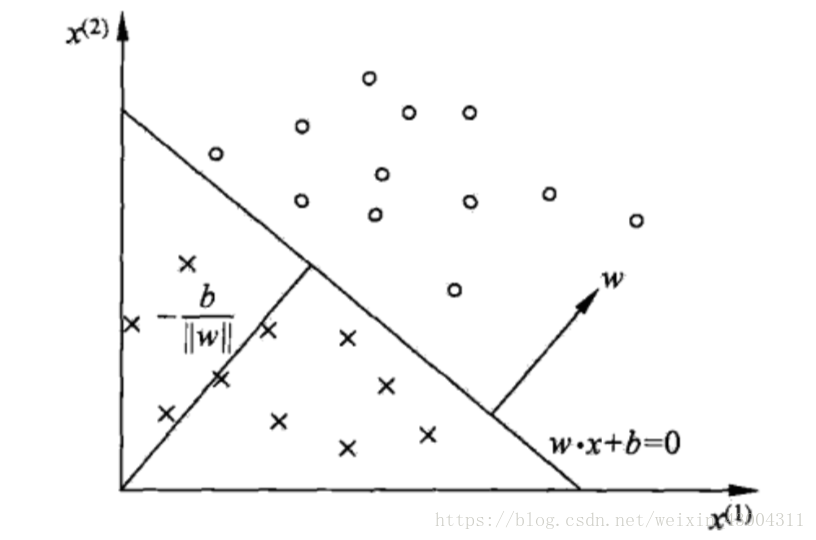
感知机(Perceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别(-1和+1),属于判别模型。其目标是求出将训练数据进行线性划分的分离超平面,基于误分类的损失函数,利用梯度下降法对损失函数进行极小化求得感知机模型。其优点是简单易于实现,分为对偶形式与原始形式。
感知机函数:
f
(
x
)
=
s
i
g
n
(
w
⋅
x
+
b
)
f(x) = sign(w \cdot x +b)
f ( x ) = s i g n ( w ⋅ x + b )
w
w
w
b
b
b
w
∈
R
n
w \in R^n
w ∈ R n
b
∈
R
b \in R
b ∈ R
w
⋅
x
w \cdot x
w ⋅ x
w
w
w
x
x
x
s
i
g
n
sign
s i g n
s
i
g
n
(
x
)
=
{
+
1
,
x
≥
0
−
1
,
x
<
0
sign(x) = \begin{cases} +1, x \geq0 \\\\ -1,x<0 \end{cases}
s i g n ( x ) = ⎩ ⎪ ⎨ ⎪ ⎧ + 1 , x ≥ 0 − 1 , x < 0
w
⋅
x
+
b
=
0
w \cdot x+b=0
w ⋅ x + b = 0
R
n
R^n
R n
w
,
b
w,b
w , b
由于采用误分类点的总数作为损失函数时,其不是参数
w
,
b
w,b
w , b
R
n
R^n
R n
x
0
x_{0}
x 0
1
∥
w
∥
y
i
(
w
⋅
x
i
+
b
)
\frac{1}{\|w\|}y_{i}(w \cdot x_{i} +b)
∥ w ∥ 1 y i ( w ⋅ x i + b )
∥
w
∥
\|w\|
∥ w ∥
w
w
w
L
2
L_{2}
L 2
w
⋅
x
i
+
b
>
0
w \cdot x_{i} + b \gt 0
w ⋅ x i + b > 0
y
i
=
−
1
y_{i} = -1
y i = − 1
w
⋅
x
i
+
b
<
0
w \cdot x_{i} + b \lt 0
w ⋅ x i + b < 0
y
i
=
+
1
y_{i} = +1
y i = + 1
因此,误分类点
x
i
x_{i}
x i
−
1
∥
w
∥
y
i
(
w
⋅
x
i
+
b
)
-\frac{1}{\|w\|}y_{i}(w \cdot x_{i} +b)
− ∥ w ∥ 1 y i ( w ⋅ x i + b )
−
1
∥
w
∥
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
-\frac{1}{\|w\|}\sum_{x_{i}\in M}y_{i}(w \cdot x_{i} + b)
− ∥ w ∥ 1 x i ∈ M ∑ y i ( w ⋅ x i + b )
1
∥
w
∥
\frac{1}{\|w\|}
∥ w ∥ 1
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
 
,
(
x
N
,
y
N
)
}
T=\{(x_{1},y_{1}),(x_{2},y_{2}),\cdots,(x_{N},y_{N})\}
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) }
x
i
∈
X
=
R
n
x_{i} \in X = R^n
x i ∈ X = R n
y
i
∈
Y
=
{
+
1
,
−
1
}
y_{i} \in Y = \{+1,-1\}
y i ∈ Y = { + 1 , − 1 }
i
=
1
,
2
,
⋯
 
,
N
i = 1,2,\cdots,N
i = 1 , 2 , ⋯ , N
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
L(w,b) = - \sum_{x_{i} \in M}y_{i}(w \cdot x_{i} + b)
L ( w , b ) = − x i ∈ M ∑ y i ( w ⋅ x i + b )
在介绍感知机的损失函数优化前,先简单说下梯度下降法。
**梯度下降法(Gradient descent)**是一个一阶最优化算法,那通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。
批量梯度下降 Batch Gradient Descent
随机梯度下降 Stochastic Gradient Descent
任意选取一个超平面
w
0
,
b
0
w_{0},b_{0}
w 0 , b 0
M
M
M
▽
w
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
x
i
\bigtriangledown_{w}L(w,b) = - \sum\limits_{x_{i}\in M}y_{i}x_{i}
▽ w L ( w , b ) = − x i ∈ M ∑ y i x i
▽
b
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
\bigtriangledown_{b}L(w,b) = - \sum\limits_{x_{i}\in M}y_{i}
▽ b L ( w , b ) = − x i ∈ M ∑ y i
(
x
i
,
y
i
)
(x_{i},y_{i})
( x i , y i )
w
←
w
+
η
y
i
x
i
w\gets w +\eta y_{i}x_{i}
w ← w + η y i x i
b
←
b
+
η
y
i
b\gets b +\eta y_{i}
b ← b + η y i
式中
η
(
0
<
η
≤
1
)
\eta(0<\eta \leq 1)
η ( 0 < η ≤ 1 )
因此,也得到了感知机的算法。
选取初始值
w
0
,
b
0
w_{0},b_{0}
w 0 , b 0
(
x
i
,
y
i
)
(x_{i},y_{i})
( x i , y i )
y
i
(
w
⋅
x
i
+
b
)
y_{i}(w\cdot x_{i} +b)
y i ( w ⋅ x i + b )
w
,
b
w,b
w , b
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
 
,
(
x
N
,
y
N
)
}
T = \{(x_{1},y_{1}),(x_{2},y_{2}),\cdots,(x_{N},y_{N})\}
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) }
x
i
∈
X
=
R
n
x_{i} \in X = R^{n}
x i ∈ X = R n
y
i
∈
Y
=
{
−
1
,
+
1
}
y_{i} \in Y = \{-1,+1\}
y i ∈ Y = { − 1 , + 1 }
i
=
1
,
2
,
⋯
 
,
N
i = 1,2,\cdots, N
i = 1 , 2 , ⋯ , N
η
(
0
<
η
≤
1
)
\eta(0<\eta\leq1)
η ( 0 < η ≤ 1 )
w
,
b
w,b
w , b
f
(
x
)
=
s
i
g
n
(
w
⋅
x
+
b
)
f(x)=sign(w\cdot x+b)
f ( x ) = s i g n ( w ⋅ x + b )
选取初值
w
0
,
b
0
w_{0},b_{0}
w 0 , b 0
在训练集中选取数据
(
x
i
,
y
j
)
(x_{i},y_{j})
( x i , y j )
如果
y
i
(
w
⋅
x
i
+
b
)
≤
0
y_{i}(w\cdot x_{i} + b) \leq 0
y i ( w ⋅ x i + b ) ≤ 0
w
←
w
+
η
y
i
x
i
w\gets w +\eta y_{i}x_{i}
w ← w + η y i x i
b
←
b
+
η
y
i
b\gets b +\eta y_{i}
b ← b + η y i
转至2,直至训练集中没有误分类点。
设训练集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
 
,
(
x
N
,
y
N
)
}
T = \{(x_{1},y_{1}),(x_{2},y_{2}),\cdots ,(x_{N},y_{N})\}
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) }
x
i
∈
X
=
R
n
x_{i}\in X= R^n
x i ∈ X = R n
y
i
∈
Y
=
{
+
1
,
−
1
}
y_{i}\in Y= \{+1,-1\}
y i ∈ Y = { + 1 , − 1 }
i
=
1
,
2
,
⋯
 
,
N
i=1,2,\cdots,N
i = 1 , 2 , ⋯ , N
存在满足条件
∥
w
^
o
p
t
∥
=
1
\Vert\hat{w}_{opt} \Vert=1
∥ w ^ o p t ∥ = 1
w
^
o
p
t
⋅
x
^
=
w
o
p
t
⋅
x
+
b
o
p
t
=
0
\hat{w}_{opt}\cdot \hat{x} = w_{opt}\cdot x+b_{opt}=0
w ^ o p t ⋅ x ^ = w o p t ⋅ x + b o p t = 0
γ
>
0
\gamma>0
γ > 0
i
=
1
,
2
,
⋯
 
,
N
i=1,2,\cdots,N
i = 1 , 2 , ⋯ , N
y
i
(
w
^
o
p
t
⋅
x
i
^
)
=
y
i
(
w
o
p
t
⋅
x
i
+
b
o
p
t
)
≥
γ
y_{i}(\hat{w}_{opt}\cdot \hat{x_{i}} )= y_{i}(w_{opt}\cdot x_{i}+b_{opt}) \geq \gamma
y i ( w ^ o p t ⋅ x i ^ ) = y i ( w o p t ⋅ x i + b o p t ) ≥ γ
令R=
max
1
≤
i
≤
N
∥
x
i
^
∥
\max\limits_{1\leq i \leq N}\Vert\hat{x_{i}}\Vert
1 ≤ i ≤ N max ∥ x i ^ ∥
k
<
=
(
R
γ
)
2
k <=( \frac{R}{\gamma})^2
k < = ( γ R ) 2
由于训练集线性可分,存在超平面可将训练集完全正确分开,取此超平面为
w
^
o
p
t
⋅
x
^
=
w
^
o
p
t
⋅
x
i
+
b
o
p
t
=
0
\hat{w}_{opt} \cdot \hat{x} = \hat{w}_{opt} \cdot x_{i}+ b_{opt} = 0
w ^ o p t ⋅ x ^ = w ^ o p t ⋅ x i + b o p t = 0
∥
w
^
o
p
t
∥
=
1
\|\hat{w}_{opt}\| = 1
∥ w ^ o p t ∥ = 1
y
i
(
w
^
o
p
t
⋅
x
^
)
=
y
i
(
w
^
o
p
t
⋅
x
i
+
b
o
p
t
)
>
0
y_{i}(\hat{w}_{opt} \cdot \hat{x}) = y_{i}(\hat{w}_{opt} \cdot x_{i}+ b_{opt}) \gt 0
y i ( w ^ o p t ⋅ x ^ ) = y i ( w ^ o p t ⋅ x i + b o p t ) > 0
γ
=
min
i
{
y
i
(
w
^
o
p
t
⋅
x
i
+
b
o
p
t
)
}
\gamma = \min_{i}\{y_{i}(\hat{w}_{opt} \cdot x_{i}+ b_{opt})\}
γ = i min { y i ( w ^ o p t ⋅ x i + b o p t ) }
y
i
(
w
^
o
p
t
⋅
x
^
)
=
y
i
(
w
^
o
p
t
⋅
x
+
b
o
p
t
)
≥
γ
y_{i}(\hat{w}_{opt} \cdot \hat{x}) = y_{i}(\hat{w}_{opt} \cdot x+ b_{opt}) \ge \gamma
y i ( w ^ o p t ⋅ x ^ ) = y i ( w ^ o p t ⋅ x + b o p t ) ≥ γ
w
0
^
=
0
\hat{w_{0}} = 0
w 0 ^ = 0
w
k
−
1
w_{k-1}
w k − 1
k
k
k
w
k
−
1
=
(
w
k
−
1
T
,
b
k
−
1
)
T
w_{k-1}=(w_{k-1}^T,b_{k-1})^T
w k − 1 = ( w k − 1 T , b k − 1 ) T
k
k
k
(
x
i
,
y
i
)
(x_{i},y_{i})
( x i , y i )
−
y
i
(
w
k
−
1
⋅
x
i
+
b
k
−
1
)
>
0
-y_{i}(w_{k-1} \cdot x_{i} + b_{k-1}) \gt 0
− y i ( w k − 1 ⋅ x i + b k − 1 ) > 0
y
i
(
w
k
−
1
⋅
x
i
+
b
k
−
1
)
≤
0
y_{i}(w_{k-1} \cdot x_{i} + b_{k-1}) \le 0
y i ( w k − 1 ⋅ x i + b k − 1 ) ≤ 0
w
k
←
w
k
−
1
+
η
y
i
x
i
w_{k}\gets w_{k-1} +\eta y_{i}x_{i}
w k ← w k − 1 + η y i x i
b
k
←
b
k
−
1
+
η
y
i
b_{k}\gets b_{k-1} +\eta y_{i}
b k ← b k − 1 + η y i
w
k
^
=
w
k
−
1
^
+
η
y
i
x
i
^
\hat{w_{k}} = \hat{w_{k-1}} +\eta y_{i}\hat{x_{i}}
w k ^ = w k − 1 ^ + η y i x i ^
y
i
(
w
o
p
t
^
⋅
x
i
^
)
=
y
i
(
w
o
p
t
⋅
x
i
+
b
o
p
t
)
≥
γ
y_{i}(\hat{w_{opt}} \cdot \hat{x_{i}}) = y_{i}(w_{opt}\cdot x_{i}+b_{opt}) \geq \gamma
y i ( w o p t ^ ⋅ x i ^ ) = y i ( w o p t ⋅ x i + b o p t ) ≥ γ
y
i
(
w
o
p
t
^
⋅
x
i
^
)
=
y
i
(
w
k
−
1
⋅
x
i
)
+
b
k
−
1
≤
0
y_{i}(\hat{w_{opt}} \cdot \hat{x_{i}}) = y_{i}(w_{k-1}\cdot x_{i})+b_{k-1} \leq 0
y i ( w o p t ^ ⋅ x i ^ ) = y i ( w k − 1 ⋅ x i ) + b k − 1 ≤ 0
w
k
^
⋅
w
o
p
t
^
=
w
k
−
1
^
⋅
w
o
p
t
^
+
η
y
i
(
w
o
p
t
^
w
i
^
)
\hat{w_{k}} \cdot \hat{w_{opt}} = \hat{w_{k-1}} \cdot \hat{w_{opt}} + \eta y_{i} (\hat{w_{opt}}\hat{w_{i}})
w k ^ ⋅ w o p t ^ = w k − 1 ^ ⋅ w o p t ^ + η y i ( w o p t ^ w i ^ )
≥
w
k
−
1
^
⋅
w
o
p
t
^
+
η
γ
\ge \hat{w_{k-1}} \cdot \hat{w_{opt}} + \eta \gamma
≥ w k − 1 ^ ⋅ w o p t ^ + η γ
≥
w
k
−
2
^
⋅
w
o
p
t
^
+
2
η
γ
\ge \hat{w_{k-2}} \cdot \hat{w_{opt}} +2 \eta \gamma
≥ w k − 2 ^ ⋅ w o p t ^ + 2 η γ
≥
⋯
\ge \cdots
≥ ⋯
≥
k
η
γ
\ge k \eta \gamma
≥ k η γ
w
k
^
⋅
w
o
p
t
^
≥
k
η
γ
\hat{w_{k}} \cdot \hat{w_{opt}} \ge k \eta \gamma
w k ^ ⋅ w o p t ^ ≥ k η γ
(2) 由
y
i
(
w
o
p
t
^
⋅
x
i
^
)
=
y
i
(
w
k
−
1
⋅
x
i
)
+
b
k
−
1
≤
0
y_{i}(\hat{w_{opt}} \cdot \hat{x_{i}}) = y_{i}(w_{k-1}\cdot x_{i})+b_{k-1} \leq 0
y i ( w o p t ^ ⋅ x i ^ ) = y i ( w k − 1 ⋅ x i ) + b k − 1 ≤ 0
w
k
^
=
w
k
−
1
^
+
η
y
i
x
i
\hat{w_{k}} = \hat{w_{k-1}} + \eta y_{i}x_{i}
w k ^ = w k − 1 ^ + η y i x i
∥
w
k
^
∥
2
=
∥
w
k
−
1
^
∥
2
+
2
η
y
i
w
k
−
1
^
x
i
+
η
2
∥
x
i
^
∥
2
\|\hat{w_{k}}\|^2 =\|\hat{w_{k-1}}\|^2 + 2 \eta y_{i}\hat{w_{k-1}}x_{i} + \eta^2\|\hat{x_{i}}\|^2
∥ w k ^ ∥ 2 = ∥ w k − 1 ^ ∥ 2 + 2 η y i w k − 1 ^ x i + η 2 ∥ x i ^ ∥ 2
≤
∥
w
k
−
1
^
∥
2
+
η
2
∥
x
i
^
∥
2
\le \|\hat{w_{k-1}}\|^2 + \eta^2\|\hat{x_{i}}\|^2
≤ ∥ w k − 1 ^ ∥ 2 + η 2 ∥ x i ^ ∥ 2
≤
∥
w
k
−
1
^
∥
2
+
η
2
R
2
\le \|\hat{w_{k-1}}\|^2 + \eta^2 R^2
≤ ∥ w k − 1 ^ ∥ 2 + η 2 R 2
≤
∥
w
k
−
2
^
∥
2
+
2
η
2
R
2
\le \|\hat{w_{k-2}}\|^2 + 2\eta^2 R^2
≤ ∥ w k − 2 ^ ∥ 2 + 2 η 2 R 2
≤
⋯
\le \cdots
≤ ⋯
≤
k
η
2
R
2
\le k\eta^2 R^2
≤ k η 2 R 2
w
k
^
⋅
w
o
p
t
^
≥
k
η
γ
\hat{w_{k}} \cdot \hat{w_{opt}} \ge k \eta \gamma
w k ^ ⋅ w o p t ^ ≥ k η γ
∥
w
k
^
∥
2
≤
k
η
2
R
2
\|\hat{w_{k}}\|^2 \le k\eta^2 R^2
∥ w k ^ ∥ 2 ≤ k η 2 R 2
z
T
u
=
∥
z
∥
⋅
∥
u
∥
c
o
s
θ
≤
∥
z
∥
⋅
∥
u
∥
z^{T}u = \|z\| \cdot \|u\| cos \theta \le \|z\| \cdot \|u\|
z T u = ∥ z ∥ ⋅ ∥ u ∥ c o s θ ≤ ∥ z ∥ ⋅ ∥ u ∥
k
η
γ
≤
w
k
^
⋅
w
o
p
t
^
≤
∥
w
k
^
∥
∥
w
o
p
t
^
∥
≤
k
η
R
k \eta \gamma \le \hat{w_{k}} \cdot \hat{w_{opt}} \le \|\hat{w_{k}}\|\|\hat{w_{opt}}\| \le \sqrt{k} \eta R
k η γ ≤ w k ^ ⋅ w o p t ^ ≤ ∥ w k ^ ∥ ∥ w o p t ^ ∥ ≤ k
η R
k
=
(
R
γ
)
2
k = (\frac{R}{\gamma})^2
k = ( γ R ) 2
因此,误分类的次数k是有上限的,经过有限次数搜索可以找到将训练数据完全正确分开的分离超平面,即当训练集线性可分时,感知机学习算法原始形式迭代是收敛的。
假设样本点
(
x
i
,
y
i
)
(x_{i},y_{i})
( x i , y i )
n
i
n_{i}
n i
w
=
∑
i
=
1
N
n
i
η
y
i
x
i
w = \sum\limits_{i=1}^Nn_{i}\eta y_{i}x_{i}
w = i = 1 ∑ N n i η y i x i
b
=
∑
i
=
1
N
n
i
η
y
i
b = \sum\limits_{i=1}^Nn_{i}\eta y_{i}
b = i = 1 ∑ N n i η y i
n
i
n_{i}
n i
n
i
n_{i}
n i
w
w
w
b
b
b
f
(
x
)
=
s
i
g
n
(
w
⋅
x
+
b
)
=
s
i
g
n
(
∑
j
=
1
N
n
j
η
y
j
x
j
⋅
x
+
∑
j
=
1
N
n
j
η
y
j
)
f(x) = sign(w \cdot x + b) = sign(\sum\limits_{j=1}^Nn_{j}\eta y_{j}x_{j} \cdot x + \sum\limits_{j=1}^Nn_{j}\eta y_{j})
f ( x ) = s i g n ( w ⋅ x + b ) = s i g n ( j = 1 ∑ N n j η y j x j ⋅ x + j = 1 ∑ N n j η y j )
w
w
w
b
b
b
n
i
n_{i}
n i
i
=
1
,
2
,
⋯
 
,
N
i=1,2,\cdots,N
i = 1 , 2 , ⋯ , N
相应地,训练过程变为:
初始时
∀
n
i
=
0
\forall n_{i}=0
∀ n i = 0
在训练集中选取数据
(
x
i
,
y
i
)
(x_{i},y_{i})
( x i , y i )
如果
y
i
(
∑
j
=
1
N
n
j
η
y
j
x
j
⋅
x
i
+
∑
j
=
1
N
n
j
η
y
j
)
<
=
0
y_{i}(\sum\limits_{j=1}^Nn_{j}\eta y_{j}x_{j} \cdot x_{i}+ \sum\limits_{j=1}^Nn_{j}\eta y_{j}) <=0
y i ( j = 1 ∑ N n j η y j x j ⋅ x i + j = 1 ∑ N n j η y j ) < = 0
n
i
←
n
i
+
1
n_{i} \gets n_{i} + 1
n i ← n i + 1
转至2直至没有误分类数据
通过计算,对偶形式和原始形式的结果一致,从对偶形式的公式中可以看出,样本点的特征向量以内积的形式存在于感知机对偶形式的训练算法中,因此如果事先计算好所有的内积(也即Gram矩阵),就可以大大加快计算速度。
Garm矩阵计算方式:
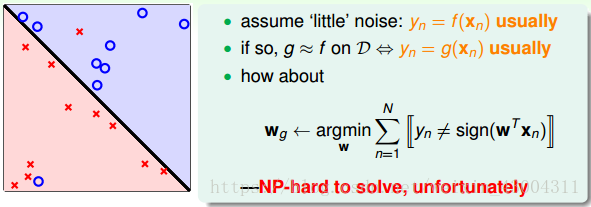
在前面我们证明了在线性可分的情况下,PLA是可以停下来并正确分类,但对于非线性可分的情况,实际上并不存在这样的一条线
(
w
f
)
(w_{f})
( w f )
from sklearn. linear_model import Perceptron
ppn = Perceptron( max_iter= 40 , eta0= 0.1 , random_state= 1 )
ppn. fit( X_train_std, y_train)
详细代码见github
本文同步发布在我的github.io