全连接层到底什么用?
来自链接:https://www.zhihu.com/question/41037974/answer/150522307
- 全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽(注1)。
- 目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代FC的网络通常有较好的预测性能。具体案例可参见我们在ECCV'16(视频)表象性格分析竞赛中获得冠军的做法:「冠军之道」Apparent Personality Analysis竞赛经验分享 - 知乎专栏 ,project:Deep Bimodal Regression for Apparent Personality Analysis
- 在FC越来越不被看好的当下,我们近期的研究(In Defense of Fully Connected Layers in Visual Representation Transfer)发现,FC可在模型表示能力迁移过程中充当“防火墙”的作用。具体来讲,假设在ImageNet上预训练得到的模型为
,则ImageNet可视为源域(迁移学习中的source domain)。微调(fine tuning)是深度学习领域最常用的迁移学习技术。针对微调,若目标域(target domain)中的图像与源域中图像差异巨大(如相比ImageNet,目标域图像不是物体为中心的图像,而是风景照,见下图),不含FC的网络微调后的结果要差于含FC的网络。因此FC可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。(冗余的参数并不一无是处。)

注1: 有关卷积操作“实现”全连接层,有必要多啰嗦几句。
以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:
“filter size = 7, padding = 0, stride = 1, D_in = 512, D_out = 4096”
经过此卷积操作后可得输出为1x1x4096。
如需再次叠加一个2048的FC,则可设定参数为“filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。
来自:https://www.cnblogs.com/jyxbk/p/7879834.html
卷积层(Convolution)
关于卷积层我们先来看什么叫卷积操作: 下图较大网格表示一幅图片,有颜色填充的网格表示一个卷积核,卷积核的大小为3*3。假设我们做步长为1的卷积操作,表示卷积核每次向右移动一个像素(当移动到边界时回到最左端并向下移动一个单位)。卷积核每个单元内有权重,下图的卷积核内有9个权重。在卷积核移动的过程中将图片上的像素和卷积核的对应权重相乘,最后将所有乘积相加得到一个输出。下图经过卷积后形成一个6*4的图。

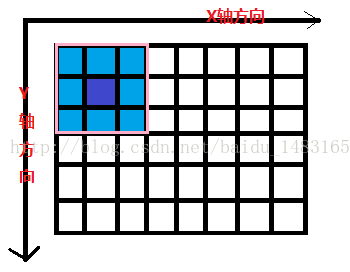
在了解了卷积操作后我们来看下卷积层的特点。
局部感知
在传统神经网络中每个神经元都要与图片上每个像素相连接,这样的话就会造成权重的数量巨大造成网络难以训练。而在含有卷积层的的神经网络中每个神经元的权重个数都时卷积核的大小,这样就相当于没有神经元只与对应图片部分的像素相连接。这样就极大的减少了权重的数量。同时我们可以设置卷积操作的步长,假设将上图卷积操作的步长设置为3时每次卷积都不会有重叠区域(在超出边界的部分补自定义的值)。局部感知的直观感受如下图:
ps:使用局部感知的原因是一般人们认为图片中距离相近的部分相关性较大,而距离比较远的部分相关性较小。在卷积操作中步长的设置就对应着距离的远近。但是步长的设置并无定值需要使用者尝试。
参数共享
在介绍参数共享前我们应该知道卷积核的权重是经过学习得到的,并且在卷积过程中卷积核的权重是不会改变的,这就是参数共享的思想。这说明我们通过一个卷积核的操作提取了原图的不同位置的同样特征。简单来说就是在一幅图片中的不同位置的相同目标,它们的特征是基本相同的。其过程如下图:

多核卷积
如权值共享的部分所说我们用一个卷积核操作只能得到一部分特征可能获取不到全部特征,这么一来我们就引入了多核卷积。用每个卷积核来学习不同的特征(每个卷积核学习到不同的权重)来提取原图特征。
上图的图片经过三个卷积核的卷积操作得到三个特征图。需要注意的是,在多核卷积的过程中每个卷积核的大小应该是相同的。
2、下采样层(Down—pooling)
下采样层也叫池化层,其具体操作与卷基层的操作基本相同,只不过下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),并且不经过反向传播的修改。
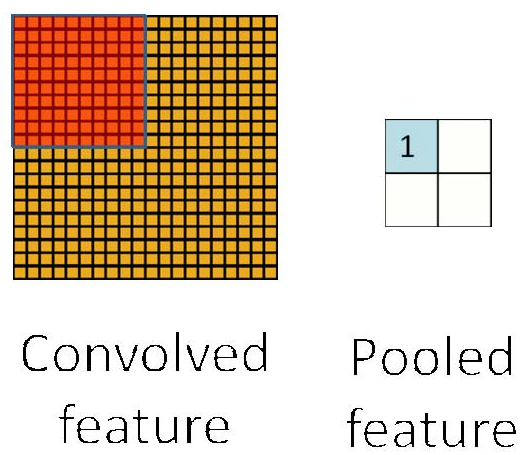
个人理解之所以要加下采样的原因是可以忽略目标的倾斜、旋转之类的相对位置的变化。以此提高精度,同时降低了特征图的维度并且已定成度上可以避免过拟合。
池化层的作用
来自链接:https://www.zhihu.com/question/36686900/answer/130890492
1. invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度)
2. 保留主要的特征同时减少参数(降维,效果类似PCA)和计算量,防止过拟合,提高模型泛化能力
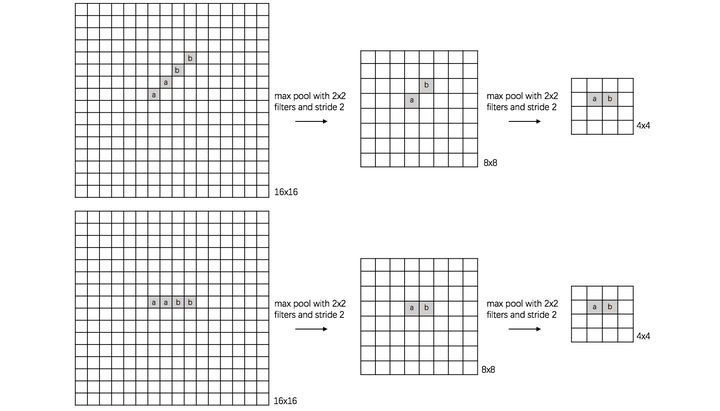
(1) translation invariance:
这里举一个直观的例子(数字识别),假设有一个16x16的图片,里面有个数字1,我们需要识别出来,这个数字1可能写的偏左一点(图1),这个数字1可能偏右一点(图2),图1到图2相当于向右平移了一个单位,但是图1和图2经过max pooling之后它们都变成了相同的8x8特征矩阵,主要的特征我们捕获到了,同时又将问题的规模从16x16降到了8x8,而且具有平移不变性的特点。图中的a(或b)表示,在原始图片中的这些a(或b)位置,最终都会映射到相同的位置。
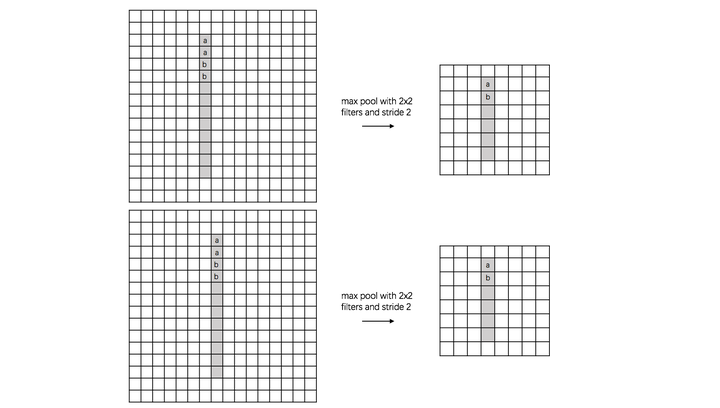
(2) rotation invariance:
下图表示汉字“一”的识别,第一张相对于x轴有倾斜角,第二张是平行于x轴,两张图片相当于做了旋转,经过多次max pooling后具有相同的特征
(3) scale invariance:
下图表示数字“0”的识别,第一张的“0”比较大,第二张的“0”进行了较小,相当于作了缩放,同样地,经过多次max pooling后具有相同的特征
