一 集成方法
集成方法(ensemble method)通过组合多个基分类器(base classifier)来完成学习任务,颇有点“三个臭皮匠顶个诸葛亮”的意味。基分类器一般采用的是弱可学习(weakly learnable)分类器,通过集成方法,组合成一个强可学习(strongly learnable)分类器。所谓弱可学习,是指学习的正确率仅略优于随机猜测的多项式学习算法;强可学习指正确率较高的多项式学习算法。集成学习的泛化能力一般比单一的基分类器要好,这是因为大部分基分类器都分类错误的概率远低于单一基分类器的。
集成方法主要包括Bagging和Boosting两种方法,Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法,即将弱分类器组装成强分类器的方法。
1 Bagging
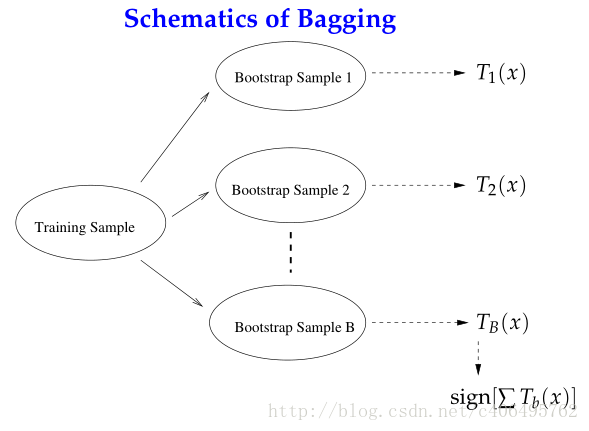
自举汇聚法(bootstrap aggregating),也称为bagging方法。Bagging对训练数据采用自举采样(boostrap sampling),即有放回地采样数据,主要思想:
- 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
2 Boosting
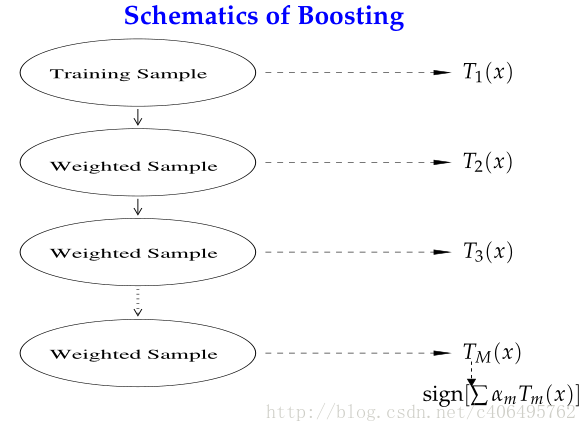
Boosting是一种与Bagging很类似的技术。Boosting的思路则是采用重赋权(re-weighting)法迭代地训练基分类器,主要思想:
- 每一轮的训练数据样本赋予一个权重,并且每一轮样本的权值分布依赖上一轮的分类结果。
- 基分类器之间采用序列式的线性加权方式进行组合。
3 Bagging、Boosting二者之间的区别
样本选择上:

- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重:
- Bagging:使用均匀取样,每个样例的权重相等。
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算:
- Bagging:各个预测函数可以并行生成。
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
4 总结
这两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果,将不同的分类算法套入到此类算法框架中一定程度上会提高了原单一分类器的分类效果,但是也增大了计算量。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
- Bagging + 决策树 = 随机森林
- AdaBoost + 决策树 = 提升树
- Gradient Boosting + 决策树 = GBDT
二.AdaBoost
AdaBoost算法是基于Boosting思想的机器学习算法,AdaBoost是adaptive boosting(自适应boosting)的缩写,其运行过程如下:
1、计算样本权重
训练数据中的每个样本,赋予其权重,即样本权重,用向量D表示,这些权重都初始化成相等值。假设有n个样本的训练集:

设定每个样本的权重都是相等的,即1/n。
2、计算错误率
利用第一个弱学习算法h1对其进行学习,学习完成后进行错误率ε的统计:

3、计算弱学习算法权重
弱学习算法也有一个权重,用向量α表示,利用错误率计算权重α:

4、更新样本权重
在第一次学习完成后,需要重新调整样本的权重,以使得在第一分类中被错分的样本的权重,在接下来的学习中可以重点对其进行学习:

其中,h_t(x_i) = y_i表示对第i个样本训练正确,不等于则表示分类错误。Z_t是一个归一化因子:

这个公式我们可以继续化简,将两个公式进行合并,化简如下:

5、AdaBoost算法
重复进行学习,这样经过t轮的学习后,就会得到t个弱学习算法、权重、弱分类器的输出以及最终的AdaBoost算法的输出,分别如下:

其中,sign(x)是符号函数。具体过程如下所示:

AdaBoost算法总结如下:

三.Bagging:
1.Bagging原理:

2.算法流程:

3.

四.随机森林:
1.原理:
随机森林以决策树为基学习器构建Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择.具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d 个属性)中选择一个最优属性;而在RF 中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分. 这里的参数k 控制了随机性的引入程度;若令k = d , 则基决策树的构建与传统决策树相同;若令k = 1 , 则是随机选择一个属性用于划分; 一般情况下,推荐值k = log2d。
2.与bagging的区别:
随机森林简单、容易实现、计算开销小,令人惊奇的是, 它在很多现实任务中展现出强大的性能,被誉为"代表集成学习技术水平的方法"可以看出,随机森林对Bagging 只做了小改动, 但是与Bagging 中基学习器的"多样性"仅通过样本扰动(通过对初始训练集采样)而来不同,随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间差异度的增加而进一步提升.
五.组合策略:
- 平均法:

2.投票法:


3.学习法:

参考资料:
-
提升分类器性能利器-AdaBoost:https://blog.csdn.net/c406495762/article/details/78212124#commentBox
-
《机器学习》周志华