pandas介绍:
pandas的功能很强大,可以代替部分numpy的计算功能,自带数据可视化功能,对数据清洗等等功能都有很好的应用。
要使用pandas有两个最最常见的数据结构Series 和 DataFrame。绝大多数的数据都可以通过这两种数据结构来处理,而且方便简单,易于使用。
Series:
英文翻译series为一连串,一系列,在这里我们可以吧series理解为一个一维数组的对象,不同的是Series他比一维数组多了一列索引:
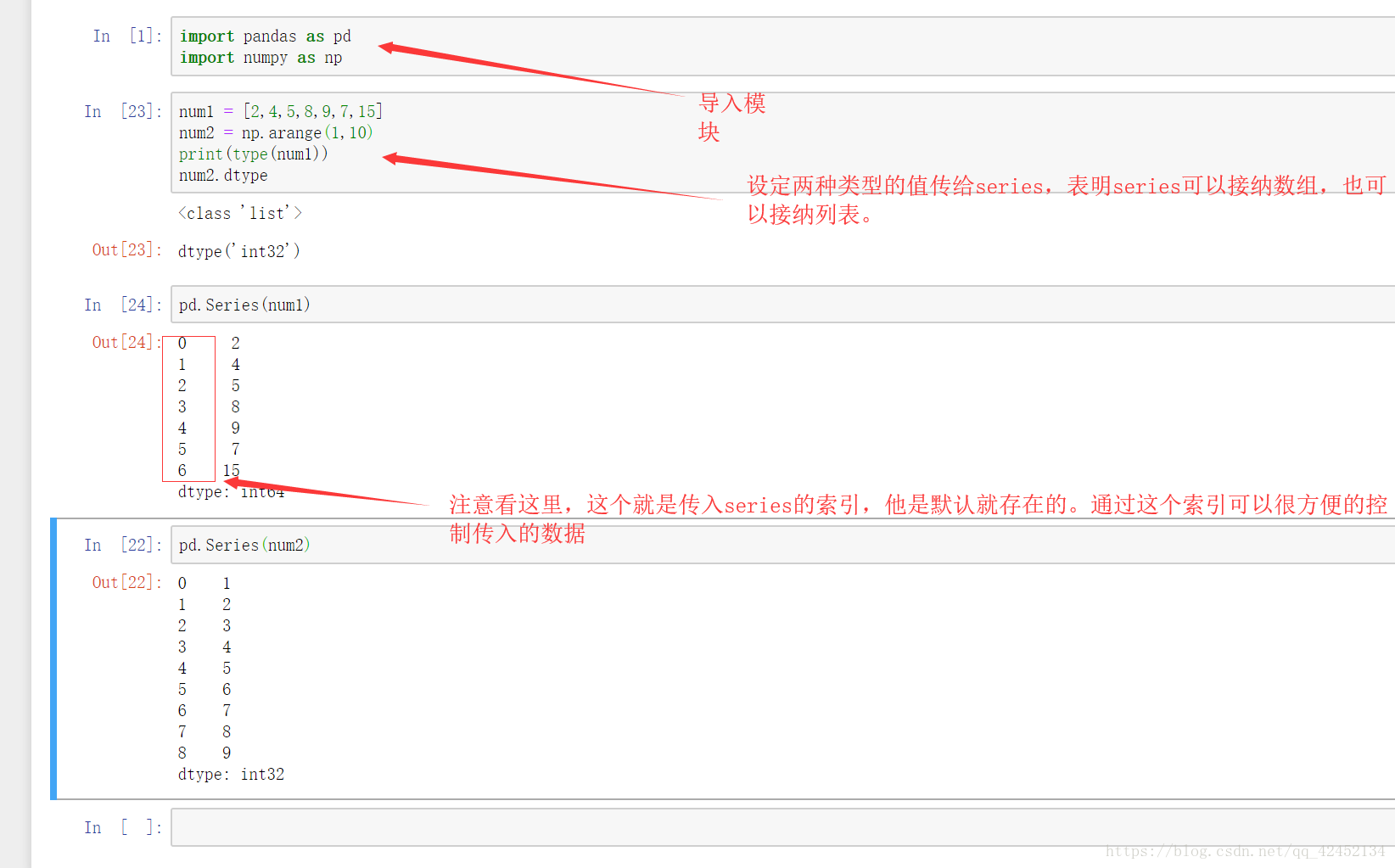
通常series的索引位于最左边,默认的是0开始的数值,如果我们不喜欢想用其他内容来当做索引可以这么干:
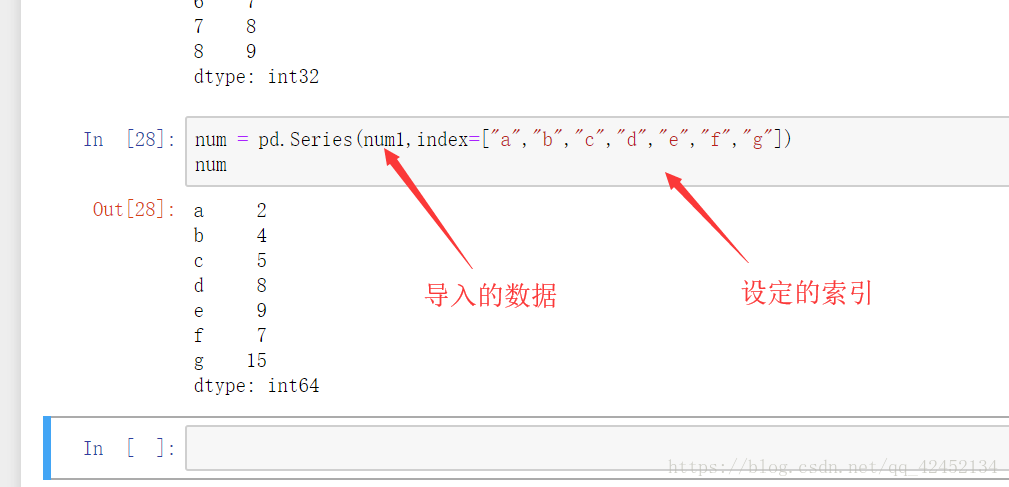
在这里要注意,我们如果设定索引的话,一定切记,索引的个数要与该数组的元素个数相等,否则报错,而且给series传参的时候 第一个位置要用数据,第二个位置才是索引。
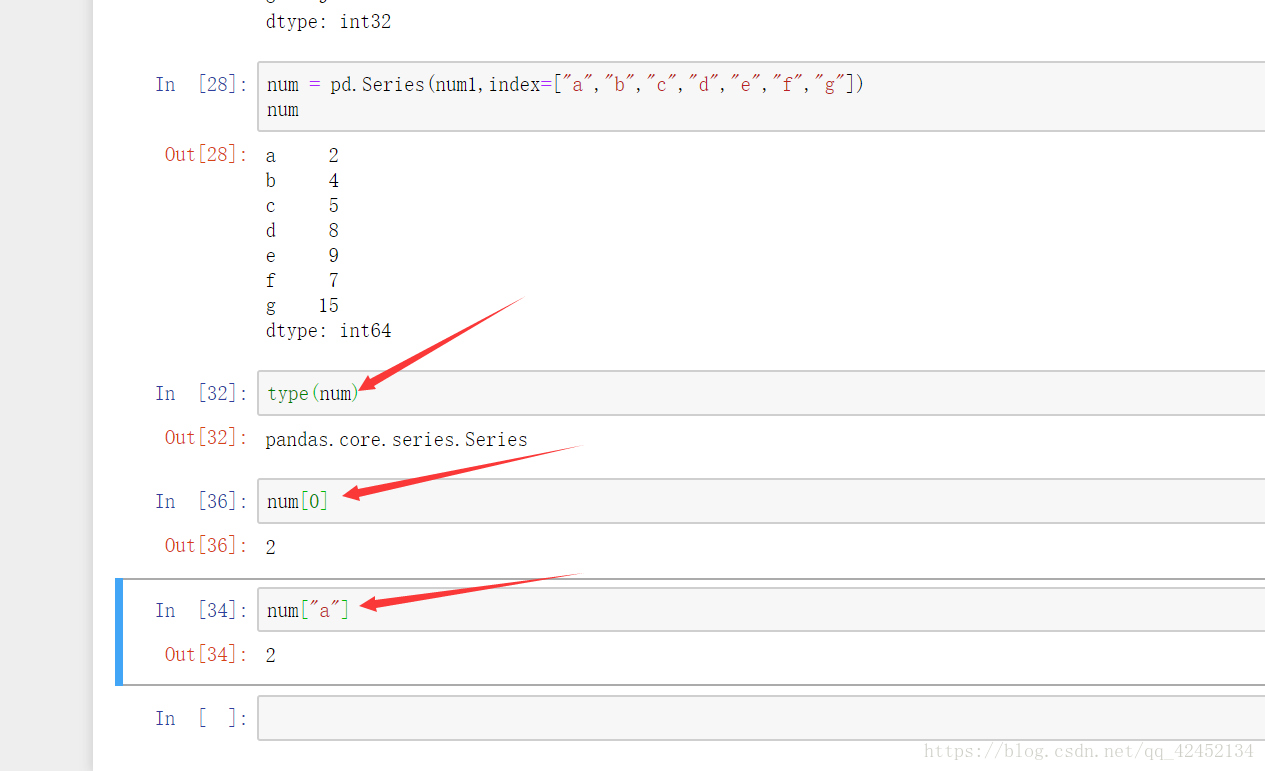
上图第一个我检查一下series的数据类型,第二个箭头,这个num索引用的是0,第三个箭头num索引用的是a,他们都表示num中的第一个元素,虽然我们已经用了index的方法给这个列表添加了索引,但是这个字符串类型的索引只是表象,实际默认的索引还是存在的,因此他们两个调用出的结果都一样。
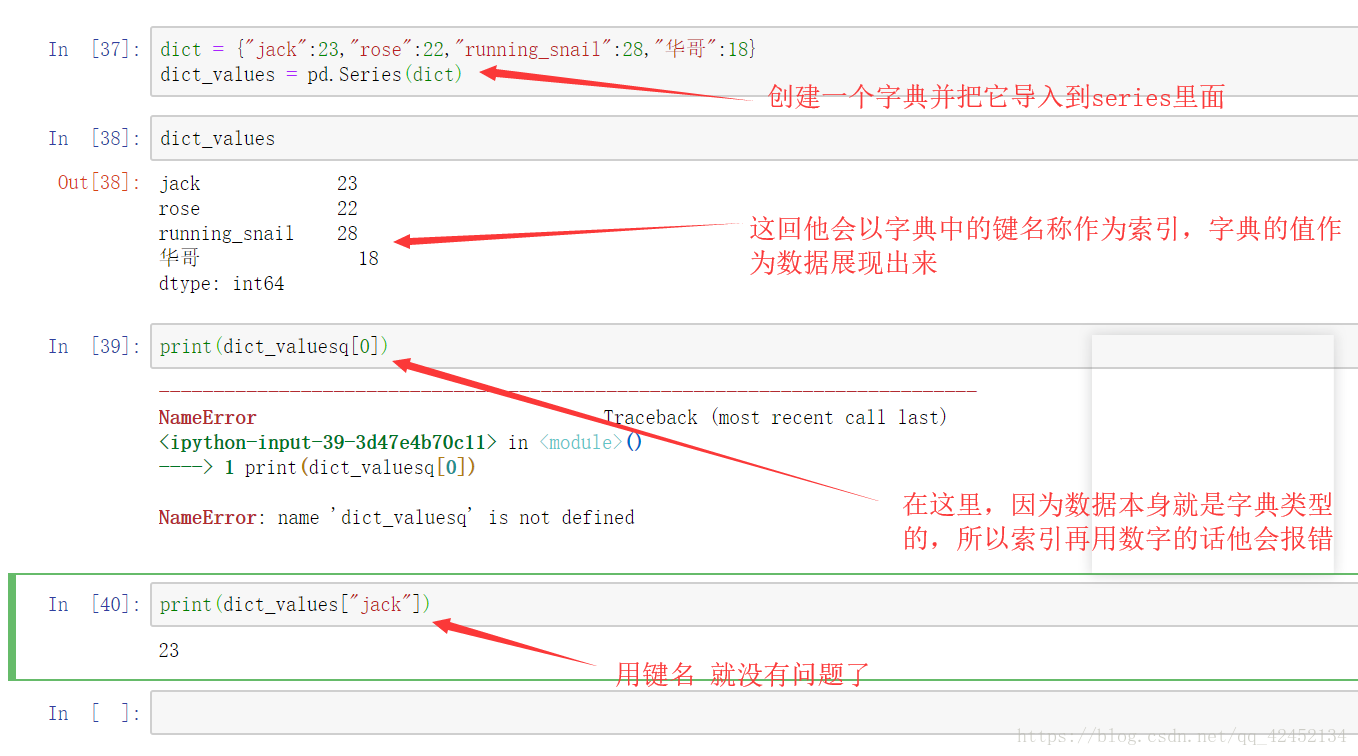
如果传入字典类型的数据series会这么处理:
DataFrame:
DataFrame是一个表格型的数据结构,咱们可以把它想象成为一个可以自行设定索引的excel单元格存储的数据,它既有行索引,也有列索引,或者咱们也可以把它看成由Series组成的字典。
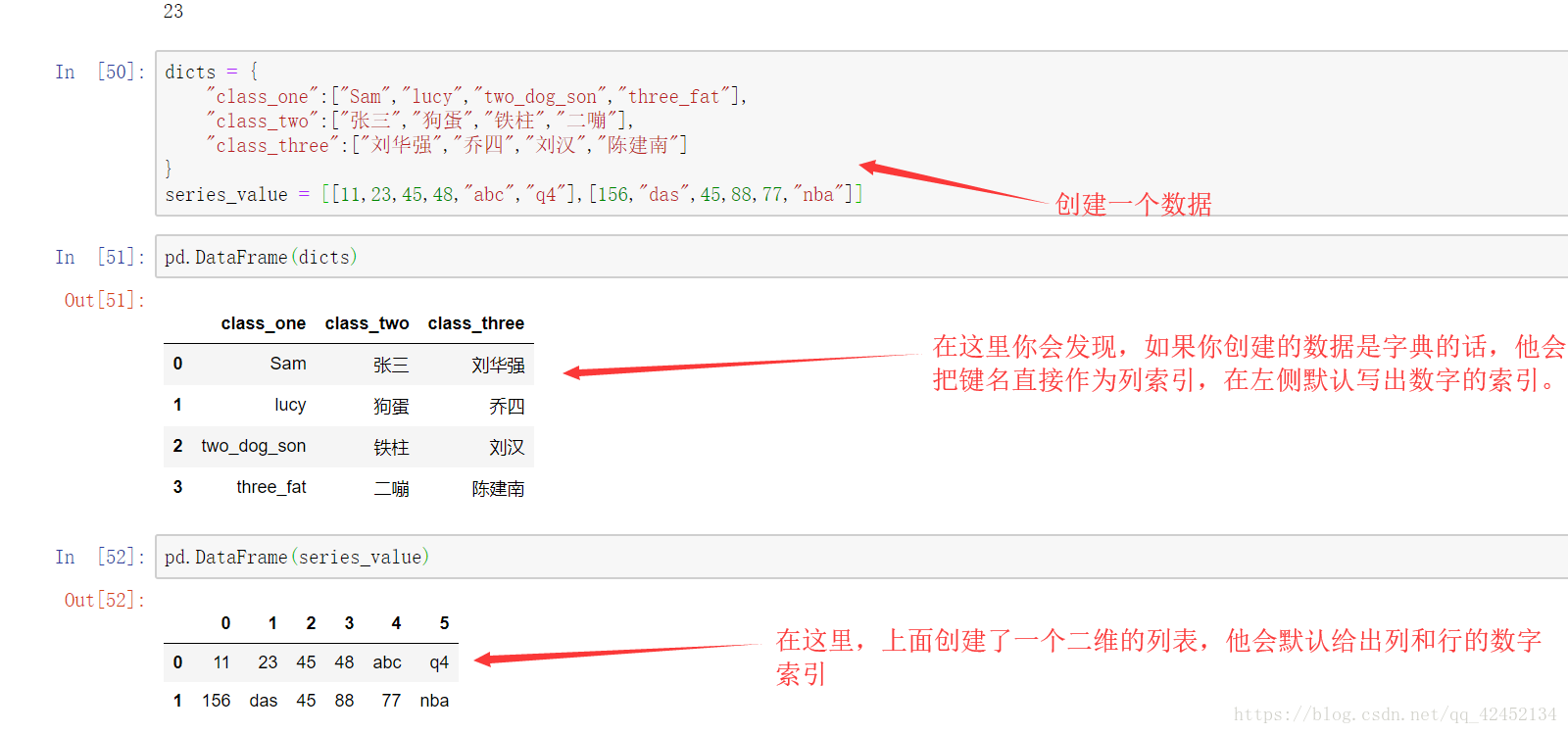
上图所示,Dataframe会自动给定索引,如果你不想要用这个索引想要自己设定一个索引就需要类似Series差不多的操作:
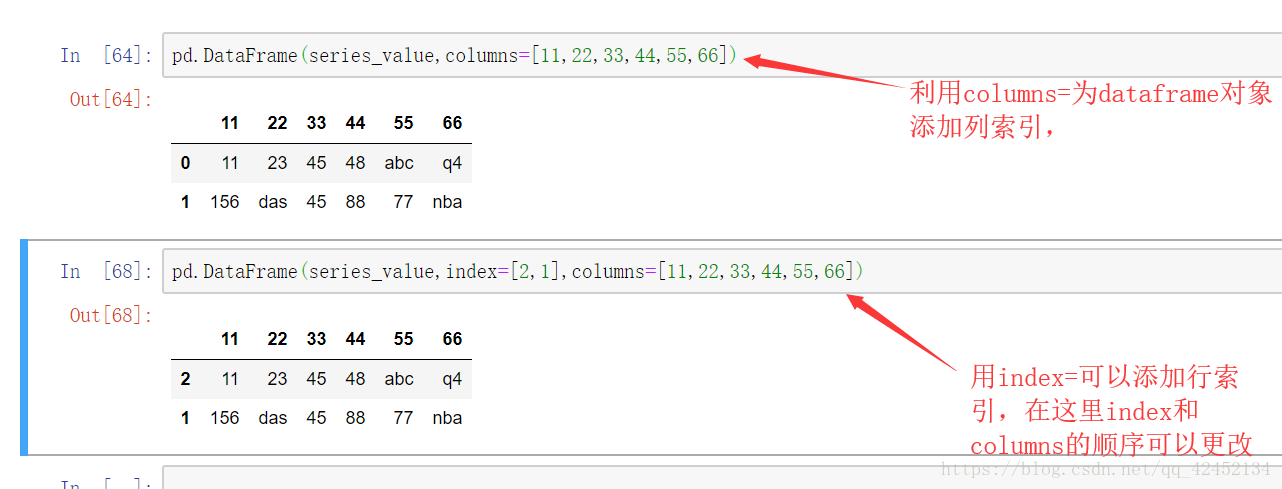
用字段和列表导入的数据除了索引有区别之外,还有个区别要注意一下:
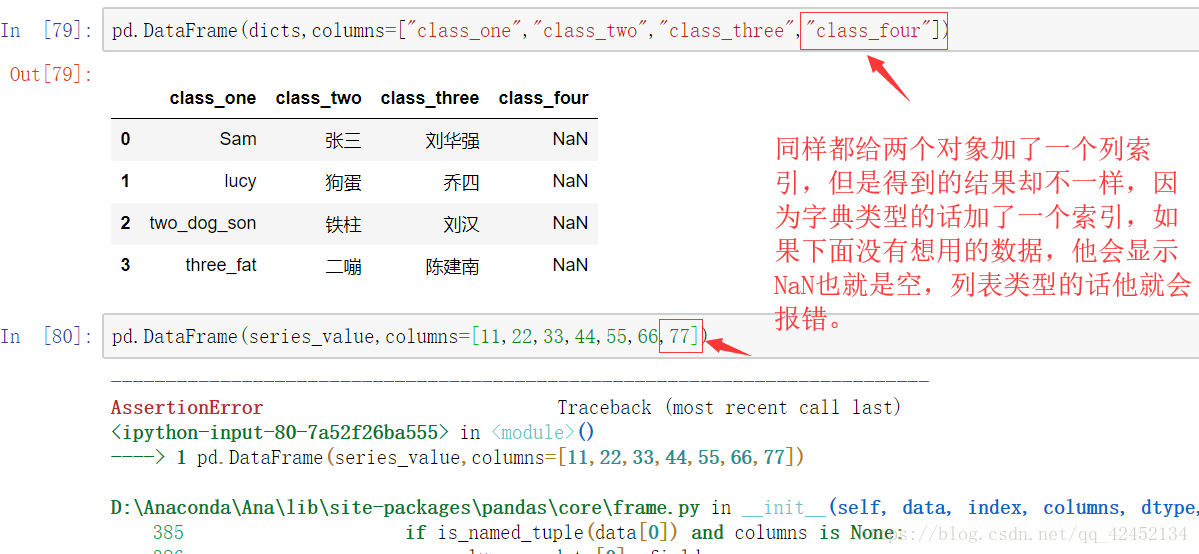
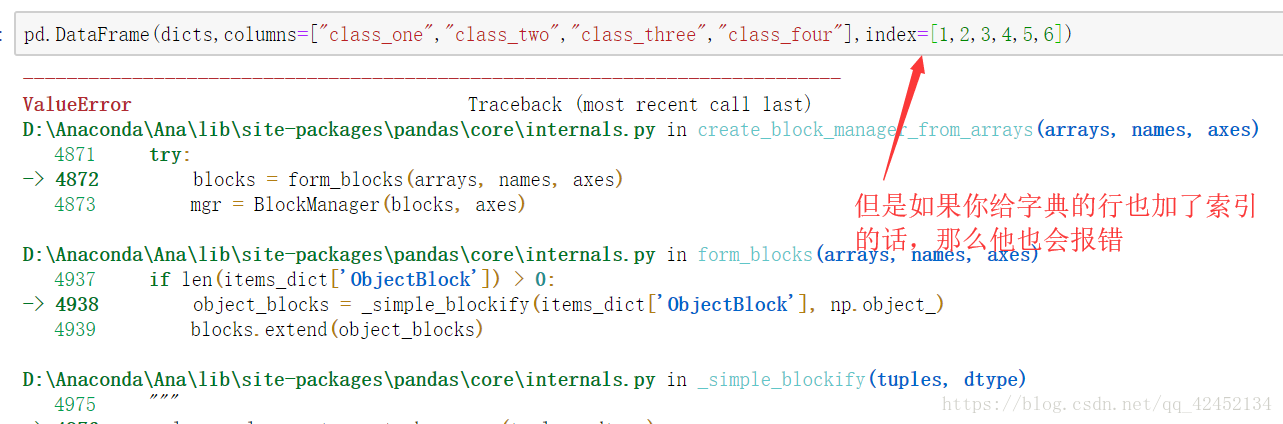
最基本的概念介绍完啦。。大咖们不喜勿喷。