本文主要是对高性能MySQL书籍中的内容进行一个简短的总结以及个人理解,记录一下学习的过程。
前言:
与数据库交互的软件系统中,系统的架构实现以及数据交互的SQL语句对系统的性能至关重要,系统的数据模型设计实现对系统性能的影响通俗一点说就是数据库Schema设计对系统的影响。数据库Schema的设计并不是一件简单的事情,并不是说做到第三、四范式就算可以了。(个人注:通常大型系统的数据库Schema设计会通过数据冗余来提高性能)。不同的数据库Schema对系统的性能影响各不相同,下面通过一个例子进行说明:
需求概述:一个简单的讨论系统,需要有用户、用户组、组讨论区这三部分基本功能。
简单分析:
- 需要存放用户数据
- 存放分组信息以及用户与分组的关系信息
- 需要存放讨论信息的表
解决方案1:
比较直观的设计,使用四张表进行存储,用户表、分组表、用户分组关系表以及讨论组帖子表,各个表如下:
- 用户表 user

2. 分组表 groups

3.用户分组关系表 user_group

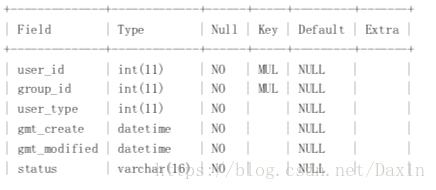
4. 讨论帖子表 group_message
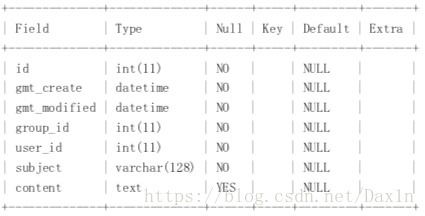
优化方案2:
1. 用户表 user

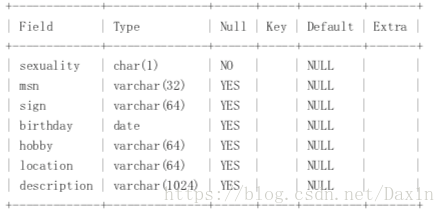
2.用户画像表 user_profile
3.分组表与用户分组关系表不变
4.讨论组帖子表(注意:此表添加了一个author字段)

5:分组消息内容表

方案评估:
凭借经验,任何好的设计都是迭代出来的,所谓迭代其实就是在项目的过程中逐渐发现问题,解决问题。马克思说过:实践是检验真理的唯一标准,数据库schema设计也不例外,接下来就检验一下两种方案的优劣:
1、场景一
用户登陆讨论区,选择一个分组需要将该分组的所有帖子进行分页显示,暂时假定一页显示20个条目,此时分别对应的SQL如下:
方案1查询语句:
SELECT u.id, u.nick_name, t.id, t.subject
FROM USER u, (
SELECT user_id, subject, id
FROM GROUP_MESSAGE
WHERE group_id = '1001'
ORDER BY gmt_modified
LIMIT 20
) t
WHERE t.user_id = u.id;方案2查询语句:
SELECT user_id, subject, id, author
FROM GROUP_MESSAGE
WHERE group_id = '1001'
ORDER BY gmt_modified
LIMIT 20结论:很直观就可以发现,该场景下方案2更优秀,数据库的join操作往往是导致数据性能差的主要原因,方案2不需要join,一张单独的表就可以直接查询出来。该设计就是违背数据库的范式,但是通过数据冗余的方式可以提升性能,通过本场景可以知道,让我们需要避免由于join查询带来的性能瓶颈时候可以使用冗余数据解决,企业中很常见。但是细心读者会发现这种设计带来了昵称更新需要更新两张表,对于这个问题一般来说通过程序逻辑控制更新即可,总和来说还是利大于弊,但是实际上很多论坛都是一旦更选择了用户名字便不再支持修改名字,这样就避免了数据不一致的问题。
2、场景2
用户可能时常查询用户的信息数据,但是次数相对比较,一般都是用户在修改个人资料或者点击其他用户头像时候时候才会查看一个用户的完整信息,通常情况下只是会显示用户的部分信息,我们可以这些必须要显示的部分用户信息与部分其他不经常被访问的用户信息分为两张表存储,例如方案2设计中的用户表与用户画像表。这么做对查询带来的好处是:可以减少查询的检索数据量,提高检索性能。但是你可能会觉着当要查询用户的完整信息时候需要进行用户表与画像表的关联,性能会变差?!性能确实会降低,但是由于用户表与画像表都是1对1关联,关联字段的过滤性非常高,在根据场景也知道,查询用户完整信息发生的频次也不高,因此此处来带的损失与场景1中的获益对比而言,非常微不足道。
感悟:
好的代码一定是重构出来的,好的设计一定是迭代验证出来的。实践是检验真理的唯一标准。