MySQL体系架构
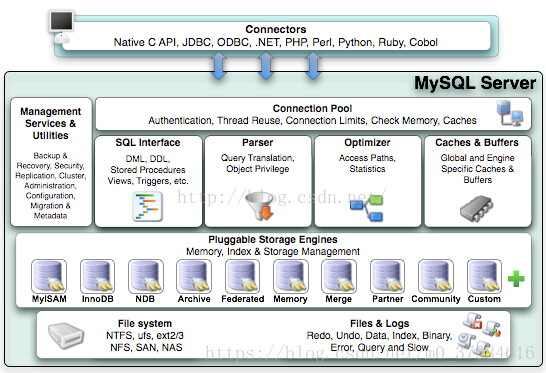
连接池组件、管理服务和工具组件、SQL接口组件、查询分析器组件、优化器组件、缓冲组件、插件式存储引擎、物理文件;
1、连接层:主要完成一些类似于连接处理,授权认证及相关的方案;
2、服务层:主要完成大多数核心服务功能;
3、引擎层:负责MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信;
注:储存引擎式基于表的,而不是数据库的;
MySQL存储引擎
InnoDB 和 MyISAM区别:
1、InnoDB支持主外键、事务;
2、InnoDB是行锁,操作时候只锁一行数据,适合高并发;MyISAM是表索;
3、InnoDB不仅缓存索引,还缓存真实数据;MyISAM只缓存索引;
4、InnoDB需要表空间大;
5、InnoDB关注事务,MyISAM关注性能(查);
SQL优化
问:执行时间长,等待时间长
可能是SQL语句太次,索引失效,关联查询太多join,服务器调优及参数设置(缓冲池)
SQL执行顺序:
FROM <LEFT_TABLE>
ON <JOIN_CONDITION>
<JOIN_TYPR> JOIN <RIGHT_TABLE>
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
ORDER BYJOIN详解:
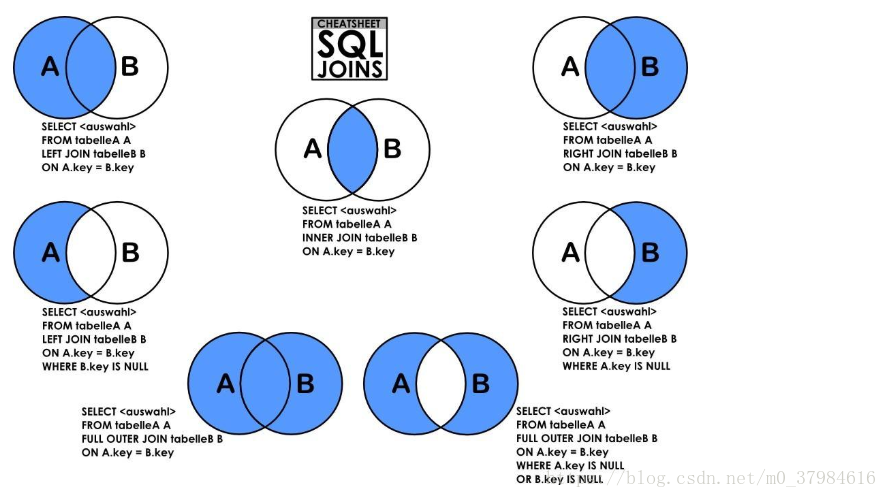
最后两个由于MySQL不支持FULL OUTER JOIN,所以用 UNION 连接,即1和2的语句进行UNION得到6,3和4的语句进行UNION得到7。
索引
索引:排好序的快速查找数据结构;
优点:提高数据检索的效率,降低数据排序的成本;
缺点:会降低更新表的速度;
单值索引:一个索引只包含单个列,一个表可以由多个单值索引;
唯一索引:索引列的值必须唯一,允许有空值;
复合索引:即一个索引包含多个列;
CREATE [UNIQUE] INDEX indexname ON tablename(columnname(length));
ALTER table tablename ADD [UNIQUE] INDEX indexname (columnname(length));索引结构:
BTree索引,Hash索引,full-text全文索引,R-Tree索引;
B+树与B树的不同在于:
(1)所有关键字存储在叶子节点,非叶子节点不存储真正的data
(2)为所有叶子节点增加了一个链指针
下图是BTree索引数据结构
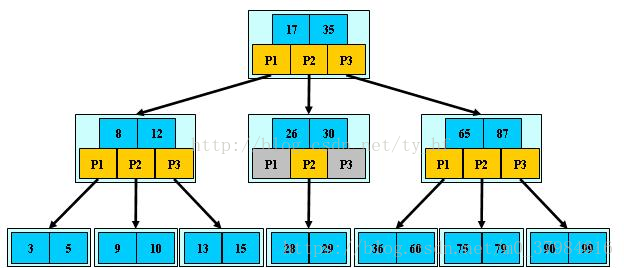
索引性能分析:
Explain(执行计划):
使用:EXPLAIN + sql语句;
作用:
1、表的读取顺序;
2、数据读取操作的操作类型;
3、哪些索引可以使用;
4、那些索引被实际使用;
5、表之间的引用;
6、每张表有多少行被优化器查询;

id
select 查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序;
有三种情况:
1、id相同,执行顺序由上至下;
2、id不同,如果是子查询,id的序号会递增,id值越大优先级越高,先被执行 ;
3、id有相同,有不同,相同的可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,先被执行;(table 列中的 derived 的意思是衍生,由 id 衍生的)
select_type

table
显示这一行数据是哪个表的;
type
性能高低从上到下的顺序;

possible_keys
显示可能应用在这张表中的索引,可以是多个;
查询涉及到的字段上若存在索引,则被列出,但不一定被使用;
key
实际使用到的索引,null代表没使用索引。
查询若使用覆盖索引,则该索引仅出现在key列表中;
key_len
表示索引中使用的字节数,越小越好,显示的值为索引字段的最大可能长度,并非实际使用长度。
ref
显示索引的哪一列被使用了,最好是常量;
rows
根据表统计信息及索引选用情况,大致估计出找到所需的记录所需要读取的行数;
extra
包含不适合在其他列展示的但重要的额外信息

usingwhere 使用where语句;
usingbuffer 使用缓冲池;
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
所以无论那个表大,用not exists都比not in要快。not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。
Join连接索引分析
单表分析
例:select id from A where c1 = 1 and c2 > 1 order by v1 desc limit 1;
建立联合索引(c1,c2,v1),但explain时候发现 type 是range,extra中使用using filesort,这需要优化;
产生原因:按照BTree索引工作原理,先排序c1,如果c1相同,排序c2,c2相同在排序v1,当c2字段在联合索引中处于中间位置,因为c2 > 1条件是一个范围值(range),MySQL无法利用索引在对后面的v1部分进行索引。所以建立(c1,v1)解决这个问题。
双表分析
左连接加在右表的索引,右连接加在左表的索引;
Left Join 条件用于确定如何从右表搜索行,左边数据一定有,所以右边数据一定要建索引。
三表分析
建索引和双表的原理相同;
总结
尽可能减少Join语句的NestedLoop的循环总次数,永远用小结果集驱动大的结果集;
优先优化NestedLoop的内层循环;
保证Join语句中被驱动表上Join条件字段已经被索引;
索引失效
1、最好全值匹配;
2、最左前缀法则:如果索引了多列,查询从索引的最左前列开始,且不能跳过索引中的列;
3、不在索引列上做任何操作(计算,函数,类型转换),会导致索引时校而转向全表扫描;
4、存储引擎不能使用索引中范围条件右边的列,即范围之后全失效;
5、尽量使用覆盖索引,只访问索引的查询(索引列和查询列一致),减少selec *;
6、MySQL在使用不等于的时候无法使用索引会导致全表扫描;
7、is null,is not null 也无法使用索引;
8、like 以通配符开头(’%aa‘)索引会失效,变成全表扫描;
9、字符串不加单引号,索引失效;
10、少用 or,用它来连接时候会索引失效
覆盖索引:建索引的列和要查询的列相同,例如索引列是c1,c2,select 查询的也是c1,c2;
定值是常量,范围之后必失效,最终看排序,一般order by 是给个范围;
group by 分组,分组之前必排序,顺序不对会有临时表产生;
永远小表驱动大表
in 和 exists 选择:
// 工作原理,先查B表数据,然后查A的 id
select * from A where id in (select id from B)
// 工作原理,先查A表的id,然后查B表的id
select * from A a where exists (select 1 from B b where a.id = b.id )
// 结论:当B表的数据小于A表时候用 in;当A表数据小时候用 exists
Order By 排序
MySQL支持两种排序,index和fileSort,index效率高,它指MySQL扫描索引本身完成排序。
Order By满足两种情况使用index:
1、Order By 语句使用索引最左前列
2、使用where子句与Order By子句条件组合满足索引最左前列
如果不在索引列上,fileSort有两种算法,4.1版本之前双路排序,进行两次IO;之后单路排序,进行一次IO;
Order By时不要select *,只查询所需要的字段;当两种算法的数据超出sort_buffer的容量会创建tmp文件进行合并运算,导致多次IO,所以需要尝试提高sort_buffer_size 和
max_length_for_sort_ size。
为排序使用索引,MySQL能为排序与查询使用相同的索引
查询截取分析
1、观察,查看慢SQL情况;
2、开启查询日志,设置阀值;
3、explain 分析;
4、show profile 查看执行细节和生命周期情况
5、dba 进行参数调优
慢查询日志
响应时间超过long_query_tine的SQL,被记录到慢查询日志中。
// SHOW VARIABLES LIKE '%slow_query_log%' ; 查看是否开启,默认没开启
// set global slow_quary_log = 1; 开启,仅本数据库有效,重启MySQL之后失效。
// show variables like '%long_query_time%'; 查看当前多少秒算慢
// set global long_query_time = 3; 设置慢的阙值时间
// show global status like '%Slow_queries%'; 查看当前数据库有多少条慢SQLShow Profile
是MySQL提供可以用来分析当前会话中语句执行的资源情况,可以用于SQL的调优的测量。
默认关闭,并保存最近15次结果;
// set profiling = on ; 开启
// show profiles; 查看执行过的sql
// SHOW PROFILE cpu,block io FOR QUERY 87; 查看这个执行sql 的生命周期相关信息。converting HEAP to MyISAM 查询结果太大,内存不够用了往磁盘上搬;
Creating tmp table 创建临时表,拷贝数据到临时表,用完再删除;
Copying to tmp table on disk 把内存中临时表复制到磁盘,危险!
locked
全局查询日志
不可以在生产环境中开启这个功能。
// set global general_log = 1;
// set global log_output = 'TABLE';
// 此后,你所有编写的sql语句都会记录到mysql库中的general_log表;MySQL锁机制
分类可以分为读锁(共享锁)和写锁;表锁和行锁;
表锁:偏向MyISAM存储引擎,开销小,加锁快,并发度低;
加锁:lock table tablename read,tablename2 write;解锁:unlock tables;
查看哪些表被锁了 show open tables;
加读锁

加写锁
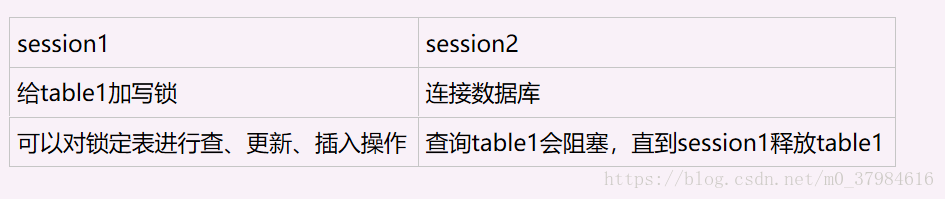
MyISAM在执行查询语句前,会自动给涉及的所有表加读锁,在执行增删改前,会自动给涉及的表加写锁。
1、对MyISAM表的操作(加读锁),不会阻塞其他进程对同一表的读请求,但会阻塞对同一表的写请求,只有当读锁释放后,才会执行其他进程的写操作。
2、对MyISAM表的操作(加写锁),会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其他进程的读写操作。
分析表锁定
show status likes ‘table%’;
Table_locks_immediate:产生表级锁定的次数;
Table_locks_waited:出现表级锁定争用而发生等待的次数,不能立即获取锁的次数,每等待一次锁值加1;
MyISAM的读写锁调度是写优先,所以不适合做写为主表的引擎。
行锁:偏向InnoDB存储引擎,开销大,会出现死锁,锁的粒度最小,发生锁冲突的概率最低,并发度高。
InnoDB与MyISAM最大不同是InnoDB支持事务,并且采用行级锁;

事务隔离级别:未提交读,已提交读,可重复度,可序列化。MySQL默认是可重复读。
无索引,行锁变表锁
当我们使用范围条件而不是相等条件检索数据,并请求共享排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但不存在的记录,叫做间隙;InnoDB也会对这个间隙加锁。

主从复制
复制的基本原理
slave会从master读取binlog来进行数据同步。
MySQL复制过程分为三步:
1、master将改变记录到二进制日志(binary log);
2、slave将master的binary log events 拷贝到它的中继日志(relay log);
3、slave重做中继日志的时间,将改变应用到自己的数据库中,MySQL复制是异步的且串行化;
每个slave只有一个master,只能有一个唯一的服务器ID,每个master可以有多个salve;
DML
DML(data manipulation language)数据操纵语言,比如SELECT、UPDATE、INSERT、DELETE;
DDL
DDL(data definition language)数据库定义语言,CREATE、ALTER、DROP等;
DCL
DCL(Data Control Language)数据库控制语言,grant,deny,revoke等;
MyISAM使用B-Tree实现主键索引、唯一索引和非主键索引。
InnoDB中非主键索引使用的是B-Tree数据结构,而主键索引使用的是B+Tree。
二级索引
mysql中每个表都有一个聚簇索引(clustered index ),除此之外的表上的每个非聚簇索引都是二级索引,又叫辅助索引(secondary indexes)。
以InnoDB来说,每个InnoDB表具有一个特殊的索引称为聚集索引。如果您的表上定义有主键,该主键索引是聚集索引。如果你不定义为您的表的主键时,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚集索引。如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。