高阶函数:
首先我们先举个例子,以Python内置函数abs()为例:
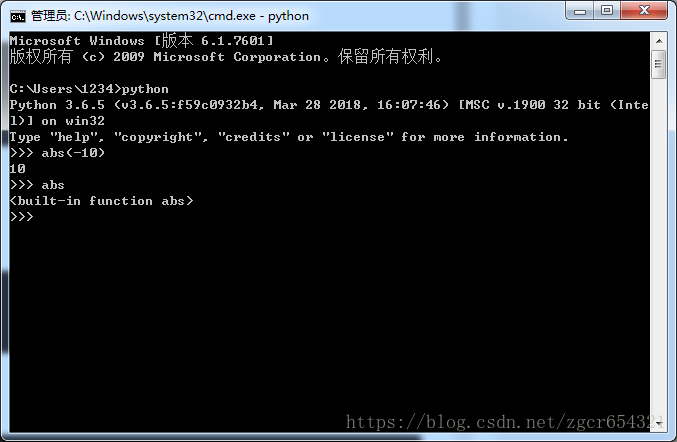
>>> abs(-10)
10
>>> abs
<built-in function abs>
我们可以看出abs(-10)是函数调用,而abs是函数本身。
运行截图如下:
再举一个例子:
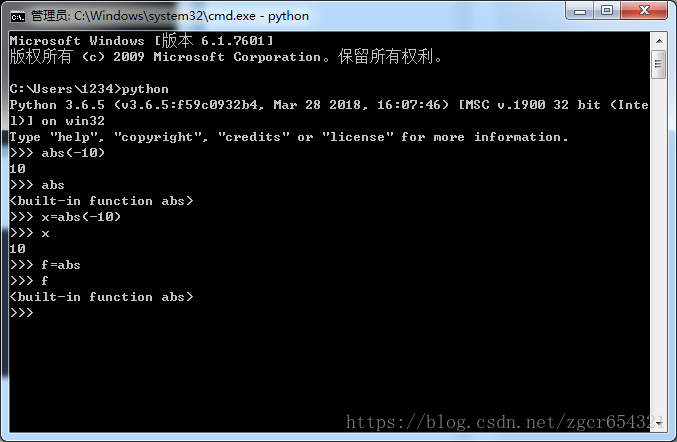
>>> x = abs(-10)
>>> x
10
>>> f = abs
>>> f
<built-in function abs>abs(-10)函数调用的结果可以赋值给变量,abs函数本身也可以赋给变量(这样变量指向了这个函数,相当于给函数起了一个别名)。
运行截图如下:
此时我们如果用变量名代替函数来进行函数调用,如:
>>> f = abs
>>> f(-10)
10
>>> abs(-10)
10可以看到调用变量f(-10)和调用函数abs(-10)完全相同。
运行截图如下:
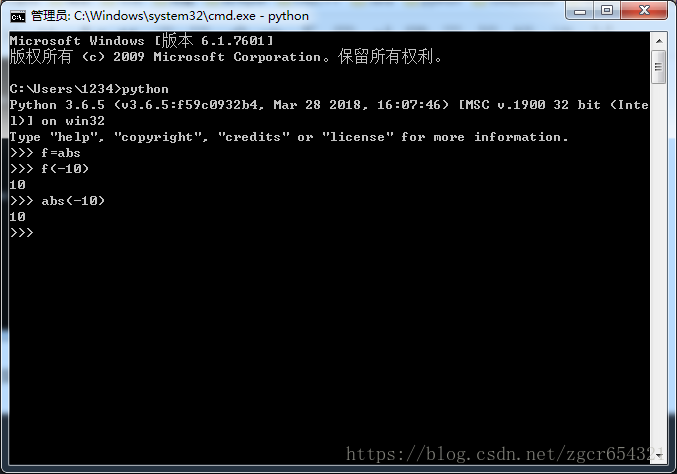
从上面的例子,我们得到结论:
函数名就是一个指向函数本身的变量,f与abs不同的是abs是默认指向取绝对值函数的变量,而f是我们人为指向取绝对值函数的变量。
高阶函数的定义:
一个函数如果它的参数中有些参数可以接收另一个函数作为参数,这种函数就称之为高阶函数。
如:
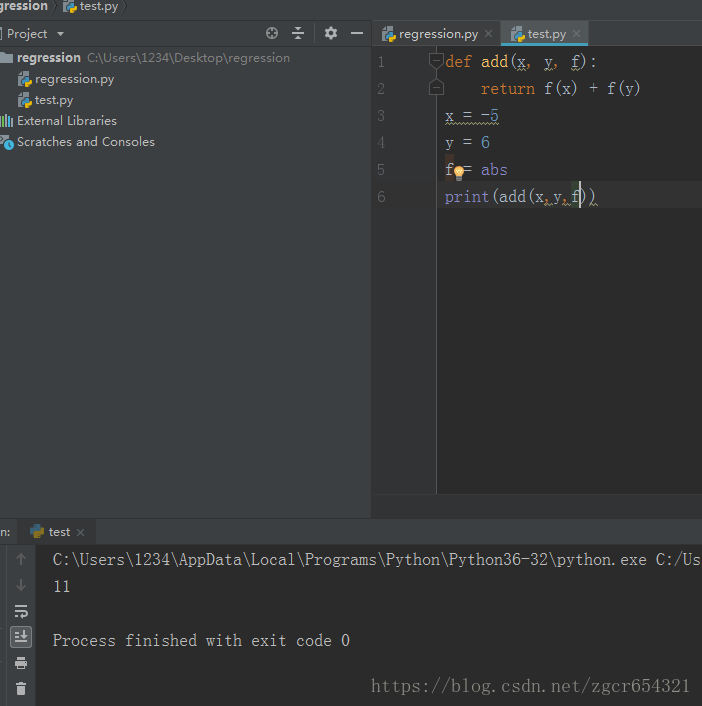
def add(x, y, f):
return f(x) + f(y)
x = -5
y = 6
f = abs
print(add(x,y,f))
运行截图如下:
map()函数:
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回(Python3中返回Iterator迭代器,Python2中返回列表(list))。
如:
我们有一个函数f(x)=x*x,我们想让一个list的所有元素依次带入这个函数进行运算并得到结果,则:
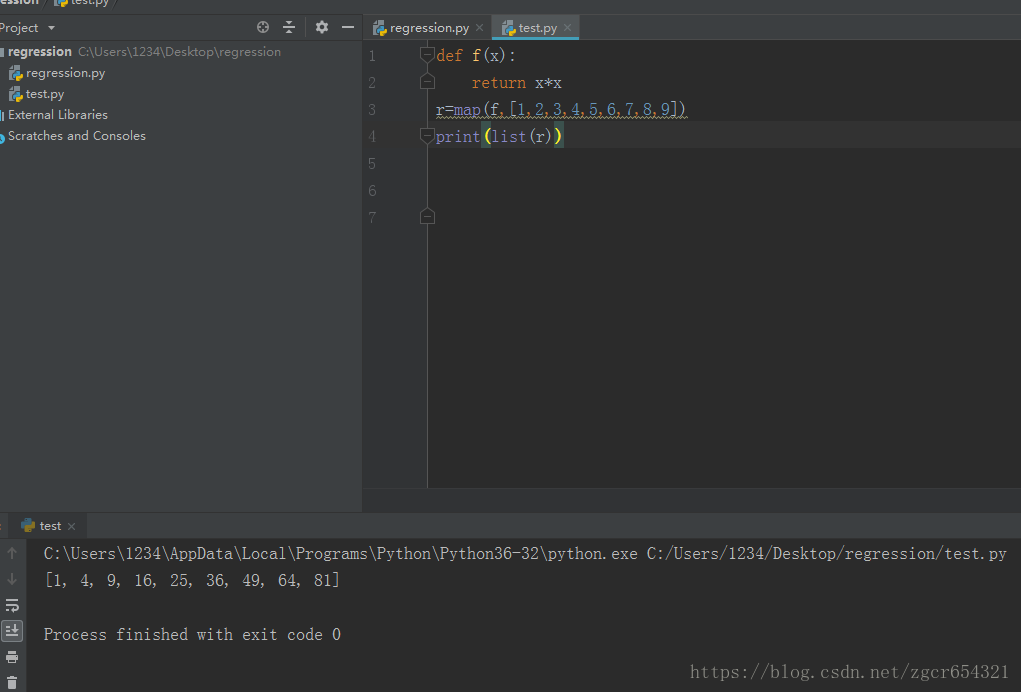
def f(x):
return x*x
r=map(f,[1,2,3,4,5,6,7,8,9])
print(list(r))
list() 方法用于将元组转换为列表。这里可以通过list()函数让它把整个序列都计算出来并返回一个list。
运行截图如下:
注意:
迭代器的一个优点就是它不要求你事先准备好整个迭代过程中所有的元素。
迭代器仅仅在迭代至某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点被称为延迟计算或惰性求值(Lazy evaluation)。
具有惰性计算特点的序列称为惰性序列。Python的iterator是一个惰性序列,意思是表达式和变量绑定后不会立即进行求值,而是当你用到其中某些元素的时候才去求某元素对的值。 惰性是指,你不主动去遍历它,就不会计算其中元素的值。
reduce()函数:
reduce() 函数会对参数序列中元素进行累积。用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,依次类推直到运算完集合中的最后一个元素,最后返回函数计算结果。
如,reduce实际等同于:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
举例:
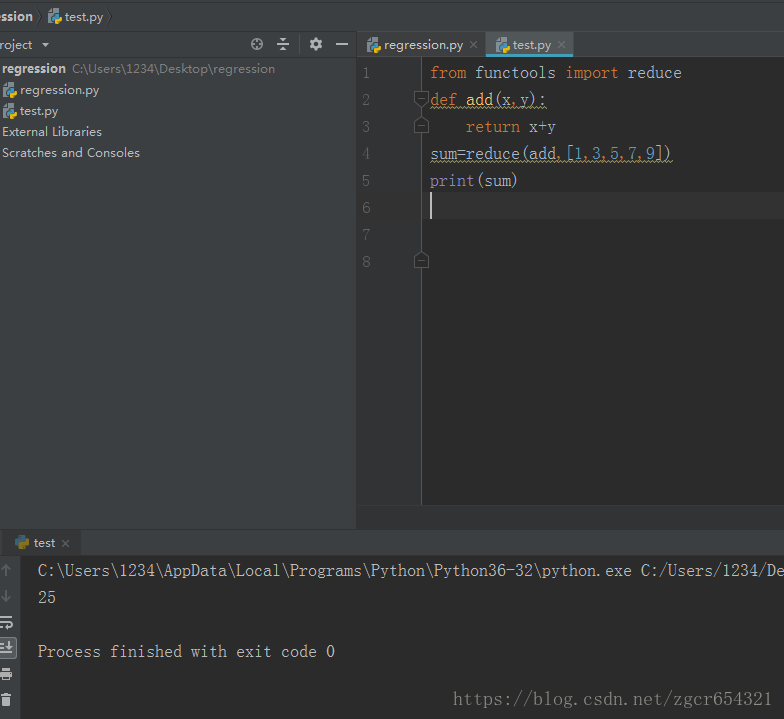
from functools import reduce
def add(x,y):
return x+y
sum=reduce(add,[1,3,5,7,9])
print(sum)
运行截图如下:
再比如,配合使用map()函数,我们就可以把一个由数字字符组成的字符串转换成数字。
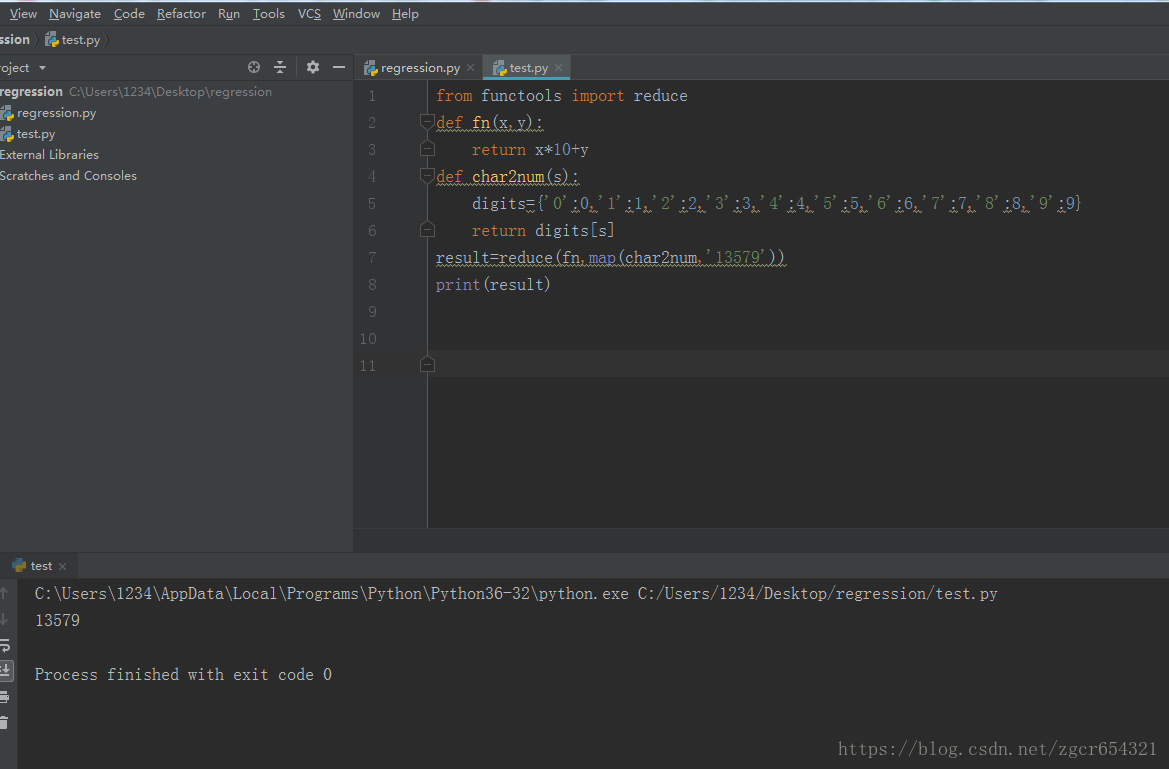
from functools import reduce
def fn(x,y):
return x*10+y
def char2num(s):
digits={'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9}
return digits[s]
result=reduce(fn,map(char2num,'13579'))
print(result)运行截图如下:
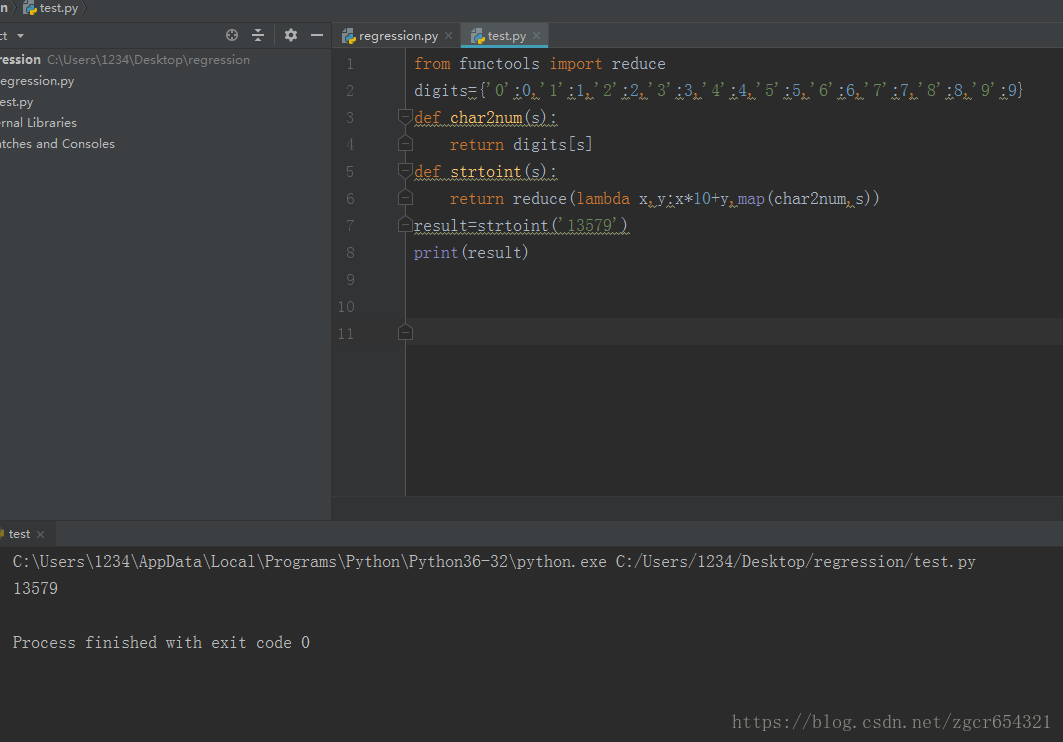
from functools import reduce
digits={'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9}
def char2num(s):
return digits[s]
def strtoint(s):
return reduce(lambda x,y:x*10+y,map(char2num,s))
result=strtoint('13579')
print(result)
lambda x,y:x*10+y是一个匿名函数,表示函数传入两个参数x和y,计算x*10+y并将结果返回。
运行截图如下:
filter()函数:
filter()函数用于过滤序列。filter()函数接收一个函数和一个序列。filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
如,在一个list中,删掉偶数,只保留奇数:
def odd(n):
return n%2==1
print(list(filter(odd,[1,2,4,5,6,9,10,15])))
运行截图如下:
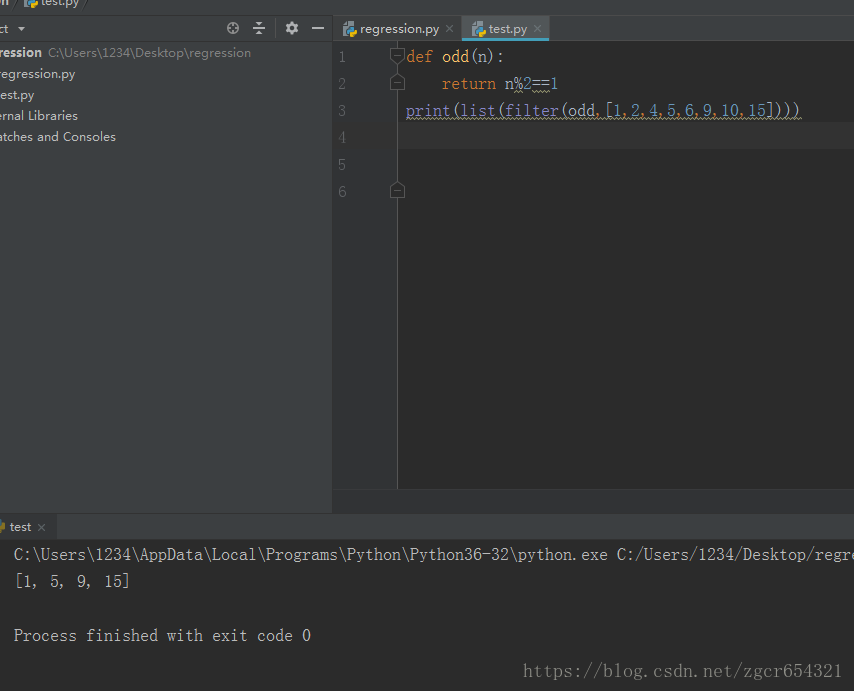
注意:filter()函数返回的是一个Iterator,和map()函数类似,也是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
我们使用埃拉托色尼筛选法。
首先,列出从2开始的所有自然数,构造一个序列:
2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...
取序列的第一个数2,它一定是素数,然后用2把序列的2的倍数筛掉:
3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...
取新序列的第一个数3,它一定是素数,然后用3把序列的3的倍数筛掉:
5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...
依次类推,不断筛下去,就可以得到所有的素数。
如,我们先构造一个从3开始只有奇数的序列(除2以外的偶数必不是素数):
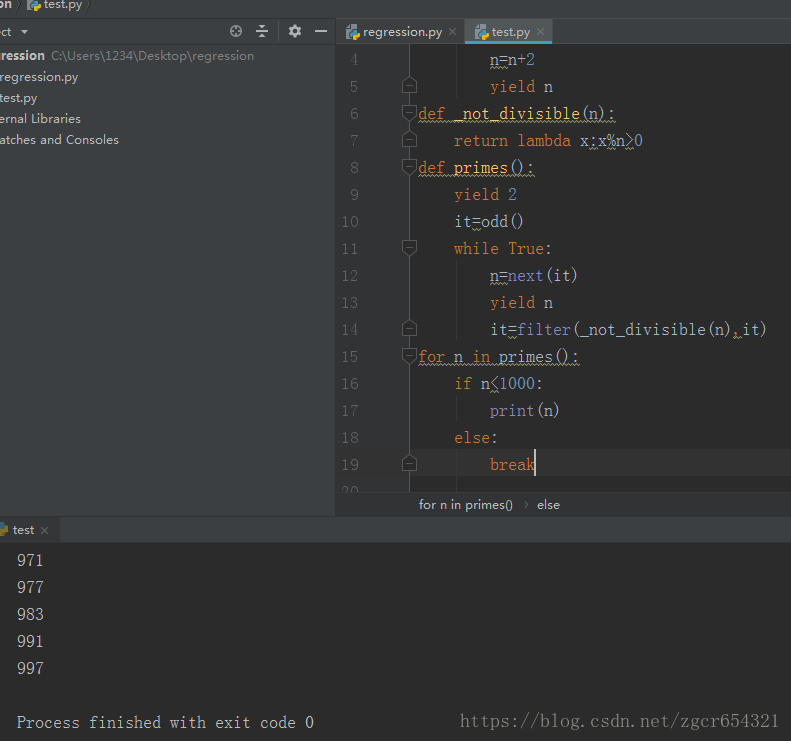
def odd()://构造一个无限的奇数序列
n=1
while True:
n=n+2
yield n
def _not_divisible(n)://筛选出素数的函数
return lambda x:x%n>0
def primes()://定义一个生成器,不断生成下一个素数
yield 2
it=odd()//初始惰性序列
while True:
n=next(it)//返回序列的第一个数
yield n
it=filter(_not_divisible(n),it)//用当前的n将序列中的数筛了一遍,形成新序列
for n in primes()://打印1000以内素数
if n<1000:
print(n)
else:
break运行截图如下:
sorted()函数:
在python中对list进行排序有两种方法:
用List的成员函数sort进行排序,在原list中进行排序,不返回副本;
用built-in函数sorted进行排序(从2.4开始),返回副本,原始输入不变。
python3中sorted取消了对cmp的支持,格式:
sorted(iterable,key=None,reverse=False)
key的作用原理:key指定一个接收一个参数的函数,这个函数用于从每个元素中提取一个用于比较的关键字。默认值为None ;
reverse是一个布尔值。如果设置为True,列表元素将被倒序排列,默认为False。
sort()与sorted函数举例:
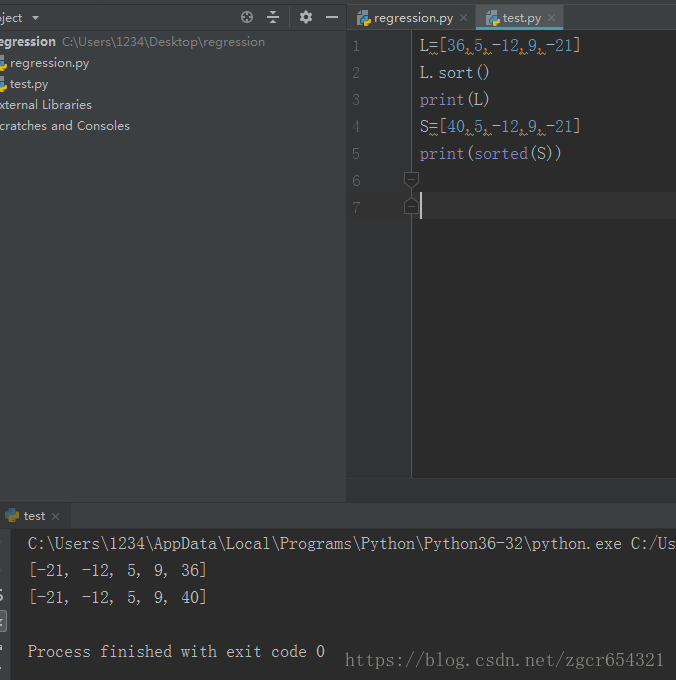
L=[36,5,-12,9,-21]
L.sort()
print(L)
S=[40,5,-12,9,-21]
print(sorted(S))运行截图如下:
sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序。key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。
如按绝对值大小排序:
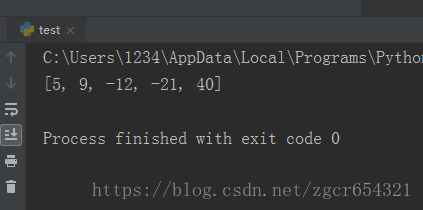
S=[40,5,-12,9,-21]
print(sorted(S,key=abs))
运行截图如下:
默认情况下,如果用sorted()或sort()对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
如:
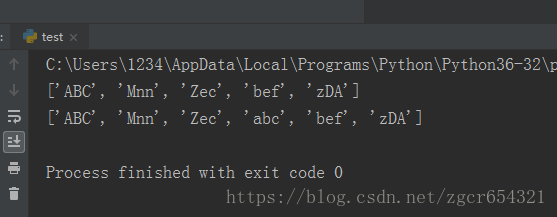
L=['ABC','zDA','bef','Zec','Mnn']
L.sort()
print(L)
S=['ABC','zDA','bef','Zec','Mnn','abc']
print(sorted(S))运行截图如下:
如果上面的排序我们想忽略字母的大小写,那么只要用一个key函数把字符串映射为忽略大小写排序即可。
忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。我们还可以设置reverse=True来实现倒序排序。
如:
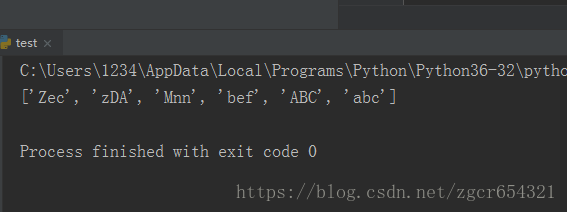
S=['ABC','zDA','bef','Zec','Mnn','abc']
print(sorted(S,key=str.lower,reverse=True))运行截图如下:
返回函数:
函数不仅可以作为函数参数,还可以作为另一个函数的返回结果。
如果在一个内部函数里对外部作用域(但不是全局作用域)的变量进行引用,内部函数称为闭包(closure)。
对于高阶函数,除了可以接受函数作为参数外,还可以把函数作为结果值返回。
如:
def pro1(c,f):
def pro2():
return f(c)
return pro2
a=pro1(-3,abs)
print(a)
运行截图如下:
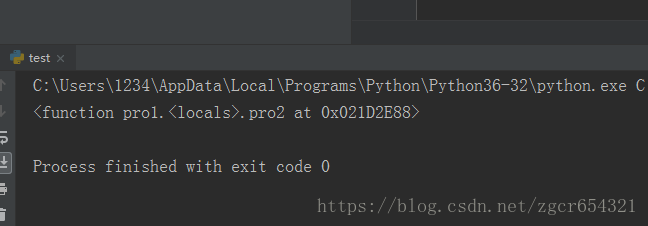
出现上面的结果是因为当我们调用pro1()时,返回的并不是求和结果,而是求和函数。
如何才能计算函数结果呢?
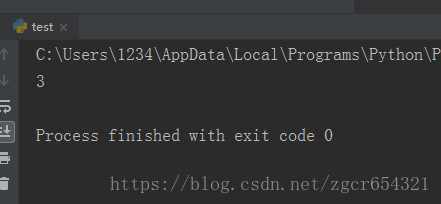
def pro1(c,f):
def pro2():
return f(c)
return pro2
a=pro1(-3,abs)
print(a())
这样才真正调用了函数,计算出结果。
运行截图如下:
在上面的例子中,我们在函数pro1中又定义了函数pro2,并且,pro2可以引用外部函数pro1的参数和局部变量,当pro1返回函数pro2时,相关参数和变量都保存在返回的函数中,这种结构就称为“闭包(Closure)”。
注意:
当我们调用pro1()时,每一次调用都会返回一个新的函数,即使传入的参数相同。
如:
请再注意一点,当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数:
def pro1(c,f):
def pro2():
return f(c)
return pro2
a=pro1(-3,abs)
b=pro1(-3,abs)
print(a==b)运行截图如下:
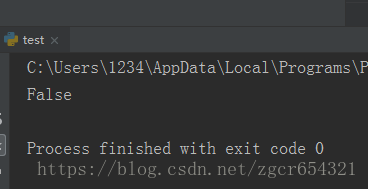
要注意的是,返回的函数并没有立刻执行,而是直到调用了a()才执行。由于这个特性,返回闭包时要牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
我们举个反例:
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
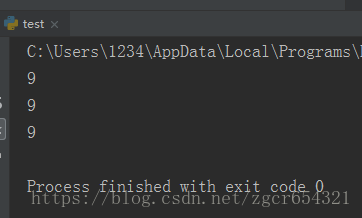
f1, f2, f3 = count()
print(f1())
print(f2())
print(f3())结果全部是9,原因是返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
运行截图如下:
如果一定要用到循环变量,我们可以再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变。
如:
def count():
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
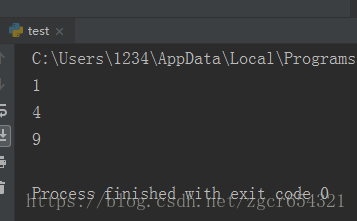
f1, f2, f3 = count()
print(f1())
print(f2())
print(f3())
这次的结果是1,4,9。
运行截图如下:
装饰器:
装饰器本质上是一个返回函数的高阶函数。它可以让其他函数在不需要做任何代码变动的前提下增加额外功能。
如,我们有下面这样一个函数:
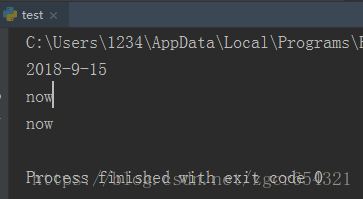
def now():
print('2018-9-15')
f=now
f()
我们知道函数对象都有一个__name__属性,保存了函数的名字,于是我们将函数名字也打印出来:
def now():
print('2018-9-15')
f=now
f()
print(now.__name__)
print(f.__name__)运行截图如下:
假如我们现在想增强now()函数的功能,如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,就叫做“装饰器”(Decorator)。
我们可以定义如下的一个装饰器:
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
观察上面的log函数,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。
我们借助Python的@语法,把decorator置于函数的定义处。把@log放到now()函数的定义处,相当于执行了语句:now = log(now)。
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2018-9-15')
f=now
f()
print(now.__name__)
print(f.__name__)这个时候我们运行这段代码,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志。
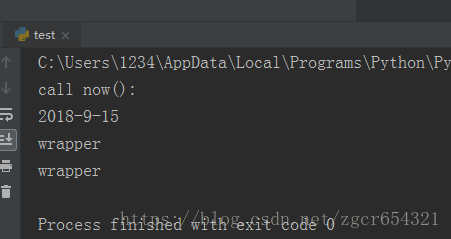
经过decorator装饰之后的函数,它们的__name__属性已经从原来的'now'变成了'wrapper'。因为返回的那个wrapper()函数名字是'wrapper',所以,我们需要把原始函数的__name__等属性复制到wrapper()函数中,否则,有些依赖函数签名的代码执行就会出错。
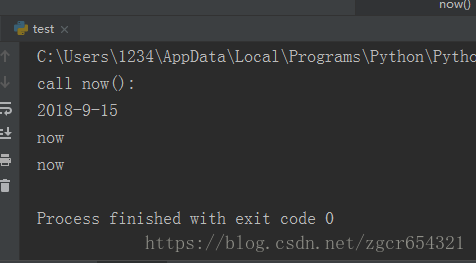
我们不需要编写wrapper.__name__ = func.__name__这样的代码,Python内置的functools.wraps可以完成这件工作,如下:
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2018-9-15')
f = now
f()
print(now.__name__)
print(f.__name__)运行截图如下:
偏函数:
Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。要注意,这里的偏函数和数学意义上的偏函数不一样。
偏函数是Python2.5版本以后引进来的。属于函数式编程的一部分,使用偏函数可以通过有效地“冻结”那些预先确定的参数,来缓存函数参数,然后在运行时,当获得需要的剩余参数后,可以将他们解冻,传递到最终的参数中,从而使用最终确定的所有参数去调用函数。
如:
def add(a, b):
return a + b
print(add(3, 5))
print(add(4, 7))这是我们正常调用函数的情况,那么如果我们知道一个已知的参数a= 100,我们如何利用偏函数呢?
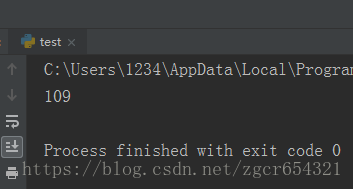
import functools
def add(a, b):
return a + b
puls = functools.partial(add,100)
print(puls(9))运行截图如下:
偏函数表达的意思就是,在函数add调用时,我们已经知道了其中的一个参数,我们可以通过这个参数,重新绑定一个函数,即functools.partial(add, 100),然后调用puls即可。