目标
1) 使用下列方法将一个数组按升序排序:归并排序、快速排序和基数排序
2) 评估排序的效率,讨论不同的方法的相对效率
目录
9.1 归并排序
9.1.1 归并数组
9.1.2 递归归并排序
9.1.3 归并排序的效率
9.1.4 迭代归并排序
9.1.5 Java类库中的归并排序
9.2 快速排序
9.2.1 快速排序的效率
9.2.2 创建划分
9.2.3 实现快速排序
9.2.4 Java类库中的快速排序
9.3 基数排序
9.3.1 基数排序的伪代码
9.3.2 基数排序的效率
9.4 算法比较
小结
排序小数组时,之前的排序算法已经足够了,想排序一个更大的数组,那些算法可能也是一个合理的选择。插入排序是对链式节点链进行排序的好方法。当需要对频繁地对非常大的数组进行排序时,那些方法花时间太多。
9.1 归并排序
归并排序(merge sort)将数组分为两半,分别对两半进行排序,然后将它们合并为一个有序的数组。归并排序算法常常用递归方式来描述。递归常用同一问题的更小版本来表示解决问题的方案。当你将问题划分为两个或多个更小的但独立的问题时,解决每个新问题,然后将它们的方案合并为解决原始问题的方案,这个策略称为分治(divide and conquer)算法。即,将问题划分为小块,然后攻克每个小块以达成解决方案。
当用递归表示时,分治算法含有两个或多个递归调用。
9.1.1 归并数组
归并两个有序数组,只需从头开始处理到末尾,将一个数组中的项与另一个数组中的项进行比较,较小的项复制到新的数组中。
9.1.2 递归归并排序
算法
在归并排序中,归并两个有序数组,实际上它们是原始数组的两半。即,将数组分为两半,排序每一半,然后将这两段有序部分合并到第二个临时数组中,然后将临时数组复制回原始数组中。
归并排序有下列递归形式:
Algorithm mergeSort(a, tempArray, first, last) // 递归地排序数组项a[first]到a[last] if (first < last){ mid = first + (last - first) / 2 mergeSort(a, tempArray, first, mid) mergeSort(a, tempArray, mid+1, last) 使用数组tempArray合并有序的两半a[first…mid]和a[mid_1…last] }
注意:算法没有处理少于或等于一项的数组。
下列伪代码描述了归并步骤
Algorithm merge(a, tempArray, first, mid, last) // 合并相邻的子数组a[first…mid]和a[mid+1…last] beginHalf1 = first endHalf1 = mid beginHalf2 = mid+1 endHalf2 = last // 当两个子数组都不空时,让一个子数组中的项与另一个子数组中的项进行比较 // 然后将较小的项复制到临时数组中 index = 0 // tempArray中下一个可用的位置 while( (beginHalf1 <= endHalf1) 和 (beginHalf2 <= endHalf2) ){ if(a[beginHalf1] <= a[beginHalf2]){ tempArray[index] = a[beginHalf1] beginHalf1++ } else{ tempArray[index] = a[beginHalf2] beginHalf2++ } index++ } // 断言:一个子数组已经全部复制到tempArray中 将另一个子数组中的剩余项复制到tempArray中 将tempArray中的项复制到数组a中
跟踪算法中的步骤
当对数组的两半调用mergeSort时会发生什么。

图 1 递归调用的效果及归并排序过程中的合并
箭头上的数字表示递归调用及合并的次序。第一次合并发生在4次递归调用mergeSort之后及其他递归调用mergeSort之前。所以递归调用mergeSort和merge是交织在一起的。真正的排序是发生在合并步骤而不是发生在递归调用步骤。
注:归并排序在合并步骤中重排数组中的项。
实现说明
注意应该只分配一次临时数组。因为数组是实现细节,所以也许会冒险将空间分配隐藏在方法merge中。但是,因为每次递归调用mergeSort时都会调用merge,所以这个方法会导致分配临时数组及初始化很多次。我们可以在下列共有mergeSort方法中分配一个临时数组,然后将它传给之前给出的伪代码的私有mergeSort方法:
public static <T extends Comparable<? super T>> void mergeSort(T[] a, int first, int last) { // The cast is safe because the new array contains null entries @SuppressWarnings("unchecked") T[] tempArray = (T[])new Comparable<?>[a.length]; // Unchecked cast mergeSort(a, tempArray, first, last); } // end mergeSort
? super T 表示T的任意父类。当我们分配Comparable对象的数组时,使用了通配符?来表示任意的对象。然后将数组转型为类型T对象的数组。
9.1.3 归并排序的效率
一般地,如果n是2k次,就会发生k层递归调用。
合并步骤,真正工作所在。在共有n项的两个子段中,合并步骤最多进行n-1次比较。每次合并还需要向临时数组的n次移动及移回原始数组的n次移动。总计,每次合并最多需要3n-1次操作。
每次调用mergeSort时需要调用merge一次。作为调用mergeSort的结果,合并操作最多需要3n-1次操作。这是O(n)的。两次递归调用mergeSort导致两次调用merge。每次调用最多用3n/2-1次操作合并n/2项。然后两次合并最多需要3n-2次操作。它们是O(n)的。下一层递归调用22次mergeSort,导致4次调用merge。每次调用merge最多3n/22-1次操作合并n/22项。四次合并,最多3n-22次操作,也是O(n)的。
如果n是2k的,则递归调用mergeSort方法的K层,导致进行K层合并。每一层的合并都是O(n)的。因为k是log2n的,所以mergeSort是O(n log n)的。
注意:合并步骤是O(n)的,不管数组的初始状态如何。最坏、最优及平均情形下,归并排序都是O(n log n)的。归并排序的缺点是在合并阶段需要一个临时数组。
另一种评估效率的方法
递推关系:t(n)表示最坏情形mergeSort的时间需求,则两个递归调用的每个需要时间t(n/2),合并步骤是O(n),所以有
| t(n) = t(n/2) + t(n/2) + O(n) = 2 x t(n/2) + O(n) 当n > 1时 t(1) = 0 |
设n猜想再证明
9.1.4 迭代归并排序
为了使用迭代替代递归,我们需要控制合并过程。这样一个算法不管是时间还是空间,都比递归算法更高效,因为它消除了递归调用,所以去掉了活动记录的栈。但迭代归并排序更难写出没有错误的代码。
基本上,迭代归并排序从数组头开始,将一对对的单项合并为含两项的子段。然后返回到数组头,将一对对的两项的子段合并为4项的子段,以此类推。但是,合并某个长度的所有子段对后,可能还剩余若干项。合并这些项时需要格外小心。(可以节省很多将临时数组复制回原始数组所需的时间)
9.1.5 Java类库中的归并排序
java.util包中的类Arrays定义了不同版本的几个静态方法sort,它们用来将数组按升序排序。对于对象数组,sort使用归并排序。方法
public static void sort(Object[] a)
将对象数组a的全部内容进行排序,而方法
public static void sort(Object[] a, int first, int after)
对a[first]到a[after-1]之间的对象进行排序。对于这两个方法,数组中的对象必须定义了Comparable接口。
如果数组左半段中的项都不大于右半段中的项,则这些方法中使用的归并排序会跳过合并步骤。因为两端都已经有序,所以这种情形下合并步骤不是必需的。
注:稳定的排序
如果排序算法不改变相等对象的相对次序,则称为稳定的(stable)。归并排序是稳定的。
9.2 快速排序
另一个使用分治策略的数组排序。快速排序(quick sort)将数组划分为两部分,但与归并排序不同,这两部分不一定是数组的一半。相反,快速排序选择数组中的一项(称为枢轴(pivot))来重排数组项,满足
| 1) 枢轴所处的位置就是在有序数组中的最终位置 2) 枢轴前的项都小于或等于枢轴 3) 枢轴后的项都大于或等于枢轴 |
这个排列称为数组的划分(partition)
创建划分将数组分为两部分,称为较小部分和较大部分,它们由枢轴分开。因为较小部分中的项小于或等于枢轴,而较大部分中的项大于或等于枢轴,所以枢轴位于有序数组中正确且最终的位置上。现在如果对两个子段的较小部分和较大部分进行排序(当然是用快速排序)则原始数组将是有序的。下列算法描述了排序策略:
Algorithm quicksort(a, first, last) // 递归地排序数组项a[first]到a[last] if (first < last){ 选择枢轴 基于枢轴划分数组 pivotIndex = 枢轴的下标 quicksort(a, first, pivotIndex - 1) // 排序较小值部分 quicksort(a, pivotIndex + 1, last) // 排序较大值的部分 }
9.2.1 快速排序的效率
注意,创建划分(它完成了quickSort的大部分工作)在递归调用quickSort之前进行。这一点与归并排序不同,它的大部分工作是在递归调用mergeSort之后的合并步骤完成的。划分过程需要不超过n次的比较,故与合并一样,它将是O(n)的任务。
当枢轴移动到数组的中心时是理想情形,这样划分的两个子数组有相同的大小。如果对quickSort的每次递归调用都划分了相等大小的子数组,则快速排序与归并排序一样递归调用数组的两半。所以快速排序将是O(n log n)的,这是最优情形。
最坏情形下,每次划分都有一个空子段,另一个调用必须排序n-1项。结果是n层递归调用而不是log n层。所以最坏情形下,快速排序是O(n2)的。
枢轴的选择将影响快速排序的效率。如果数组已经有序或接近有序,有些选择枢轴的机制可以导致最坏情形。实际上,出现接近有序数组的情形,可能会更频繁。
快速排序在平均情形下是O(n log n)的,归并排序总是O(n log n)的,而实际上,快速排序可能比归并排序更快,且不需要归并排序中合并操作所需的额外内存。
9.2.2 创建划分
枢轴与最后一项交换。
等于枢轴的项
注意,在较小部分和较大部分子数组中,都可能含有等于枢轴的项。为什么不总是将等于枢轴的项放到同一个子段中呢?这样的策略能让一个子段大于另一个。但是,为了提升快速排序的性能,让子数组尽可能地等长。
注意,从左至右的查找和从右至左的查找,在它们遇到等于枢轴的项时都会停止。这意味着,这样的项不是放在原地,而是要进行交换。也意味着,这样的项有机会放在任何一个子数组中。
枢轴的选择
理想地,枢轴应该是数组的中位值,所以较小部分和较大部分子数组都有相等(或接近相等)的项数。找到中位值的一种方法是排序数组,然后选择位于中间的值,但数组排序是原始问题,所以这个思路不行。
选择枢轴需要不花太多时间,所以至少应该避开坏的枢轴。所以不是去找数组的中位值,而是找到数组中这3个项的中位值:第一项、中间项及最后一项。一个办法是仅将这3个值进行排序,使用这3个值的中间值作为枢轴。这个选择策略称为三元中值枢轴选择(median-of-three pivot selection)。
注:三元中值枢轴选择避免了快速排序当给定数组已经有序或接近有序时的最坏情形性能。但理论上,不能避免其他情况下数组的最坏性能,这样的性能在实际中不太可能出现。
修改划分算法
三元中值枢轴选择说明,对划分机制要做小的修改。之前枢轴与数组最后一项交换,因为现在已知最后一项至少大于等于枢轴,所以最后一项不动,将枢轴与倒数第二项交换。所以,划分算法从下标last – 2处开始从右至左的查找。
同样,第一项直多等于枢轴,所以也不动,划分算法从下标first+1开始从左至右的查找。
这个机制使得进行两个查找的循环简单了。从左至右的查找查看大于等于枢轴的项。这个查找将会停止,因为它至少会停在枢轴处,从右至左的查找查看小于或等于枢轴的项。这个查找将会停止,因为至少会停在第一项。所以循环不需要为阻止查找越出数组边界而做什么特殊的事情。
查找循环停止后,必须将枢轴放到较小部分和较大部分的中间。通过交换a[indexFromLeft]和a[last - 1]处的项可做到这一点。
注:快速排序在划分过程中重排数组中的项。每次划分都将一个项(枢轴)放在其正确的有序位置。在两个子数组中位于枢轴之前和之后的项仍留在各自的子数组中。
9.2.3 实现快速排序
枢轴的选择
可以通过私有方法,简单的比较及交换完成第一项、中间项、最后一项的比较。
// Sorts the first, middle, and last entries of an array into ascending order. private static <T extends Comparable<? super T>> void sortFirstMiddleLast(T[] a, int first, int mid, int last)
划分
若数组小于三项,则已经排好,所以不需要划分或快排,所以下列划分算法假设数组至少有四项:
Algorithm partition (a, first, last) // 作为快速排序的一部分,划分将数组a[first...last]分为两个子数组 // 分别称为Smaller 和 Larger,它由一个项(枢轴),名为pivoValue,分隔开。 // Smaller 中的项 ≤ pivotValue, 且位于数组中pivotValue 值的前面 // Larger 中的项 ≥ pivotValue, 且位于数组中pivotValue 值的后面 // first >= 0; first < a.length; last - first >= 3; last < a.length // 返回枢轴的下标
mid = 数组中间项的下标 sortFirstMiddleLast(a, first, mid, last) // 断言:a[first] <= pivotValue 且 a[last] >= pivotValue, 所以数组的这两项不与pivotValue进行比较 // 将 pivotValue移到数组中倒数第二个位置 交换 a[mid] 和a[last - 1] pivotIndex = last - 1 pivotValue = a[pivotIndex]
// 判断两个子数组: // Smaller = a[first...endSamller] 且 // Larger = a[endSmaller+1...last-1] // 这样,Smaller 中的项都 <= pivotValue, 且 // Larger 中的项都 >= pivotValue // 初始时,这些子数组都是空的 indexFromLeft = first + 1 indexFromRight = last - 2 done = false while (!done) { // 从数组头开始,留下 < pivotValue 的项, // 找到 >= pivotValue 的第一个项。一定能找到一个, // 因为最后一项 >= pivotValue while (a[indexFromLeft] < pivotValue) indexFromLeft++
// 从数组尾开始,留下 > pivotValue 的项, // 找到 <= pivotValue 的第一个项 // 一定能找到一个,因为第一个项 <= pivotValue while (a[indexFromRight] > pivotValue) indexFromRight--
// 断言:a[indexFromLeft] >= pivotValue 且 // a[indexFromRight] <= pivotValue if (indexFromRight > indexFromLeft) { 交换 a[indexFromLeft] 和 a[indexFromRight] indexFromLeft++ indexFromRight-- } else done = true } // 将 pivotValue 放到子数组 Smaller 和 Larger 之间 交换 a[pivotIndex] 和 [indexFromLeft] pivotIndex = indexFromLeft // 断言:Smaller = a[first...pivotIndex-1] // pivotValue = a[pivotIndex] // Larger = a[pivotIndex+1...last] return pivotIndex
快速排序方法
即使是对大数组进行划分,最终也会导致递归调用时涉及仅有两项的小数组。快速排序的代码必须筛选出这些小数组,并使用其他方法来排序它们。插入排序是小数组的好选择。实际上,对于含10项的数组,使用插入排序替代快速排序都是合理的。实现如下:
/** * Sorts an array into ascending order. Uses quick sort with * median-of-three pivot selection for arrays of at least * MIN_SIZE entries, and uses insertion sort for smaller arrays. */ public static <T extends Cpmaprble<? super T>> void quickSort(T[] a, int first, int last) { if (last - first + 1 < MIN_SIZE) { insertionSort(a, first, last) } else { // Create the partition: Smaller | pivot | Larger int pivotIndex = partition(a, first, last); // Sort subarrays Smaller and Larger quickSort(a, first, pivotIndex - 1); quickSort(a, pivotIndex + 1, last); } // end if } // end quickSort
9.2.4 Java类库中的快速排序
包Java.util中的类Array使用快速排序对基本类型的数组进行升序排序。方法
public static void sort(type[] a)
对整个数组a进行排序,而方法
public static void sort(type[] a, int first, int after)
对从a[first] 到a[after-1]的项进行排序。注意,type可以是byte、char、double、float、int、long 或 short 类型。
9.3 基数排序
到目前为止,这些排序算法对可比较的对象进行排序。基数排序(radix sort)不使用比较,但为了能进行排序,它必须限制排序的数据。对于这些受限的数据,基数排序是O(n)的,故它快于之前的任何一种排序方法。但是,它不适合作为通用的排序算法,因为它将数组项看做有相同长度的字符串。
基数排序需要相同的长度,不足的前面补0(对于数字来说),先按照最后一位比较,再按照倒数第二位比较,以此类推,最后用第一位比较,过程如下:
对10个数进行排序:123, 398, 210, 019, 528, 003, 513, 129, 220, 294
先按最右边的数字分组,将123放入3号桶,210放入0号桶,放完再移回数组,再按照中间数组分桶。
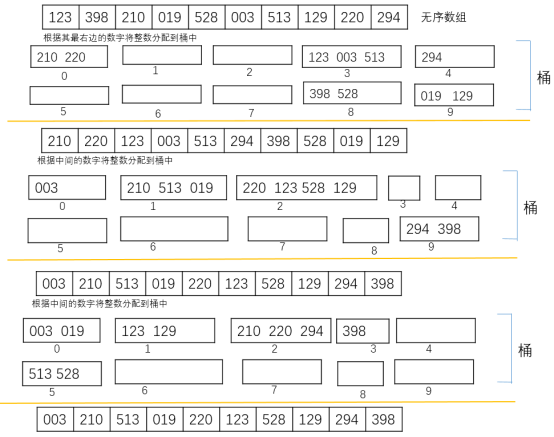
9.3.1 基数排序的伪代码
下列算法描述了对正的十进制整数数组的基数排序。从0开始对每个整数从右到左标记各位。所以,个位数字是数字0,十位数字是数字1,以此类推。
Algorithm radixSort(a, first, last, maxDigits) // 升序排序十进制正整数数组a[first…last]; // maxDigits 是最长整数的数字位数 for (i = 0 to maxDigits - 1){ 清空 bucket[0], bucket[1],…, bucket[9] for (index = first to last){ digit = digit I of a[index] 将 a[index] 放到 bucket[digit] 的最后 } 将 bucket[0], bucket[1], …, bucket[9] 放回数组a 中 }
算法用到了桶的数组。没有指定桶的特性。
9.3.2 基数排序的效率
如果数组含有n个整数,则前一个算法中的内层循环迭代n次。如果每个整数含有d位,则外层循环迭代d次。所以基数排序是O(d x n)的。表达式中的d说明,基数排序的实际运行时间依赖于整数的大小。但在计算机中,一般的整数最大不超过10位十进制数,或32个二进制位。当d固定且远小于n时,基数排序仅仅是O(n)的算法。
注:虽然基数排序对某些数据是O(n)的算法,但它不适用于所有数据。
9.4 算法比较
虽然基数排序是最快的,但它并不总能使用。一般来说归并排序和快速排序比其他算法快。如果数组含有相对较少的项,或者如果接近有序,则插入排序是好的选择。另外,一般来讲快速排序是可取的。注意,当数据集合(collection)太大,不能全部放到内存而必须使用外部文件时,可以使用归并排序。另一个排序——堆排序,也是O(n log n)的,但快排更可取。
| 平均情形 |
最优情形 |
最坏情形 |
|
| 基数排序 |
O(n) |
O(n) |
O(n) |
| 归并排序 |
O(n log n) |
O(n log n) |
O(n log n) |
| 快速排序 |
O(n log n) |
O(n log n) |
O(n2) |
| 希尔排序 |
O(n1.5) |
O(n) |
O(n2)或O(n1.5) |
| 插入排序 |
O(n2) |
O(n) |
O(n2) |
| 选择排序 |
O(n2) |
O(n2) |
O(n2) |
对比各增长速度
| n |
10 |
102 |
103 |
104 |
105 |
106 |
| n log2 n |
33 |
664 |
9966 |
132877 |
1660964 |
19931569 |
| n1.5 |
32 |
103 |
31623 |
106 |
31622777 |
109 |
| n2 |
102 |
104 |
106 |
108 |
1010 |
1012 |
小结
| 1) 归并排序是分治算法,它将数组分半,递归地排序两半,然后将它们合并为一个有序数组 2) 归并排序是O(n log n)的。但是它需要用到额外的内存来完成合并过程 3) 快速排序是另一种分治算法,它由一项(枢轴)将数组划分为分开的两个子数组。枢轴在其正确的有序位置上。一个子数组中的项小于或等于枢轴,而第二个子数组中的项则大于或等于枢轴。快速排序递归的对两个子数组进行排序 4) 大多数情况下,快速排序是O(n log n)的。虽然最坏的情况下是O(n2)的,但通常选择合适的枢轴可以避免这种情况 5) 即使归并排序和快速排序都是O(n log n)的算法,但在实际中,快速排序通常更快,且不需要额外的内存 6) 基数排序将数组项看做有相同长度的字符串。初始时,基数排序根据字符串一端的字符(数字)将项分配到桶中,然后排序收集字符串,并根据下一个位置的字符或数字将它们再次分配到桶中。继续这个过程,直到所有的字符位置都处理过为止 7) 基数排序不对数组项进行比较。虽然它是O(n)的,但它不能对所有类型的数据进行排序。所以它不能用作通用的排序算法。 |