1. 选择优化的数据类型
1.1 原则
- 更小的通常更好
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。例如只需要存0-200,tinyint unsigned更好。更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。
- 简单更好
简单数据类型的操作通常需要更少的CPU周期。整型比字符操作代价更低,因为字符集和校对规则(排序规则)使字符比较比整型比较更复杂。例如,应该使用MySQL内建的类型date、time或datetime来存储日期和时间,而不是字符串;应该使用整型存储IP地址。
- 尽量避免NULL
通常情况下最好指定列为NOT NULL。如果查询中包含可为NULL的列,对MySQL来说更难优化,因为可为NULL的列使得索引、索引统计和值比较都更复杂。可为NULL的列会使用更多的存储空间,在MySQL里也需要特殊处理。当可为NULL的列被索引时,每个索引记录需要一个额外的字节,在MyISAM里甚至还可能导致固定大小的索引变成可变大小的索引。
如果计划在列上建索引,就应该尽量避免设计成可为NULL的列。
DATETIME和TIMESTAMP列都可以存储相同类型的数据:时间和日期,精确到秒。然而TIMESTAMP只使用DATETIME一半的存储空间,并且会根据时区变化,具有特殊的自动更新能力。但是TIMESTAMP允许的时间范围要小得多。
1.2 整数类型
可使用的整数类型:TINYINT(8)、SMALLINT(16)、MEDIUMINT(24)、INT(32)、BIGINT(64),存储的值的范围从-2^(N-1)到2^(N-1)-1。
UNSIGNED属性表示不允许负值,大致可以使正数的上限提高一倍。例如TINYINT的存储范围是-128~127,TINYINT UNSIGNED的存储范围是0~255。
MySQL可以为整数类型指定宽度,例如INT(11),它只是规定了MySQL的一些交互工具用来显示字符的个数,对于存储和计算来说INT(1)和INT(20)没有区别。
1.3 实数类型
FLOAD和DOUBLE类型支持使用标准的浮点计算进行近似计算。
DECIMAL类型用于存储精确的小数。
浮点和DECIMAL类型都可以指定精度。对于DECIMAL列,可以指定小数点前后所允许的最大位数,这会影响列的空间消耗。
浮点类型在存储同样范围的值时,通常比DECIMAL使用更少的空间。FLOAT使用4个字节存储,DOUBLE使用8个字节存储。
尽量只在对小数进行精确计算时才使用DECIMAL,例如存储财务数据。在数据量比较大的时候,可以使用BIGINT代替DECIMAL,将需要存储的货币单位根据小数的位数乘以响应的倍数即可。这样可以同时避免浮点存储计算不精确和DECIMAL精确计算代价高的问题。
1.4 字符串类型
- VARCHAR
VARCHAR类型用于存储可变长字符串,是最常见的字符串数据类型。它比定长类型更节省空间,因为它仅使用必要的空间。VARCHAR需要使用1或2个额外字节记录字符串的长度:如果列的最大长度小于或等于255字节,则只使用1个字节表示,否则使用2个字节。
使用VARCHAR的情况:字符串的最大长度比平均长度大很多;列的更新很少,所以碎片不是问题;使用了像UTF-8这样复杂的字符集,每个字符都使用不同的字节数进行存储。
5.0版本以上,MySQL在存储和检索时会保留末尾空格。
- CHAR
CHAR类型是定长的,CHAR值会根据需要采用空格进行填充以方便比较。
使用CHAR的情况:存储很短的字符串或者所有值都接近同一个长度。CHAR非常适合存储密码的MD5值。
MySQL会删除所有的末尾空格。
- BINARY和VARBINARY
它们存储的是二进制字符串,二进制字符串存储的是字节码而不是字符,填充是\0而不是空格。
- BLOB和TEXT
BLOB和TEXT都是为存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。
字符类型:TINYTEXT、SMALLTEXT(TEXT)、MEDIUMTEXT、LONGTEXT
二进制类型:TINYBLOB、SMALLBLOB(BLOB)、MEDIUMBLOB、LONGBLOB
- 枚举
有时候可以使用枚举列代替常用的字符串类型。
CREATE TABLE enum_test (
e enum('fish', 'apple', 'dog') NOT NULL
);
INSERT INTO enum_test(e) VALUES('fish'), ('dog'), ('apple');这三行数据实际存储为整数,而不是字符串。
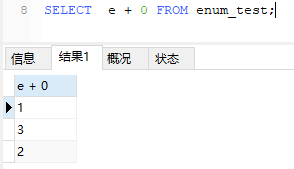
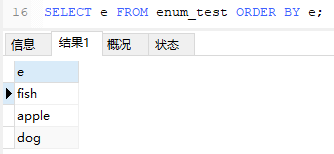
并且枚举字段是按照内部存储的整数而不是定义的字符串进行排序的。
枚举最不好的地方是,字符串列表是固定的,添加或删除字符串必须使用ALTER TABLE。因此,对于一系列未来可能会改变的字符串,使用枚举不是一个好主意,除非能接收只在列表末尾添加元素。
在“查找表”时采用整数主键而避免采用基于字符串的值进行关联。
将某些列由VARCHAR转换为ENUM可以让表的大小大大减小,但是用VARCHAR关联ENUM或者ENUM关联VARCHAR会慢一些。
1.5 日期和时间类型
- DATETIME
这个类型能保存大范围的值,从1001年到9999年,精度为秒。它把日期和时间封装到格式为YYYYMMDDHHMMSS的整数中,与时区无关。使用8个字符的存储空间。
- TIMESTAMP
这个类型保存了从1970年1月1日午夜(格林尼治标准时间)以来的秒数,它和UNIX时间戳相同。使用4个字节的存储空间。只能表示从1970年到2038年。TIMESTAMP显示的值依赖于时区。如果插入时没有指定第一个TIMESTAMP列的值,MySQL则设置这个列的值为当前时间。在插入一行记录时,MySQL默认也会更新第一个TIMESTAMP的值。
通常应该尽量使用TIMESTAMP,因为它比DATETIME空间效率更高。
1.6 位数据类型
- BIT
可以使用BIT列在一列中存储一个或多个true/false值。BIT(1)定义一个包含单个位的字段,BIT(2)存储2个位,最大长度是64分位。
MySQL把BIT当作字符串类型,而不是数字类型。对于大部分应用,最好避免使用这种类型。
- SET
如果需要保存很多true/false值,可以考虑合并这些列到一个SET数据类型,它在MySQL内部是以一系列打包的位的集合来表示的。一般来说,也无法在SET列上通过索引查找。
1.7 选择标识符
为标识列选择数据类型时,应该选择跟关联表中的对应列一样的类型。
整数类型通常是标识列最好的选择,因为它们很快并且可以使用AUTO_INCREMENT。
如果存储UUID值,则应该移除“-”符号;或者用UNHEX()函数转换UUID值为16字节的数字,并且存储在一个BINARY(16)列中。检索时可以通过HEX()函数来格式化为16进制格式。
1.8 特殊类型数据
人们经常使用VARCHAR(15)列来存储IP地址,然后,它们实际上是32位无符号整数,不是字符串,用小数点将地址分为四段的表示方法只是为了让人们阅读容易。所以应该用无符号整数存储IP地址,MySQL提供INET_ATON()和INET_NTOA()函数在这两种表示方法之间转换。
CREATE TABLE ip_test (
ip INT UNSIGNED NOT NULL
);
INSERT INTO ip_test(ip) VALUES(inet_aton('192.168.0.1'));
SELECT INET_NTOA(ip) AS ip FROM ip_test;2. MySQL schema设计中的陷阱
- 太多的列
MySQL的存储引擎API工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列。从行缓冲中将编码过的列转换成行数据结构的操作代价是非常高的。
- 太多的关联
如果希望查询执行得快速且并发性好,单个查询最好在12个表以内做关联。
- 全能的枚举
注意防止过度使用枚举,例如:
CREATE TABLE contry (
contry enum ('中国', '日本', ...)
);这里应该用整数作为外键关联到字典表或者查找表来查找具体值。
- 变相的枚举
枚举列允许在列中存储一组定义值中的单个值,集合列允许在列中存储一组定义值中的一个或多个值。
CREATE TABLE test (
is_default set('Y', 'N') NOT NULL DEFAULT 'N'
);如果这里'Y'和‘N’两种情况不会同时出现,那么应该使用枚举列代替集合列。
- 非此发明的NULL
应该避免使用NULL,如果需要存储一个事实上的“空值”到表中,也许可以使用0、某个特殊值或者空字符串作为代替。但是也不一定。
3. 范式和反范式
在范式化的数据库中,每个事实数据会出现并且只出现一次,相反,在反范式化的数据库中,信息是冗余的,可能会存储在多个地方。
- 第一范式(1NF)
原子性,即数据库表里的字段都是不可分割的。
| 学号 | 姓名 | 年级专业 | 辅导员 |
| 20190101 | 小明 | 19级计科 | 王老师 |
上述表中“年纪专业”字段可再分:
| 学号 | 姓名 | 年级 | 专业 | 辅导员 |
| 20190101 | 小明 | 19 | 计科 | 王老师 |
- 第二范式(2NF)
在满足第一范式的情况下,表中必须有主键,并且其他非主属性必须完全依赖主键。
| 学号 | 姓名 | 年级 | 专业 | 辅导员 | 课程编号 | 课程名称 | 成绩 |
| 20190101 | 小明 | 19 | 计科 | 王老师 | 1001 | 程序设计C | 90 |
上述表中“学号”和“课程编号”作为联合主键才能唯一确定一条数据,“姓名”、“年龄”依赖“学号”,“课程名称”依赖“课程编号”,都是对联合主键的部分依赖,只有成绩完全依赖联合主键,应改为:
| 学号 | 姓名 | 年级 | 专业 | 辅导员 |
| 20190101 | 小明 | 19 | 计科 | 王老师 |
| 课程编号 | 课程名称 |
| 1001 | 程序设计C |
| 学号 | 课程编号 | 成绩 |
| 20190101 | 1001 | 90 |
- 第三范式(3NF)
在满足第一、二范式的情况下,非表中主键字段完全直接依赖主键,不能是传递依赖。
| 学号 | 姓名 | 年级 | 专业 | 辅导员 |
| 20190101 | 小明 | 19 | 计科 | 王老师 |
上述表中“专业”依赖主键“学号”,“辅导员”依赖“专业”,属于传递依赖,应该为:
| 学号 | 姓名 | 年级 | 专业 |
| 20190101 | 小明 | 19 | 计科 |
| 专业 | 辅导员 |
| 计科 | 王老师 |
3.1 范式的优点和缺点
优点
- 范式化的更新操作通常比反范式化要快;
- 当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要修改更少的数据;
- 范式化的表通常更小,可以更好地放在内存里,所以执行操作会更快;
- 很少有多余的数据意味着检索列表数据时更少需要DISTINCT或者GROUP BY语句。
缺点
范式化设计的schema的缺点是通常需要关联。
3.2 反范式的优点和缺点
反范式化的schema因为所有数据都在一张表中,可以很好地避免关联。
3.3 混用范式化和反范式化
在实际应用中经常需要混用,可能使用部分范式化的schema、缓存表等。
最常见的反范式化数据的方法是复制或者缓存,在不同的表中存储相同的特定列。
4. 缓存表和汇总表
“缓存表”表示存储那些可以比较简单地从schema其他表获取(但是每次获取的速度比较慢)数据的表,例如,逻辑上荣冗余的数据。
“汇总表”保存的是使用GROUP BY语句聚合数据的表,例如,数据不是逻辑上冗余的。
5. 加快ALTER TABLE操作的速度
MySQL的ALTER TABLE操作的性能对大表来说是个大问题,MySQL执行大部分修改表结构操作的方法是用新的结构创建一个空表,从旧表中查找所有数据插入新表,然后删除旧表,所以大部分的ALTER TABLE操作将导致MySQL服务中断。
两种技巧:
- 先在一台不提供服务的机器上执行ALTER TABLE操作,然后和提供服务的主库进行切换;
- 影子拷贝,用要求的表结构创建一张和源表无关的新表,然后通过重命名和删除表操作交换两张表。
5.1 只修改.frm文件
不需要重建表的操作:
- 移除一个列的AUTO_INCREMENT属性;
- 增加、移除或更改ENUM和SET常量。
可以为想要的表结构创建一个新的.frm文件,然后用它替换掉已经存在的那张表的.frm文件。