一,个体与集成
集成学习通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统,基于委员会的学习。
其一般结构是先产生一组“个体学习器”,再用某种策略将它们结合起来。如下图:
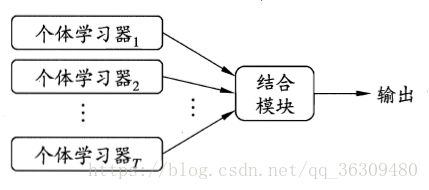
集成学习研究的核心是如何产生并结合“好而不同”的个体学习器。
根据个体学习器的生成方式,集成学习方法可分为两大类:
一是个体学习器间存在强依赖关系,必须串行生成的序列化方法:Boosting
二是个体学习器间不存在强依赖关系,可同时生成的并行化方法:Bagging,“随即森林”
二,Boosting
Boosting是一族可将弱学习器提升为强学习器的算法。工作机制是:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。
Boosting族算法最著名的代表是AdaBoost,算法如下:

其中yi∈{-1,+1},f是真实函数。
Boosting算法要求基学习器能对特定的数据分布进行学习,可通过“重赋权法”和“重采样法”实施。
重赋权法:在训练过程的每一轮中,根据样本的分布为每个训练样本重新赋予一个权重。
重采样法:在每一轮学习中,根据样本分布对训练集重新进行采样,再用重采样而得到的样本集对基学习器进行训练。
从偏差-方差分解的角度看,Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成。
三,Bagging与随机森林
3.1 Bagging
Bagging是并行式集成学习方法最著名的代表。其基于自助采样法从包含m个样本的数据集中采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。算法描述如下:

从偏差-方差分解的角度看,Bagging主要关注降低方差,因此它在不剪枝决策树,神经网络等易受样本扰动的学习器上效用更为明显。
3.2 随机森林
随机森林是Bagging的一个扩展变体。具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假设有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。一般情况下,推荐值k = log2d.
随机森林对Bagging只做了小改动,但是与Bagging中基学习器的“多样性”仅通过样本扰动而来不同,随机森林中基学习器的多样性不仅来自于样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间的差异度的增加进一步提高。
四,结合策略
常见的集合策略有:对于数值型输出,使用平均法;对于分类任务来说,使用投票法。
这里主要介绍一下另一种特殊的方法——学习法。
当训练数据很多时,一种强大的结合策略是使用“学习法”,即通过另一个学习器 来进行结合。Stacking是学习法的典型代表,这里我们把个体学习器称为初级学习器,对于结合的学习器称为次级学习器或者元学习器。
Stacking先从初始数据集训练出初级学习器,然后生成一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当作样例输入特征,而初始样本的标记仍被当作样例标记。算法如下:

在训练阶段,一般是通过使用交叉验证或者留一法这样的方式,用训练初级学习器未使用的样本来产生次级学习器的训练样本。