文章目录
感知机是什么
- 感知机接受多个信号,输出一个信号。感知机是具有输入和输出的算法。感知机的信号只有“流”和“不流”(0/1)两种取值。下图是一个二输入的感知机:

- 用数学公示表示为:

其中w1,w2分别是输入信号x1,x2的权重,权重越大,对应该权重的信号的重要性就越高;
θ是阈值,只有当输入信号的总和>阈值时,才会输出1,也成为神经元被激活。 - 将阈值θ,改为偏置-b后(不要问我为什么改,其实原理一样就是换一种说法,把阈值变成了人们通常用来描述感知机的名词偏置),就可以表示为下式:

- 感知机会计算输入信号与权重的乘积,并加上偏置,如果得到的值>0则输出1,否则输出0;
- 权重是控制输入信号重要性的参数,偏置是调整神经元被激活的容易程度的参数
感知机的局限性
线性空间和非线性空间
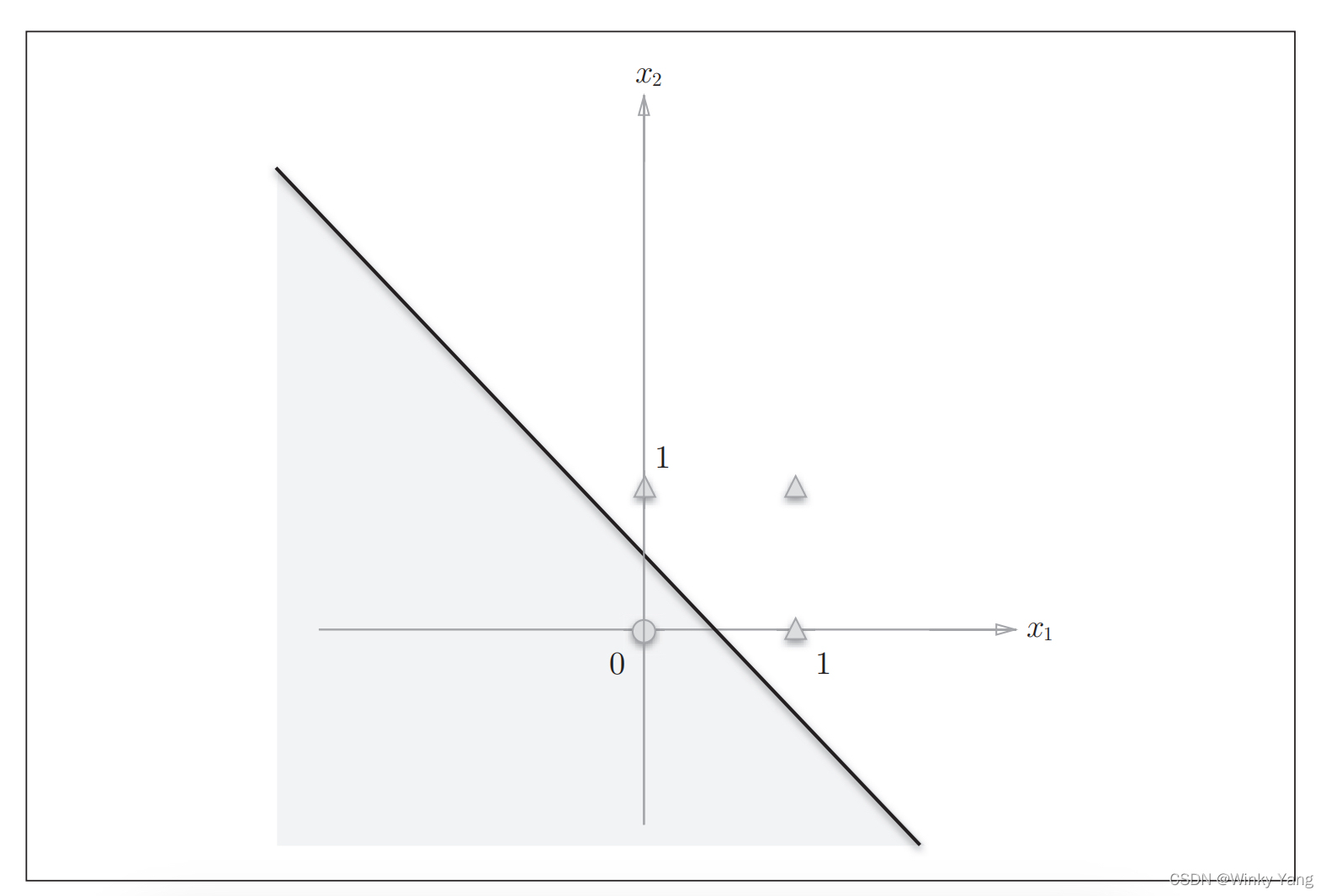
可以由直线分割而成的空间为线性空间,如下图:
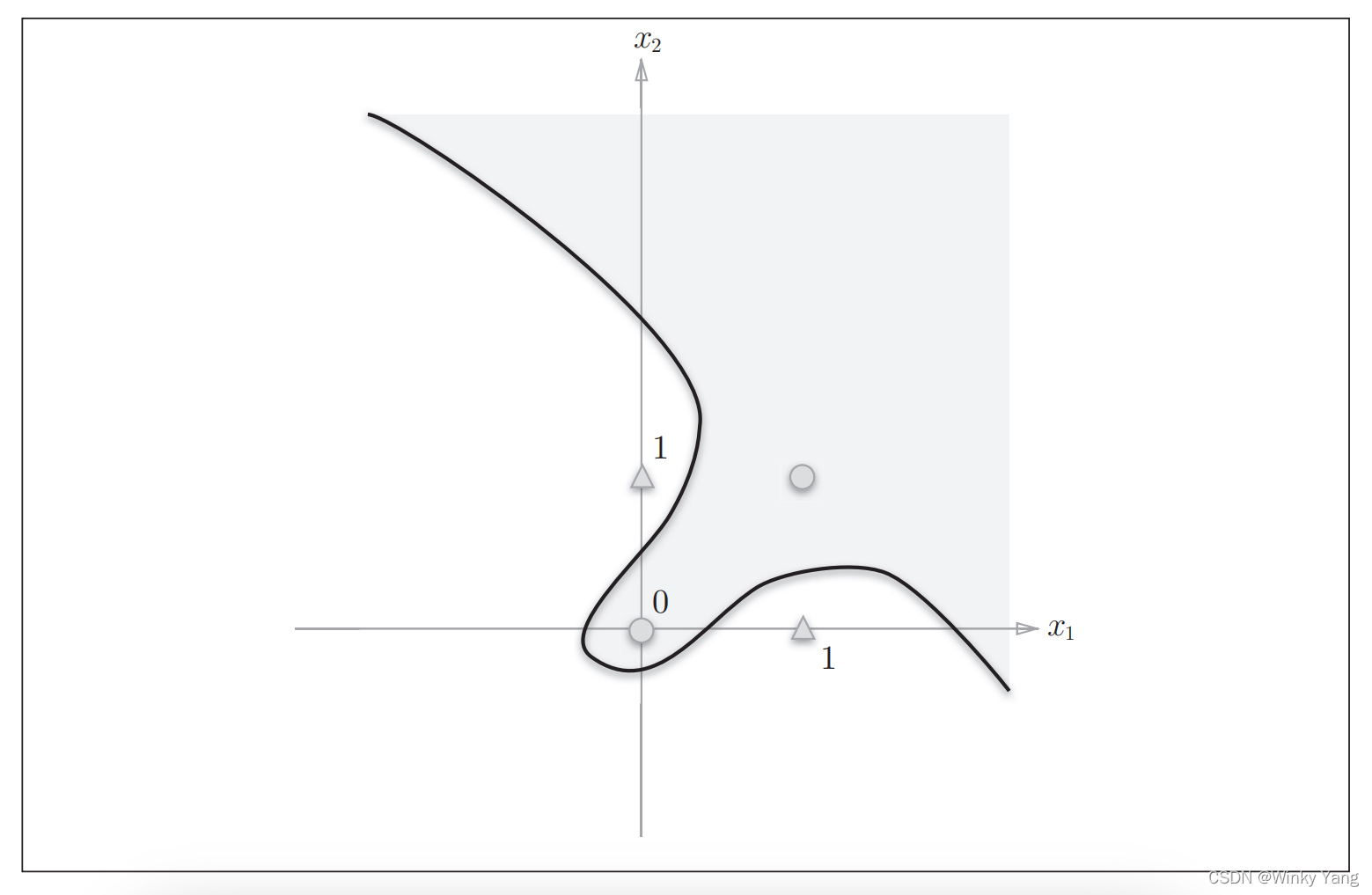
由曲线分割的空间称为非线性空间,如下图:
感知机的局限性
单一的感知机只能表示由一条直线分割的空间(从数学公式就可以看出来),即单层感知机无法分离非线性空间
克服局限性
感知机通过叠加层能够进行非线性表示,就是多层感知机叠加,这里以感知机实现异或门来举例,可以看到上图的非线性空间表示的是一个异或门(两个输入不一样的时候输出为1,两个输入压抑感的时候输出为0),当感知机按照如下的两层进行链接,即可表示异或门:

用表格查看输入输出的对应关系:

激活函数的意义:从感知机到神经网络——差别在于激活函数
终于讲到激活函数了,多层感知机可以表示非线性空间,但是多层感知机网络中流动的只有0和1,而神经网络中流动的是连续的实数值信号,不限于0和1这样的两个值,所以神经网络和感知机的区别总结来说就是:
- 神经网络是加入了非线性激活函数的多层感知机
- 感知机是激活函数为阶跃函数的神经网络
激活函数
什么样的函数可以作为激活函数
- 非线性函数
神经网络的激活函数都是非线性函数,非线性函数是指不想线性函数那样呈现一条直线的函数; - 为什么不能是线性函数
因为使用线性函数,加深神经网络的层数就变得没有意义;
线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层”的神经网络(隐藏层也称为中间层,就是神经网络中非输入层也非输出层的那些层都叫隐藏层/中间层)
例如:
h ( x ) = c x h(x)=cx h(x)=cx(c为常数)是一个线性函数,将三层由 h ( x ) = c x h(x)=cx h(x)=cx作为激活函数的神经网络层叠加得到 y ( x ) = h ( h ( h ( x ) ) ) = c ∗ c ∗ c ∗ x = c 3 x = a x ( a = c 3 ) y(x)=h(h(h(x)))=c*c*c*x=c^3x=ax(a=c^3) y(x)=h(h(h(x)))=c∗c∗c∗x=c3x=ax(a=c3)
所以为了发挥叠加层的优势,激活函数必须使用非线性函数
对激活函数需要了解到什么程度
看了很多地方在讲激活函数,这里总结一下,在训练的时候他们有什么区别,什么时候用什么激活函数,我认为需要对于激活函数需要掌握以下几点:
- 激活函数需要满足哪些条件才是一个优秀的激活函数
- 常见的激活函数有哪些
- 激活函数各自的优缺点和克服各自缺点的方法
- 在不同场景下通常用什么激活函数
设计激活函数时需要考虑什么
- 激活函数需要满足哪些条件
激活函数是用来增强网络的表示能力和学习能力的,具备一下性质的激活函数是一个优秀的激活函数:- 连续并可导(允许少数点上不可导),可导的激活函数可以直接利用数值优化的方法来学习网络参数(数值优化就是指常见的随机梯度下降(SGD)等算法,这些算法都需要用到激活函数的导数)
- 激活函数及其导数要尽可能简单一些,太复杂不利于提高网络计算率(正向传播的时候需要直接求导数,如果导数运算太复杂,会降低网络的计算效率)
- 激活函数的导函数值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性(梯度如果接近于0,出现梯度消失,或者梯度爆炸,具体的例子可以见Sigmiod函数的缺陷)
- 在设计激活函数时应考虑的几个问题
- 激活函数在输入域内单调连续
- 输出最好以0为中心,会使收敛速度快
- 输出最好不存在饱和,可以解决梯度消失
- 函数易求导
常见的激活函数及其优缺点和应用场景
常见的激活函数有Sigmiod, ReLU等,这里主要讲之前最流行的Sigmoid和近几年用的比较多的ReLU

Sigmoid型函数
常用的sigmoid型函数有Logistics函数和Tanh函数("S"型函数,两端饱和)

Logistic

优点
- 该函数是把一个实数域的输入“挤压”到区间(0,1)
- 当输入值在0附近时,Sigmoid型函数近似为线性函数;当输入值靠近两端时,输入被抑制
- Logistic函数是连续可导的,其数学性质较好
- 其输出直接可以看作是概率分布,使神经网络可以更好地和统计学习模型进行结合
- 可以看作是一个软性门(Soft Gate),用来控制其他神经元输出信息的数量(是指赋予其他神经元一个权重,使不同神经元在不同程度上影响下一级的输入,这里我觉得可以理解为提供软性注意力机制中的权重)
- 插入一个问题:
这里提到的软性们,让我想到了门机制和注意力机制的理解(待续之后会写一下这个的笔记)
缺点
- 激活函数计算量大,在正向传播包含幂运算和乘法(ReLU使这个缺点被克服)
- 梯度消失和梯度爆炸(ReLU也解决了这个问题)
如果初始化神经网络的权值在[0, 1]之间的随机值,由反向传播算法的数学推导可知,梯度从后向前传播时,每传递一层梯度值都会减小为原来的0.25倍( [公式] ),如果神经网络的隐藏层特别度,那么梯度在穿过多层后将会变得非常小并接近0,即出现梯度消失现象,当网络的初始值设为(1,+∞)区间内的值时,则会出现梯度爆炸的情况(Logistic函数一般更容易出现梯度消失,对logistic函数导数最大为0.25,除非初始权重值>4即初始权重*导数>1时才会导致梯度爆炸) - Logistic的输出不是0均值/中心化(zero-centered),这会导致后一层的神经源将得到上一层输出的非0均值的信号作为输入,随着网络的加深,会改变数据的原始分布(Tanh解决了这个问题—zero-centered是什么意思见如下Tanh函数)
Tanh

Tanh函数和Logistic的最大区别在于
Tanh函数的输出是零中心化的(Zero—Centered),而Logistic函数的输出恒大于0
非零中心化的输出会使得其后一层的神经元输入发生偏置位移(Bias Shift)(指后边所说的z字形锯齿状变化),并进一步使得梯度下降的收敛速度变慢
非零中心化所带来的影响是什么
神经网络的反向传播基本都是基于梯度下降的,比如某一层的激活函数是非零中心化的,比如Logistic函数后面所有的神经网络层所接受的数据都是正数,在反向传播时,关于权重w的梯度将一直保持大于0(或者一直小于0),这会导致在权重更新过程不会那么“顺滑”,而是“z”字形锯齿状变化。如图:

理解:
如果沿绿色线更新,w1的权重是负的,w2的权重是正的
红色线w1和w2的权重都是正的
应用场景
在一般的二元分类问题中,Tanh函数用于隐藏层,而logistic函数用于输出层,但这并不是固定的,需要根据特定问题进行调整
ReLU(Rectified Linear Unit 线性修正单元)

优点
- ReLU的神经元只需要进行加、乘和比较操作,计算更加高效。
- ReLU函数具有很好的稀疏性(约有一半的值未激活),而Sigmoid函数不具有稀疏性,稀疏性可以很好的避免过拟合。
- 相比于Sigmoid的两端饱和,ReLU为左饱和函数,在x>0时导数为1,一定程度上缓解了神经网络梯度消失的问题,加速梯度下降的收敛速度。
缺点
- ReLU函数的输出是非零中心化,影响了梯度下降的效率(之后为了改进这个问题提出了指数线性单元(Exponential Linear Unit,ELU)是一个近近似的零中心化的非线性函数)。
- ReLU神经元在训练时比较容易“死亡”(大约一半的值未激活),但这也是它稀疏性的来源。
- 神经元为什么会死亡:
如果梯度太大,而学习率又不小心设置得太大,就会导致权重一下子更新过多,就有可能出现这种情况:对于任意训练样本x输入网络 ,网络的输出(输入样本*权重)都是小于0的,这样这个神经元的参数就不会再更新,就说该神经元死了
- 神经元为什么会死亡:
- 如果参数在第一次不恰当更新后,第一个隐藏层中的某个ReLU神经元在所有训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是0,在以后训练过程中永远不会被激活,称为死亡ReLU问题,并且可能发生在其他隐藏层。(之后为了改进这个问题提出了带泄露的ReLU(Leaky ReLU)输入 下 x < 0 x<0 x<0时,保持一个很小的梯度 λ λ λ。即使神经元非激活时也能有个非零梯度可以更新参数,避免永远不能被激活)
应用场景
对于是分类任务的输出层,二分类的输出层的激活函数常选择Logistic(Sigmoid)函数,多分类的输出通常都是Softmax层(之后会写文章来讲这个);对于隐藏层的激活函数通常会选择使用ReLU函数,保证学习效率