在学习神经网络的时候,你会经常听到一个词:激活函数。在最开始学习的时候,对激活函数总是有很多的疑惑。在日常搭建网络的时候选择激活函数也是很随意,看到大家都说ReLU效果好,就一股脑使用ReLU。通常没去深究一些问题:
- 激活函数到底是什么?
- 为什么要使用激活函数?
- 常用的激活函数有哪些?
- 这些激活函数使用于哪些场景?
本文基于这些问题,对激活函数进行介绍分析。
1. 什么是激活函数?
激活函数可以理解为时一种非线性转化,在神经元对输入加权求和之后,再经过一个函数计算后输出。这个函数就是激活函数。并非所有的函数都可以作为激活函数的,激活函数需要满足以下几点性质:
- 非线性:当激活函数是非线性函数时,一个两层的神经网络就可以去逼近绝大多数函数了。但是如果激活函数是线性的话,我们的网络始终只能学习出线性的关系出来。而无法去学习出复杂的非线性关系。
- 单调性:在激活函数是单调的时,我们可以保证单层网络是凸的。
- 可微性:在我们使用基于梯度的优化方法时,我们需要要求我们的激活函数是可微的。因为在反向传播更新梯度时,我们需要求损失函数对权重的偏导数。因此此时要求我们的激活函数是可微的。
2. 为什么要使用激活函数?
前面已经提到了,如果我们不使用激活函数,那么我们的网络永远都是输入的一个线性加权的组合,无法去模拟非线性的关系。这样网络的能力就受到限制。如果使用了非线性的激活函数,仅仅需要两层网络,我们就可以模拟大部分的非线性的关系了。因此,激活函数的在神经网络中起到了至关重要的作用。
3. 常用的激活函数有哪些?
3.1 sigmoid函数
sigmoid函数是最早提出的十分常用的一种激活函数,它的数学表达式如下所示:
σ(x)=11+e−x
它的函数图像如下图所示:
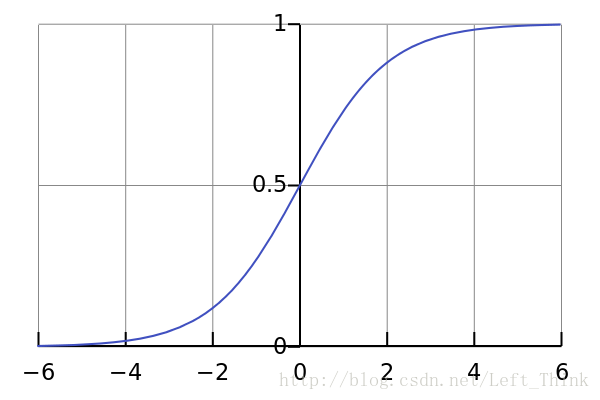
从图像中我们可以看出,它的输出区间在[0,1]之间,因此也常常用于二分类的问题。但是它有几个非常致命的缺点,导致大家不在经常使用它作为激活函数了。
- 饱和性:观察sigmoid函数的图像,我们可以看出在函数的两端处,也就是输出接近0或者输出接近1的地方,图像十分平缓,在这些区域sigmoid函数的梯度接近于0。这会导致一个什么问题呢?在网络进行反向传播时,会涉及到激活函数的导数,当我们样本输出在接近0或1的区域时,此时梯度式接近于0的,而当面对深度神经网络时,多个接近于0的梯度相乘会产生梯度消失的现象,这会导致我们训练可能不收敛。因此我们在使用sigmoid函数作为激活函数时,要当心初始化。一旦初始化得不好,我们的模型可能收敛的很慢甚至不收敛。
- sigmoid函数的复杂性:由于sigmoid函数涉及到除法和指数计算,在我们网络正向传播是指数运算计算复杂,而在反向传播时,除法求导较为复杂。
- 输出空间的非对称性:可以看到,sigmoid函数的输出域为[0,1],它不是关于0对称的。这会导致一个什么问题呢?当我们的输入如果全是正数时,我们在反向传播时,下降的梯度也是正数;当我们输入全是负数时,我们反向传播时,下降的梯度也时负数。因此会导致梯度更新权重是按照z字型下降的。但是这个问题我们可以一次训练一个batch的数据,这样就可以避免输入全是正数或者负数的现象。
那sigmoid激活函数使用于什么场景呢?在特征相差比较复杂或是相差不是特别大时,使用sigmoid效果比较好。
3.2 tanh函数
tanh函数可以看成是sigmoid函数的变形,它的函数表达式如下所示:
tanh(x)=2sigmoid(2x)−1=ez−e−zez+e−z
函数图像为
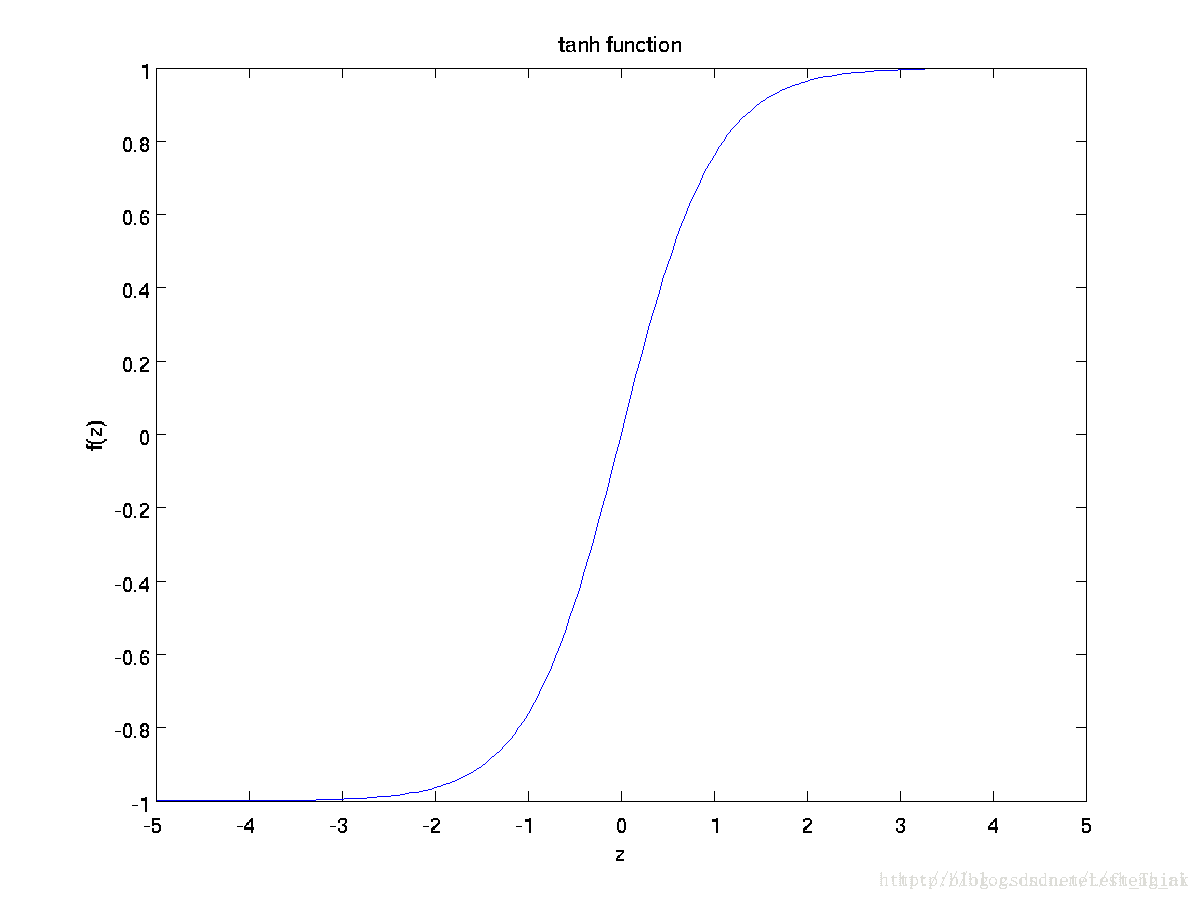
tanh函数相比于sigmoid函数来说,它是关于原点对称的了。但是还是会存在着计算复杂,以及梯度消失的问题。
tanh函数在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。
3.3 ReLu函数
ReLu函数的数学表达式为:
ReLu(x)=max{0,x}
ReLu函数的图像为:
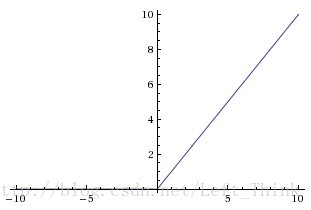
通过观察ReLu函数的图像我们可以得到ReLu的一些性质:
- 在输入大于0时,此时激活函数的导数恒等于1,因此不会出现饱和的现象。但是在输入小于0时,此时为硬饱和。
- ReLu是线性的,它只用将神经元的输出与某个阈值做比较,如果大于阈值,则输出神经元的输出,否则输出为0。因此无论是在正向传播还是反向传播的计算中都十分便捷。
- ReLu在训练的过程中会造成神经元的死亡。为什么会造成这种情况呢?举个例子:当在反向传播时,如果此时流进网络的梯度很大,如果权重系数被更新成很大的负数后,此时很多输入经过该神经元输出都会是0。此时就落入了硬饱和区域了。而这个神经元的梯度将一直都是0。要解决这个问题就是要在设置学习率的时候,尽量不要设置太大的学习率,这样可以有效的避免神经元的失活
对于激活函数的选用,可以根据神经网络的用途及其场景,再加上对于激活函数的值域的了解,大致可以选定适合对应用途以及场景的激活函数
例如,对于分类器,最终输出的是输入样本,在某一类上的可能性(概率),而概率值一般在[0,1]之间,因而最后一层输出的时候,可以选用值域在[0,1]之间的激活函数,比如说sigmoid函数。诸如此类的问题,可以根据值域来选择激活函数的运用,下列是一些常见的激活函数,及其函数图像,我会不定期的添加我遇到的一些新的激活函数。
1.sigmoid激活函数
函数的定义为:
值域为(0,1)
函数图像如下:
2.tanh激活函数
函数的定义为:
值域为(-1,1)
函数图像如下:
3.Relu激活函数
来源: Nair V, Hinton G E. Rectified linear units improve restricted boltzmann machines[C]//Proceedings of the 27th international conference on machine learning (ICML-10). 2010: 807-814.
R Hahnloser, R. Sarpeshkar, M A Mahowald, R. J. Douglas, H.S. Seung (2000). Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature. 405. pp. 947–951
函数的定义为:
f(x) = max(0, x)
值域为[0,+∞)
函数图像如下:
4.Leak Relu激活函数
函数定义为:
值域为(-∞,+∞)
图像如下(α为0.5的情况)
5. SoftPlus激活函数
函数的定义为:
值域为(0,+∞)
函数图像如下:
6.Soft Max
函数定义为:
定义域为R
值域为[0,1]
7.Maxout
来源:Goodfellow I J, Warde-Farley D, Mirza M, et al. Maxout networks[J]. arXiv preprint arXiv:1302.4389, 2013.
函数定义为:
值域(-∞,+ ∞)