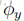我们已经描述过的朴素贝叶斯算法能够很好地解决许多问题,但是有一个简单的改变使得它更好地工作,特别是对于文本分类。让我们简单地讨论算法在当前形式下的问题,然后讨论如何修复它。
考虑垃圾邮件/电子邮件分类,让我们假设在完成CS229并完成了对项目的出色工作之后,您决定在2003年6月左右将您所做的工作提交给NIPS会议以供发表。因为您在电子邮件中最终讨论了会议,因此您还可以开始使用其中的“NIPS”一词来获取消息。但这是你的第一份 NIPS 邮件,在此之前,你还没有见过任何包含“nips”这个词的电子邮件;特别是,“nips”从来没有出现在你的培训集的垃圾邮件/非垃圾邮件。假设“nips”是字典中的第35000个单词,那么您的朴素贝叶斯垃圾邮件过滤器就选择了参数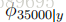

也就是说,因为它以前从未在垃圾邮件或非垃圾邮件培训示例中见过“nips”,它认为在两种类型的电子邮件中看到“nips”的概率都是零。因此,当试图确定其中一个包含“nips”的消息是否是垃圾邮件时,它会计算类后验概率,并获得
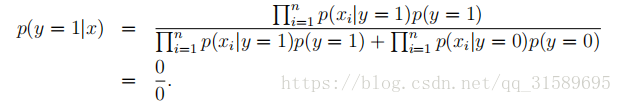
注意上面的分母相当于<机器学习实战>第四章中的p(w),分子则相当于p(w|c1)·p(c1)
这是因为每一个术语

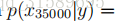
更广泛地说明这个问题,从统计学上来说,估计某个事件的概率为零是个坏主意,仅仅因为你以前还没有在有限的训练集中看到过它。取{1,…,k}中取值的多项式随机变量z的均值问题。我们可以用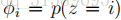
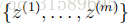
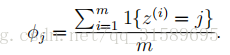
正如我们之前看到的,如果我们使用这些最大似然估计,那么一些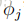
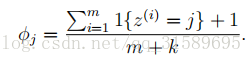
在这里,我们把1加到分子上,把k加到分母上。注意,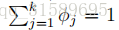

返回到我们的朴素贝叶斯分类器,通过拉普拉斯光顺,我们得到了以下参数的估计:
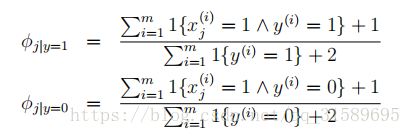
(在实践中,我们是否将laplace光顺应用于