导读
这篇文章我们来介绍如何来使用paddlepaddle来训练一个十二生肖的分类模型,前面两篇文章我们分别介绍了
paddlepaddle实现十二生肖的分类之数据的预处理(一)
paddlepaddle十二生肖分类之模型(ResNet)构建(二)
这篇文章我们主要来介绍一下如何进行模型的训练,以及预测
模型训练及预测
- 导包
import os
import paddle
from paddle.vision import transforms
from PIL import Image
import numpy as np
- 数据加载器
class ZodiacDatasets(paddle.io.Dataset):
"""
加载十二生肖数据
"""
def __init__(self,mode="train",data_root="data/signs",img_size=(224,224)):
super(ZodiacDatasets, self).__init__()
self.data_root = data_root
#判断mode是否正确
if mode not in ["train","valid","test"]:
assert("{} is illegal,mode need is one of train,valid,test")
#获取数据集的目录
self._data_dir_path = os.path.join(data_root,mode)
#获取十二生肖的类别名称
self._zodiac_names = sorted(os.listdir(self._data_dir_path))
#用来保存图片的路径
self._img_path_list = []
for name in self._zodiac_names:
img_dir_path = os.path.join(self._data_dir_path,name)
img_name_list = os.listdir(img_dir_path)
for img_name in img_name_list:
img_path = os.path.join(img_dir_path,img_name)
self._img_path_list.append(img_path)
#定义图像的预处理函数
if mode == "train":
self._transform = transforms.Compose([
transforms.RandomResizedCrop(img_size), #缩放图片并随机裁剪图片为指定shape
transforms.RandomHorizontalFlip(0.5), #随机水平翻转图片的概率为0.5
transforms.ToTensor(), #转换图片的格式由HWC ==> CHW
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]) #图片通道像素的标准化
])
else:
self._transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(img_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
def __getitem__(self,index):
"""根据index获取图片数据
"""
#获取图片的路径
img_path = self._img_path_list[index]
#获取图片的标签
img_label = img_path.split("/")[-2]
#将生肖的标签名称转换为数字标签
label_index = self._zodiac_names.index(img_label)
#读取图片
img = Image.open(img_path)
if img.mode != "RGB":
img = img.convert("RGB")
#图片的预处理
img = self._transform(img)
return img,np.array(label_index,dtype=np.int64)
def __len__(self):
"""获取数据集的大小
"""
return len(self._img_path_list)
- 删除非图片格式的文件以及被损坏的图片
import tqdm
def check_image(mode="train"):
#加载数据集
datasets = ZodiacDatasets(mode)
#获取数据集中所有的图片路径
img_path_list = datasets._img_path_list
#遍历数据集中的所有图片
for index,img_path in enumerate(tqdm.tqdm(img_path_list)):
try:
img,img_label = datasets[index]
except Exception as e:
print("remove image path:{}".format(img_path))
#删除数据异常的图片
os.remove(img_path)
#检查训练集,测试集和验证集中的图片数据是否正确
check_image("train")
check_image("valid")
check_image("test")
- 定义模型结构
import paddle
from paddle import nn
class BasicBlock(nn.Layer):
expansion = 1
def __init__(self,inchannels,channels,stride=1,downsample=None,
groups=1,base_width=64,dilation=1,norm_layer=None):
"""resnet18和resnet32的block
:param inchannels:block输入的通道数
:param channels:block输出的通道数
:param stride:卷积移动的步长
:param downsample:下采样
:param groups:
:param base_width:
:param dilation:
:param norm_layer: 标准化
"""
super(BasicBlock, self).__init__()
if norm_layer is not None:
norm_layer = nn.BatchNorm2D
if dilation > 1:
raise("BasicBlock not support dilation > 1")
#bias_attr设置为False表示卷积没有偏置项
self.conv1 = nn.Conv2D(inchannels,channels,3,padding=1,
stride=stride,bias_attr=False)
self.bn1 = norm_layer(channels)
# stride默认为1,kernel_size为3,padding为1等价于same的卷积
self.conv2 = nn.Conv2D(channels,channels,3,padding=1,bias_attr=False)
self.bn2 = norm_layer(channels)
self.relu = nn.ReLU()
self.downsample = downsample
self.stride = stride
def forward(self, x):
input = x
#block的第一层卷积
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
#block的第二层卷积
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
input = self.downsample(x)
#残差块
out += input
out = self.relu(out)
return out
class BottleneckBlock(nn.Layer):
expansion = 4
def __init__(self,inchannels,channels,stride=1,downsample=None,
groups=1,base_width=64,dilation=1,norm_layer=None):
"""resnet50/101/151的block
:param inchannels:block的输入通道数
:param channels:block的输出通道数
:param stride:卷积的步长
:param downsample:下采样
:param groups:
:param base_width:
:param dilation:
:param norm_layer:Batch Norm层
"""
super(BottleneckBlock, self).__init__()
#是否使用了BatchNorm
if norm_layer is None:
norm_layer = nn.BatchNorm2D
#计算block第一层卷积的输出通道数
width = int(channels * (base_width / 64)) * groups
#block的第一层卷积
self.conv1 = nn.Conv2D(inchannels,width,1,bias_attr=False)
self.bn1 = norm_layer(width)
#block的第二层卷积
self.conv2 = nn.Conv2D(width,width,3,
padding=dilation,
stride=stride,
dilation=dilation,
bias_attr=False)
self.bn2 = norm_layer(width)
#block的第三层卷积
self.conv3 = nn.Conv2D(width,channels*self.expansion,1,bias_attr=False)
self.bn3 = norm_layer(channels * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
self.stride = stride
def forward(self,x):
input = x
#第一层卷积
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
#第二层卷积
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
#第三层卷积
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
input = self.downsample(x)
#残差块
out += input
out = self.relu(out)
return out
class ResNet(nn.Layer):
def __init__(self,block,depth,num_classes=1000,with_pool=True):
super(ResNet, self).__init__()
layer_cfg = {
18:[2,2,2,2],
34:[3,4,6,3],
50:[3,4,6,3],
101:[3,4,23,3],
151:[3,8,36,3]
}
layers = layer_cfg[depth]
self.num_classes = num_classes
self.with_pool = with_pool
self._norm_layer = nn.BatchNorm2D
self.inchannels = 64
self.dilation = 1
self.conv1 = nn.Conv2D(3,self.inchannels,kernel_size=7,
stride=2,padding=3,bias_attr=False)
self.bn1 = self._norm_layer(self.inchannels)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2D(kernel_size=3,stride=2,padding=1)
#ResNet第一层
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
#全局平均池化层
if with_pool:
self.avgpool = nn.AdaptiveAvgPool2D((1, 1))
if num_classes > 0:
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self,block,channels,blocks,stride=1,dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inchannels != channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2D(
self.inchannels,
channels * block.expansion,
kernel_size=1,
stride=stride,
bias_attr=False
),
norm_layer(channels * block.expansion)
)
layers = []
layers.append(block(self.inchannels,channels,stride,downsample,1,64,
previous_dilation,norm_layer))
self.inchannels = channels * block.expansion
for _ in range(1,blocks):
layers.append(block(self.inchannels,channels,norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.with_pool:
x = self.avgpool(x)
if self.num_classes > 0:
x = paddle.flatten(x,1)
x = self.fc(x)
return x
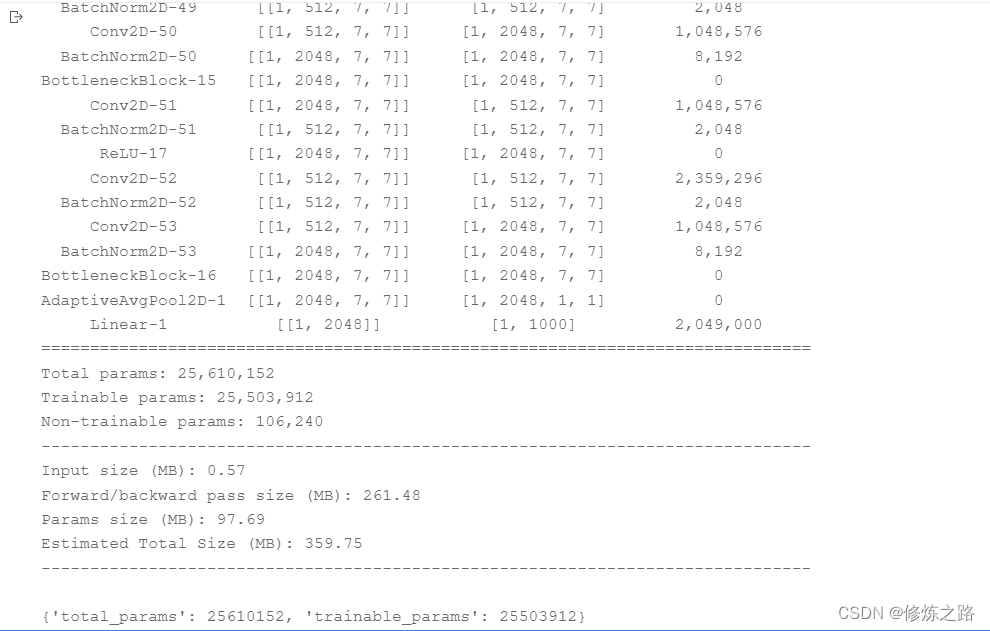
from paddle import summary
#构建ResNet50
resnet50 = ResNet(BottleneckBlock,50)
#打印ResNet网络结构
summary(resnet50,(1,3,224,224))
- 模型训练
在训练模型的时候,我采用的是ResNet50来训练的,指训练的了20个epoch,如果想要更高的模型精度,可以尝试加epoch增大和增加网络的层数,也可以通过多堆叠几个不同的模型来提高最终的精度
#定义网络结构,并且设置类别的数量
network = ResNet(BottleneckBlock,50,num_classes=12)
model = paddle.Model(network)
#获取训练数据和验证数据
#加载训练集
train_datasets = ZodiacDatasets(mode="train")
#加载验证集
valid_datasets = ZodiacDatasets(mode="valid")
#加载测试集
test_datasets = ZodiacDatasets(mode="test")
#定义训练的轮数
epochs = 20
#设置学习率
learning_rate = 0.01
#设置batch size
batch_size = 128
#设置权重衰减
L2_decay_factor = 0.000001
step_each_epoch = len(train_datasets) // batch_size
#使用余弦退火来调整学习率
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate,
T_max=step_each_epoch*epochs)
optimizer = paddle.optimizer.Momentum(learning_rate=lr,
parameters=network.parameters(),
weight_decay=paddle.regularizer.L2Decay(L2_decay_factor))
#设置损失函数
loss = paddle.nn.CrossEntropyLoss()
#设置评估函数
evaluate_fn = paddle.metric.Accuracy(topk=(1,5))
#模型训练配置
model.prepare(optimizer,loss,evaluate_fn)
#可视化visualDL的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir="visualdl_log")
#启动模型训练
model.fit(train_datasets,valid_datasets,epochs=epochs,
batch_size=batch_size,shuffle=True,verbose=1,
save_dir="./save_models/",callbacks=[visualdl])

- 模型预测
import cv2
from matplotlib import pyplot as plt
#定义网络结构,并且设置类别的数量
network = ResNet(BottleneckBlock,50,num_classes=12)
model = paddle.Model(network)
#加载模型
model.load("save_models/19")
#设置模型预测环境
model.prepare()
#加载数据集
test_datasets = ZodiacDatasets("test")
#获取标签的名称
label_names = test_datasets._zodiac_names
#获取测试集中所有的图片路径
img_path_list = test_datasets._img_path_list
#用来记录绘制图片的位置
img_index = 1
col_num = 4
row_num = 3
#设置图片的大小
plt.figure(figsize=(8,8))
#取12张图片来预测
for i in range(45,len(img_path_list),52):
#获取图片的路径
img_path = img_path_list[i]
original_img = cv2.imread(img_path)
original_img = cv2.cvtColor(original_img,cv2.COLOR_BGR2RGB)
#获取图片的数据
img,img_label_index = test_datasets[i]
#获取图片的真实标签
img_label = label_names[img_label_index]
img = paddle.unsqueeze(img,axis=0)
#模型预测
out = model.predict_batch(img)
#获取预测的标签
pred_label = label_names[out[0].argmax()]
#绘制图片
plt.subplot(row_num,col_num,img_index)
plt.imshow(original_img)
plt.title("predict:{}\n true:{}".format(pred_label,img_label))
plt.xticks([])
plt.yticks([])
img_index += 1
plt.show()
