集成模型-Bagging和boosting
Bagging(并行)
思想:有放回的对样本随机抽样,集合策略:对分类问题使用投票法,对回归问题使用加权平均法。对弱学习器没有限制,常用决策树和神经网络
典型:RF
特点:关注降低方差,降低过拟合
有放回的好处:
1)未抽取到的样本可做验证集对模型泛化能力进行包外估计
2)基学习器是决策树时:可用包外样本辅助剪枝
3)基学习器是神经网络时:用包外样本来辅助早期停止来减小过拟合
Boosting(串行)
思想:将弱学习算法提升为强学习算法的过程;通过反复学习得到一系列弱学习器,组合这些弱学习器成为强学习器。
典型: adboost,Xgboost,GBDT,lightgbm
特点:关注降低偏差
为什么boosting是降低偏差?拟合残差
形式:加法模型+前向分步算法+损失函数
1)加法模型:弱分类器线性相加组成强分类器。
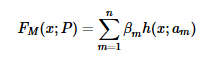
h(x;am) 就是一个个的弱分类器,am是弱分类器学习到的最优参数,βm就是弱学习在强分类器中所占比重,P是所有am和βm的组合。
2)前向分步算法:在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的
![]()
3)损失函数:采用不同损失函数构成boosing不同类型
Bagging和boosting区别
样本选择;样例权重;预测函数;并行计算
1)样本选择:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
总结
这两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果,将不同的分类算法套入到此类算法框架中一定程度上会提高了原单一分类器的分类效果,但是也增大了计算量
袋外数据OOB
基本思想:bagging方法中Bootstrap每次约有1/3的样本不会出现在Bootstrap所采集的样本集合中,也就没有参加决策树的建立,把这1/3的数据称为袋外数oob(out of bag),它可以用于取代测试集误差估计方法。
袋外数据oob误差计算方法:
对于已经生成的随机森林,用袋外数据测试其性能,假设袋外数据总数为O,用这O个袋外数据作为输入,带进之前已经生成的随机森林分类器,分类器会给出O个数据相应的分类,因为这O条数据的类型是已知的,则用正确的分类与随机森林分类器的结果进行比较,统计随机森林分类器分类错误的数目X,则袋外数据误差大小=X/O;这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计