类加载机制
想要了解类加载的机制,首先就要了解类的生命周期,下面的图示就是类加载的一个具体过程:

类加载器
类加载器主要负责装入类,搜索网络、jar、zip、文件夹、二进制数据、内存等指定位置的类资源。一个java程序运行,最少有三个类加载器实例,负责不同类的加载。
Bootstrap loader
Bootstrap loader即核心类库加载器是用C/C++实现的,并非某个java类。加载JRE_HOME/jre/lib目录,或用户配置的目录,相当于java一些核心类(如rt.jar…String…Object等)都是由该加载器所加载的
Extension Class Loader
拓展类库加载器。它的java实体类是ExtClassLoader,用于加载JRE_HOME/jre/lib/ext目录,JDK拓展包,或用户配置的目录
application class loader
用户应用程序加载器,其实例对应的是AppClassLoader的实例。
它主要加载java.class.path指定的目录,用户应用程序class-path或者java命令运行时的参数-cp…
查看类对应的加载器
我们可以通过一个JDK-API进行查看:java.lang.Class.getClassLoader()
该API的功能就是返回装载类的类加载器
如果这个类是由bootstrapClassLoader加载的,那么这个方法在这种实现中将会返回null。
我们可以来看一段代码实例来演示该API的作用。
public class ClassLoaderView {
public static void main(String[] args) throws ClassNotFoundException {
//加载核心类库的 BootStrap ClassLoader
System.out.println("核心类库加载器:"+ClassLoaderView.class.getClassLoader()
.loadClass("java.lang.String").getClassLoader());
//加载拓展库的 Extension ClassLoader
System.out.println("拓展类库加载器:"+ClassLoaderView.class.getClassLoader()
.loadClass("com.sun.nio.zipfs.ZipCoder").getClassLoader());
//加载应用程序的Application ClassLoader
System.out.println("应用程序加载器:"+ClassLoaderView.class.getClassLoader());
//双亲委派模型 Parents Delegation Model
System.out.println("应用程序库加载器的父类:"+ClassLoaderView.class.getClassLoader().getParent());
System.out.println("应用程序加载器的父类的父类:"+ClassLoaderView.class.getClassLoader().getParent().getParent());
}
}
再来看看输出的结果:
核心类库加载器:null
拓展类库加载器:sun.misc.Launcher$ExtClassLoader@6d6f6e28
应用程序加载器:sun.misc.Launcher$AppClassLoader@18b4aac2
应用程序库加载器的父类:sun.misc.Launcher$ExtClassLoader@6d6f6e28
应用程序加载器的父类的父类:null
所以可以明白我们上面的结论是正确的。
JVM如何知道我们的类在何方
class信息存放在不同的位置,桌面jar、项目bin目录、target目录等等。
查看openjdk中AppClassLoader源码发现了这么一段代码:

这段代码可以明白java是读取java.class.path配置,指定了去哪些地址加载类资源,
我们可以通过jps、jcmd两个命令来验证。
先来看一段代码:
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
System.out.println("Hello World");
System.in.read();
}
}
这段代码在执行之后进入了阻塞状态,因为需要我们输入再能进行读操作。这时我们打开命令行工具使用jps和jcmd来看一下运行中的java进程,输出的结果如下:
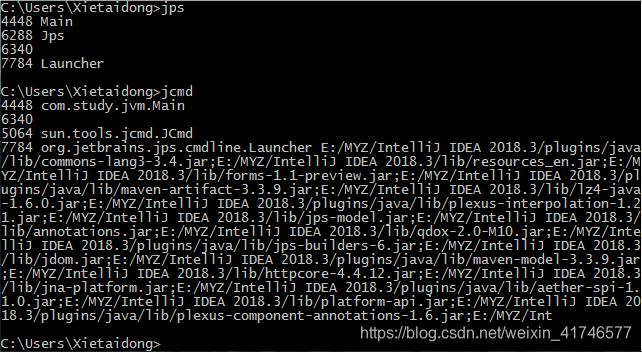
其中
- jps查看本机的JAVA进程
- jcmd可以查看运行时配置:jcmd 进程号 VM.system_properties
类不会重复加载
类的唯一性:同一个类加载器,类名一样,代表是同一个类。
识别方式:ClassLoader Instance id + PackageName + ClassName
验证方式:使用类加载器,对同一个class类的不同版本,进行多次加载,检查是否会加载到最新代码。
注意:静态代码块只会在newStance的时候执行一次,后面将不会再加载。
双亲委派模型
为了避免重复加载,由下到上逐级委托,由上到下逐级查找。
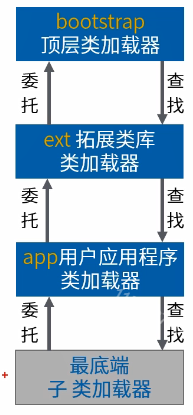
说白了就是底层的加载器类首先想到的不是去尝试加载类,而是把这个请求委派给他的父加载器,且每一个层次的加载器都是如此,因此所有的类加载器都会加载请求给上层的启动类加载器,只有当父加载器反馈自己无法加载该加载请求的时候(该加载器的搜索范围中没有找到对应的类)时,子加载器才会去尝试自己加载要加载的类。
注意:类加载器之间不存在父类子类的关系,“双亲”只是对英文的翻译,本质上应该是逻辑上的上下级关系。
垃圾回收机制
自动垃圾收集
自动垃圾收集是查看堆内存,识别正在使用那些对象以及那些对象未被删除以及删除未使用对象的过程。
使用中的对象或引用的对象意味着程序的某些部分仍然维护指向该对象的指针。
程序的任何部分都不再引用未使用的对象或未引用的对象,因此可以回收未引用对象使用的内存。
在C和C++中,分配和释放内存是一个手动的过程。而Java中,解除分配内存的过程由垃圾收集器自动处理。
如何确定内存需要被回收
该过程的第一步被称为标记。这是垃圾收集器识别哪些内存正在使用而哪些不在使用的地方,如下图:
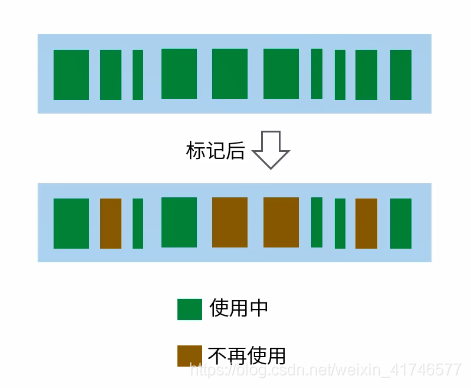
不同类型内存的判断方式
对象回收-引用计数
就是一个对象中加一个计数器,用到了就加1,不用就减1,但是java中是不用的。因为容易出现循环引用的问题。所谓的循环引用就如引用obja = objb,这样他们相互引用,其实都是null,就白白占用内存了。
对象回收-可达性分析
简而言之就是将对象和它的引用关系看成一个图,选定活动的对象作为GC Roots;
然后跟踪引用链条,如果一个对象和GC Roots之间不可达,也就是不存在引用,那么就被认为是可回收的对象。
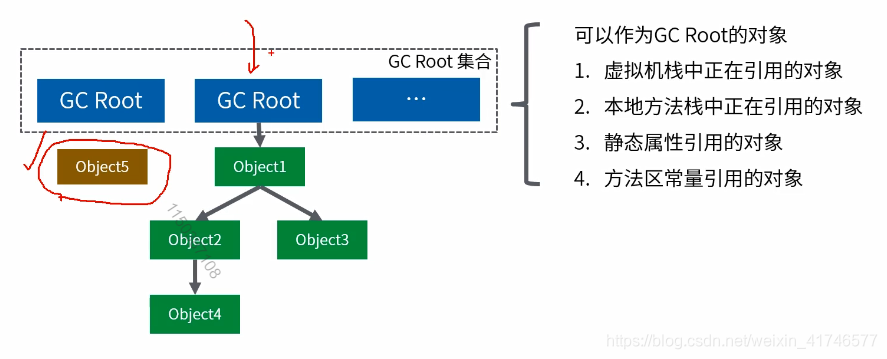
图中的1,2,3,4对象都有指向GC Root的引用,只有5没有,所以5是可回收对象。
引用类型和可达性级别
引用类型
- 强引用(StrongReference):最常见的普通对象引用,只要还有强引用指向一个对象,就不会回收。比如说指向那些 new 出来对象的引用就是强引用。
- 软引用(SoftReference):JVM认为内存不足时,才会去试图回收软引用指向的对象。(缓存场景)
- 弱引用(WeakReference):虽然是引用,但随时可能被回收掉。
- 虚引用(PhantomReference):不能通过它访问对象。只能在对象被finalize(析构)之后,执行指定逻辑的机制(cleaner)
可达性级别

垃圾收集算法
标记-清除(Markp-Sweep)算法
标记-清除(Markp-Sweep)算法:首先标识出所有要回收的对象,然后进行清除。标记、清除过程效率有限,有内存碎片化的问题,不适合特别大的堆;收集算法基本基于标记-清除的思路进行改进。
复制(Copying)算法
复制(Copying)算法:划分两块同等大小的区域,收集时将活着的对象复制到另一块区域。拷贝过程中将对象顺序放置,就可以避免内存碎片化。复制+预留内存,有一定的浪费。
标记-整理(Mark-Compact)
标记-整理(Mark-Compact):类似于标记-清除,但为避免内存碎片化,它会在清理过程中将对象移动,以确保移动后的对象占用连续的内存空间。
分代收集
上面订单垃圾回收算法我们可以看到不同的算法都有利弊,但是核心就是想在避免内存浪费,因此分代收集这时候就显得很有必要了。所谓的分代收集就是根据对象的存活周期,将内存划分为几个区域,不同区域采用合适的垃圾收集算法。比如说新对象就会分配到Eden,如果超过-XX:+PretenureSizeThreshold:设置大对象直接进入老年代的阈值。

就如上图所示,但是显然不够具象,再看更详细的一幅图:
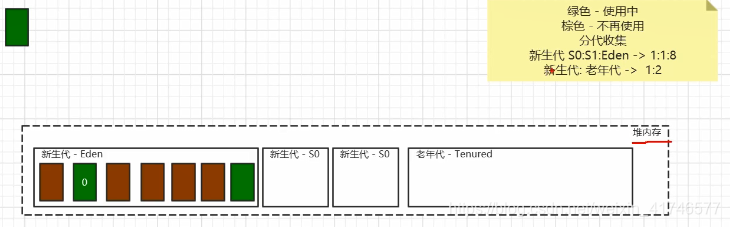
主流的JVM都使用分代收集的方式,将整个堆内存分为新生代和老年代,而新生代还分为了Eden、S0(from)、S1(to).
新生代
新生代采用的算法策略是复制算法,新创建的对象基本上都是放在Eden区的,而复制算法就是在Eden快要满了的时候就把存活的对象复制到S0中,然后开始GC,所以说GC开始的时候只有Eden和S0是有对象的,而S1是没有对象的,GC结束之后,Eden区中的对象都会被移到S1,然后对对象进行一次标记(经历过的GC次数+1),而S0中的对象则视它的标记值而定,如果超过了设定的阈值则被移到老年代,如果次数没到则移到S1,然后对对象进行一次标记(经历过的GC次数+1)。
注意:上面说新创建的对象基本上都是放在Eden区的,但是如果对象过大,导致Eden区无法容下,就会直接进入老年代
老年代
老年代采用的算法策略是标记-整理,通过标记判断是否使用中,将不再使用的数据移除,然后对存活的对象做一次整理,让内存连续,避免碎片化。
垃圾收集器
串行收集器 -Serial GC -XX:+UseSerialGC
单个线程来执行所有垃圾收集工作,适合单处理器机器。Client模式下JVM的默认选项。
串行收集器 -Serial Old -XX:+UseSerialOldGC
可以在老年代使用,它采用了标记-整理(Mark-Compact)算法,区别于新生代的复制算法。
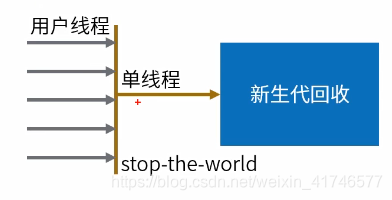
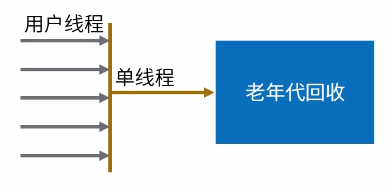
GC串行收集器有个很重要的特性,就是stop-the-world,就是当GC线程回收垃圾的时候,是终止所有其他用户线程的。也就是说他清理的时候,别的代码不能执行了,这样肯定很影响性能。
因此并行收集器也被提了出来。
并行收集器

