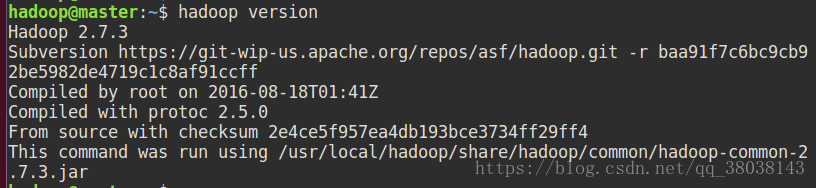
3.4. 查看Hadoop版本
Hadoop安装成功。
3.5. Hadoop单机实例运行:
进入目录:

创建目录,并将配置文件作为输入文件:
扫描二维码关注公众号,回复:
3619327 查看本文章

mkdir ./input
cp ./etc/hadoop/*.xml ./input
执行运行命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input/ ./output 'dfs[a-z.]+'
查看输出结果:
单机模式运行实例成功。

5.Hadoop伪分布
5.1 配置IP映射:
修改文件:sudo vim /etc/hosts
在文件中添加:(master为主机名)
127.0.0.1 master
重启网路:
sudo /etc/init.d/networking restart
5.2 免密登录:
安装ssh:
sudo apt-get install openssh-server
生成 ~/.ssh目录:
ssh master
# 输入密码登录后,执行exit退出
exit
执行命令,生成公钥、密钥:
ssh-keygen -t rsa #一直回车
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
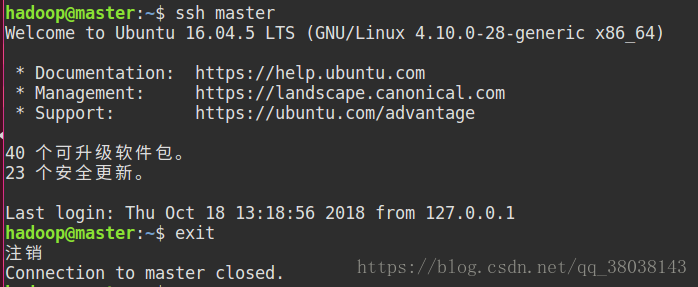
再次执行登录命令:
ssh master
若不再使用命令即可登录,即免密登录成功。
5.3 修改Hadoop配置文件:
待会更新