文章目录
1.索引是什么?
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据
库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数
据结构上实现高级查找算法,这种数据结构就是索引。如下面的示意图所示 :
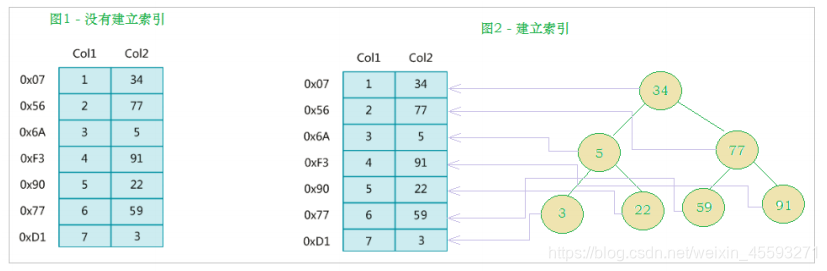
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是
一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一
个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。索引是数据
库中用来提高性能的最常用的工具。
2.索引的优势和劣势
优势
1) 类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
2) 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
劣势
mysql 安装完成之后, 会自动生成一个随机的密码, 并且保存在一个密码文件中 : /root/.mysql_secret mysql -u root -p 登录之后, 修改密码 : set password = password(‘itcast’); 授权远程访问 : grant all privileges on . to ‘root’ @’%’ identified by ‘itcast’; flush privileges; 12345678910111213
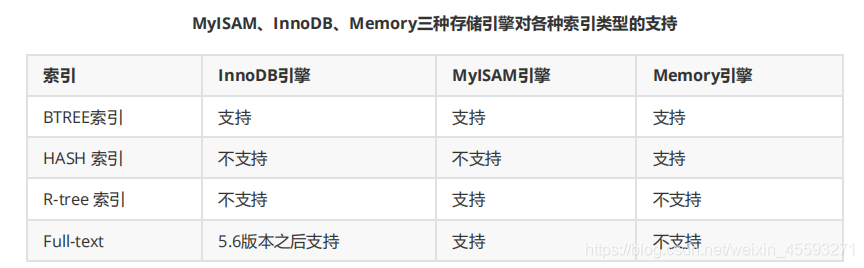
MyISAM、InnoDB、Memory三种存储引擎对各种索引类型的支持
索引 InnoDB引擎 MyISAM引擎 Memory引擎
BTREE索引 支持 支持 支持
HASH 索引 不支持 不支持 支持
R-tree 索引 不支持 支持 不支持
Full-text 5.6版本之后支持 支持 不支持
1) 实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间
的。
2) 虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。因为
更新表时,MySQL 不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所
带来的键值变化后的索引信息。
3.索引的结构
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定完全相同,
也不是所有的存储引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引:
BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
HASH 索引:只有Memory引擎支持 , 使用场景简单 。
R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常
使用较少,不做特别介绍。
Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从
Mysql5.6版本开始支持全文索引。
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。其中
聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引,统称为 索引。
BTREE 结构
BTree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
树中每个节点最多包含m个孩子。
除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。
若根节点不是叶子节点,则至少有两个孩子。
所有的叶子节点都在同一层。
每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
以5叉BTree为例,key的数量:公式推导[ceil(m/2)-1] <= n <= m-1。所以 2 <= n <=4 。当n>4时,中间节点分裂到
父节点,两边节点分裂。
例子:
插入 C N G A H E K Q M F W L T Z D P R X Y S 数据为例。
演变过程如下:
1). 插入前4个字母 C N G A
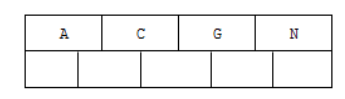
2). 插入H,n>4,中间元素G字母向上分裂到新的节点
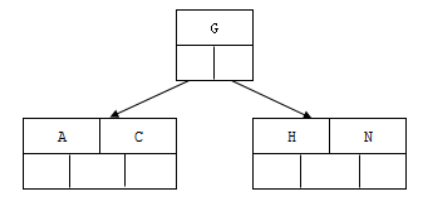
3). 插入E,K,Q不需要分裂
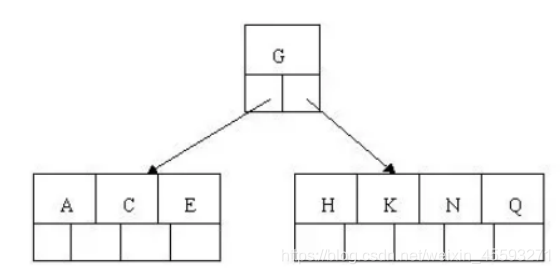
4). 插入M,中间元素M字母向上分裂到父节点G
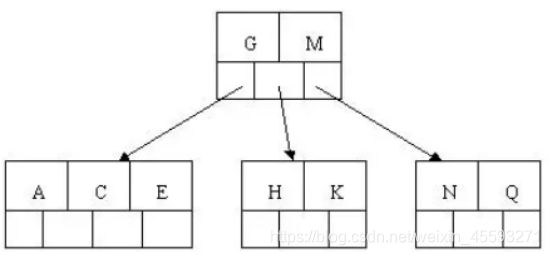
5). 插入F,W,L,T不需要分裂
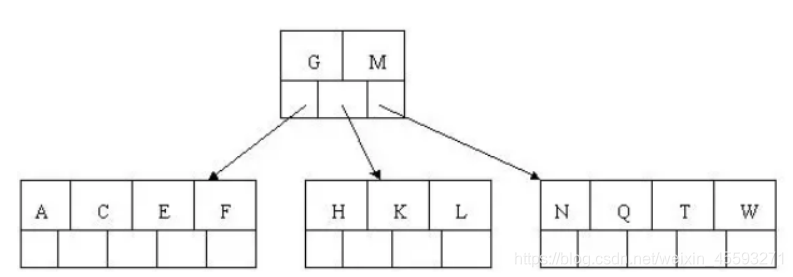
6). 插入Z,中间元素T向上分裂到父节点中
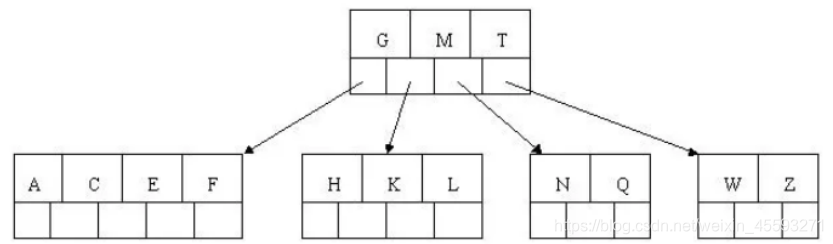
7). 插入D,中间元素D向上分裂到父节点中。然后插入P,R,X,Y不需要分裂
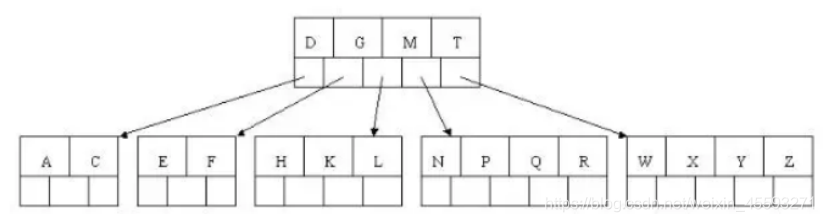
8). 最后插入S,NPQR节点n>5,中间节点Q向上分裂,但分裂后父节点DGMT的n>5,中间节点M向上分裂
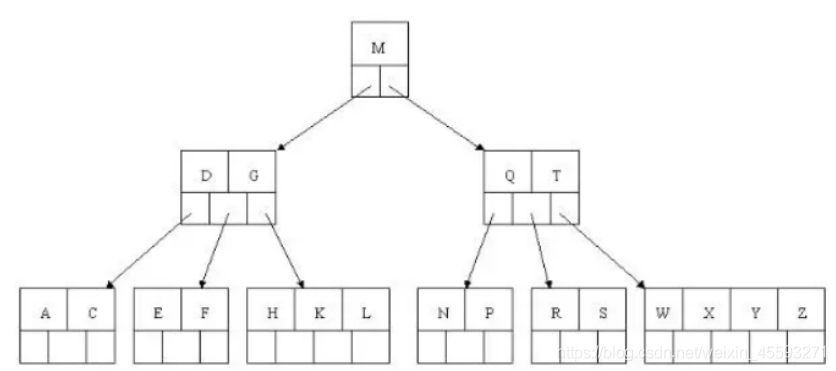
B+TREE 结构
B+Tree为BTree的变种,B+Tree与BTree的区别为:
1). n叉B+Tree最多含有n个key,而BTree最多含有n-1个key。
2). B+Tree的叶子节点保存所有的key信息,依key大小顺序排列。
3). 所有的非叶子节点都可以看作是key的索引部分。
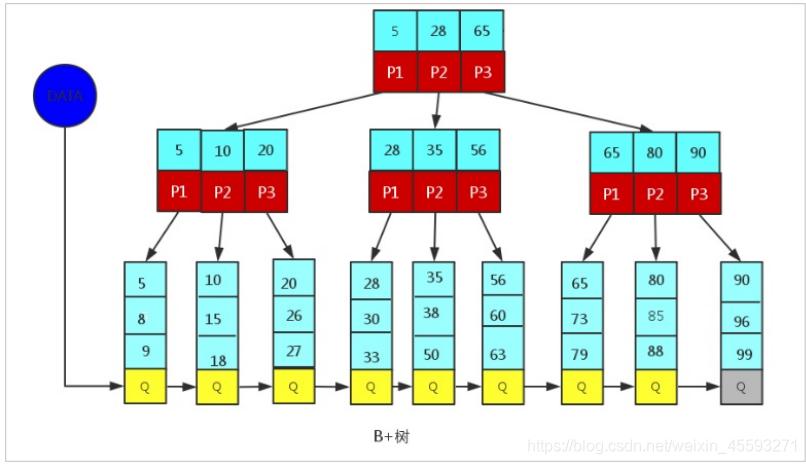
由于B+Tree只有叶子节点保存key信息,查询任何key都要从root走到叶子。所以B+Tree的查询效率更加稳定。
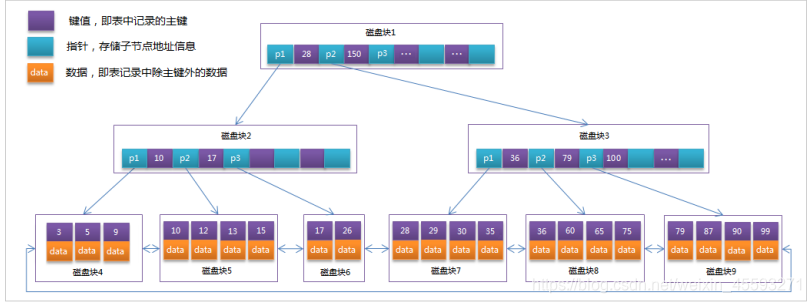
MySQL中的B+Tree
MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指
针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
MySQL中的 B+Tree 索引结构示意图:
4.索引的分类
1) 单值索引 :即一个索引只包含单个列,一个表可以有多个单列索引
2) 唯一索引 :索引列的值必须唯一,但允许有空值
3) 复合索引 :即一个索引包含多个列
5.索引的基本语法
索引在创建表的时候,可以同时创建, 也可以随时增加新的索引。
准备环境
create database demo_01 default charset=utf8mb4;
use demo_01; CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL,
PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2);
insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China');
insert into `country` (`country_id`, `country_name`) values(2,'America');
insert into `country` (`country_id`, `country_name`) values(3,'Japan');
insert into `country` (`country_id`, `country_name`) values(4,'UK');
创建索引
语法 :
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
示例 : 为city表中的city_name字段创建索引 ;

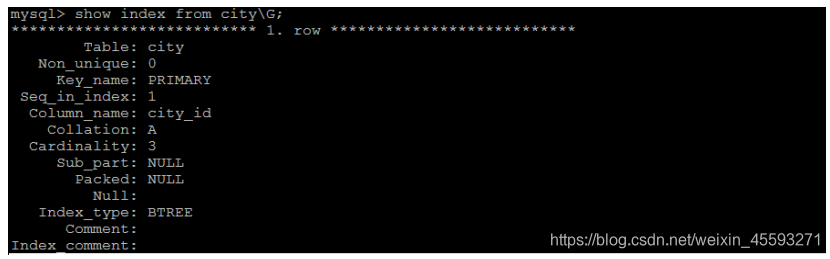
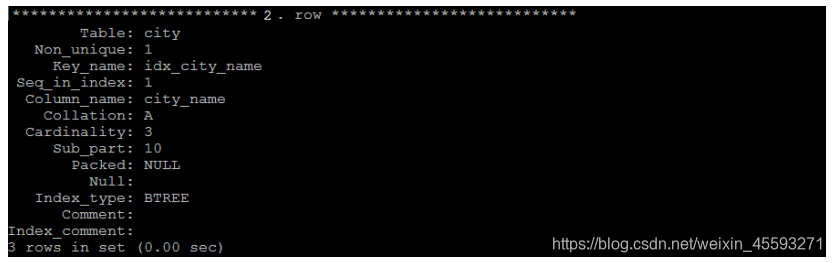
查看索引
语法:
show index from table_name;
示例:查看city表中的索引信息;
删除索引
语法 :
DROP INDEX index_name ON tbl_name;
示例 : 想要删除city表上的索引idx_city_name,可以操作如下:

ALTER命令
1). alter table tb_name add primary key(column_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2). alter table tb_name add unique index_name(column_list);
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3). alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出现多次。
4). alter table tb_name add fulltext index_name(column_list); 该语句指定了索引为FULLTEXT, 用于全文索引
6.索引的设计原则
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用效率,更高
效的使用索引。
1.对查询频次较高,且数据量比较大的表建立索引。
2.索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑
选最常用、过滤效果最好的列的组合。
3.使用唯一索引,区分度越高,使用索引的效率越高。
4.索引可以有效的提升查询数据的效率,但索引数量不是多多益善,索引越多,维护索引的代价自然也就水涨
船高。对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,降低
DML操作的效率,增加相应操作的时间消耗。另外索引过多的话,MySQL也会犯选择困难病,虽然最终仍然
会找到一个可用的索引,但无疑提高了选择的代价。
5.使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效
率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有
效的提升MySQL访问索引的I/O效率。
6.利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了
组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
7.优化SQL步骤
在应用的的开发过程中,由于初期数据量小,开发人员写 SQL 语句时更重视功能上的实现,但是当应用系统正式
上线后,随着生产数据量的急剧增长,很多 SQL 语句开始逐渐显露出性能问题,对生产的影响也越来越大,此时
这些有问题的 SQL 语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化,本章将详细介绍在 MySQL
中优化 SQL 语句的方法。
当面对一个有 SQL 性能问题的数据库时,我们应该从何处入手来进行系统的分析,使得能够尽快定位问题 SQL 并
尽快解决问题。
查看SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。show
[session|global] status 可以根据需要加上参数“session”或者“global”来显示 session 级(当前连接)的计结果和
global 级(自数据库上次启动至今)的统计结果。如果不写,默认使用参数是“session”。
下面的命令显示了当前 session 中所有统计参数的值:
show status like 'Com_______';

show status like 'Innodb_rows_%';

Com_xxx 表示每个 xxx 语句执行的次数,我们通常比较关心的是以下几个统计参数。
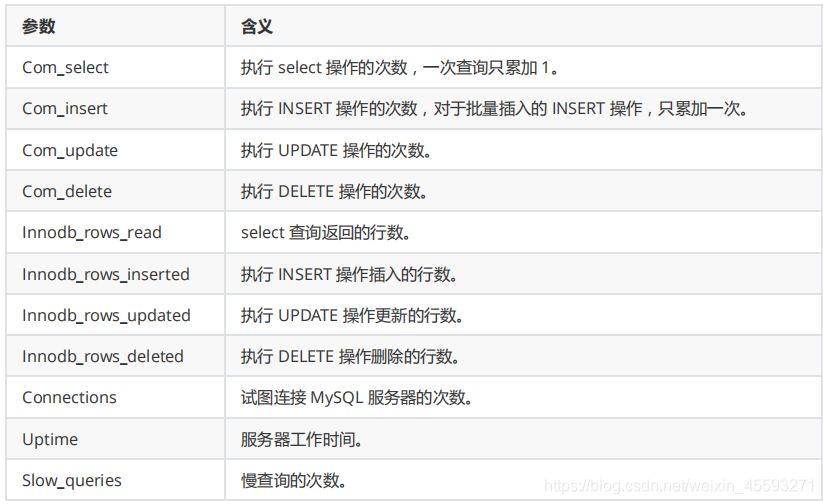
Com_*** : 这些参数对于所有存储引擎的表操作都会进行累计。
Innodb_*** : 这几个参数只是针对InnoDB 存储引擎的,累加的算法也略有不同。
定位低效率执行SQL
可以通过以下两种方式定位执行效率较低的 SQL 语句。
1.慢查询日志 : 通过慢查询日志定位那些执行效率较低的 SQL 语句,用–log-slow-queries[=file_name]选项启
动时,mysqld 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件。
2.show processlist : 慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询
日志并不能定位问题,可以使用show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否
锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。

1) id列,用户登录mysql时,系统分配的"connection_id",可以使用函数connection_id()查看
2) user列,显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句
3) host列,显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户
4) db列,显示这个进程目前连接的是哪个数据库
5) command列,显示当前连接的执行的命令,一般取值为休眠(sleep),查询(query),连接 (connect)等
6) time列,显示这个状态持续的时间,单位是秒
7) state列,显示使用当前连接的sql语句的状态,很重要的列。state描述的是语句执行中的某一个状态。一 个sql语句,以查询为例,可能需要经过copying to tmp table、sorting result、sending data等状态 才可以完成
8) info列,显示这个sql语句,是判断问题语句的一个重要依据
explain分析执行计划
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN或者 DESC命令获取 MySQL如何执行 SELECT 语句
的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
查询SQL语句的执行计划 :
explain select * from tb_item where id = 1;

explain select * from tb_item where title = '阿尔卡特 (OT-979) 冰川白 联通3G手机3';

例子:
环境准备:
CREATE TABLE `t_role` (
`id` varchar(32) NOT NULL,
`role_name` varchar(255) DEFAULT NULL,
`role_code` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_role_name` (`role_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_user` (
`id` varchar(32) NOT NULL,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_role` (
`id` int(11) NOT NULL auto_increment ,
`user_id` varchar(32) DEFAULT NULL,
`role_id` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_ur_user_id` (`user_id`),
KEY `fk_ur_role_id` (`role_id`),
CONSTRAINT `fk_ur_role_id` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ON
DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `fk_ur_user_id` FOREIGN KEY (`user_id`) REFERENCES `t_user` (`id`) ON
DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `t_user` (`id`, `username`, `password`, `name`) values('1','super','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe',' 超级管理员');
insert into `t_user` (`id`, `username`, `password`, `name`) values('2','admin','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe',' 系统管理员');
insert into `t_user` (`id`, `username`, `password`, `name`) values('3','itcast','$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui', 'test02');
insert into `t_user` (`id`, `username`, `password`, `name`) values('4','stu1','$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa','学 生1');
insert into `t_user` (`id`, `username`, `password`, `name`) values('5','stu2','$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm','学 生2');
insert into `t_user` (`id`, `username`, `password`, `name`) values('6','t1','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','老师 1');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5','学 生','student','学生');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7','老 师','teacher','老师');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8','教 学管理员','teachmanager','教学管理员'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9','管 理员','admin','管理员');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10','超 级管理员','super','超级管理员');
INSERT INTO user_role(id,user_id,role_id) VALUES(NULL, '1', '5'),(NULL, '1', '7'), (NULL, '2', '8'),(NULL, '3', '9'),(NULL, '4', '8'),(NULL, '5', '10') ;
explain 之 id
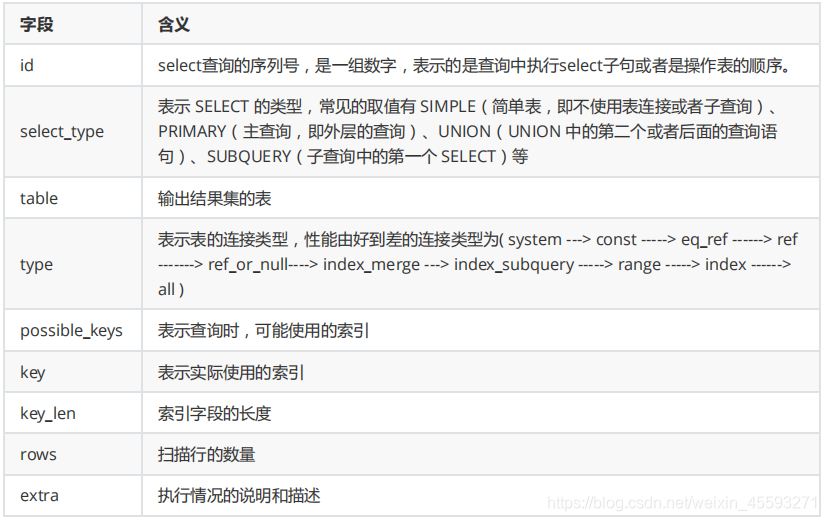
id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id 情况有三种
:
1) id 相同表示加载表的顺序是从上到下。
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id ;

2) id 不同id值越大,优先级越高,越先被执行。
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'))

3) id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越
大,优先级越高,越先执行。
EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` = '2') a WHERE r.id = a.role_id ;

explain 之 select_type
表示 SELECT 的类型,常见的取值,如下表所示:

explain 之 table
展示这一行的数据是关于哪一张表的
explain 之 type
type 显示的是访问类型,是较为重要的一个指标,可取值为:

结果值从最好到最坏以此是:
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >
unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
explain 之 key
possible_keys : 显示可能应用在这张表的索引, 一个或多个。
key : 实际使用的索引, 如果为NULL, 则没有使用索引。
key_len : 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前 提下, 长度越短越好 。
explain 之 rows
扫描行的数量。
explain 之 extra
其他的额外的执行计划信息,在该列展示 。

show profile分析SQL
Mysql从5.0.37版本开始增加了对 show profiles 和 show profile 语句的支持。show profiles 能够在做SQL优化时
帮助我们了解时间都耗费到哪里去了。
通过 have_profiling 参数,能够看到当前MySQL是否支持profile:

默认profiling是关闭的,可以通过set语句在Session级别开启profiling:

set profiling=1; //开启profiling 开关;
通过profile,我们能够更清楚地了解SQL执行的过程。
首先,我们可以执行一系列的操作,如下图所示:
show databases;
use db01;
show tables;
select * from tb_item where id < 5;
select count(*) from tb_item;
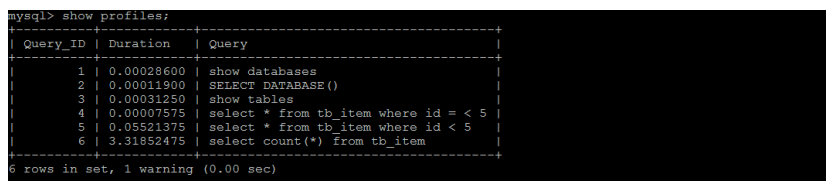
执行完上述命令之后,再执行show profiles 指令, 来查看SQL语句执行的耗时:
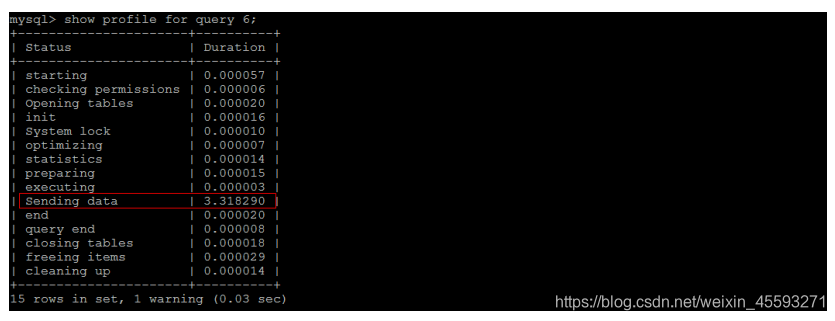
通过show profile for query query_id 语句可以查看到该SQL执行过程中每个线程的状态和消耗的时间:
TIP :
Sending data 状态表示MySQL线程开始访问数据行并把结果返回给客户端,而不仅仅是返回个客户端。由于
在Sending data状态下,MySQL线程往往需要做大量的磁盘读取操作,所以经常是整各查询中耗时最长的状态。
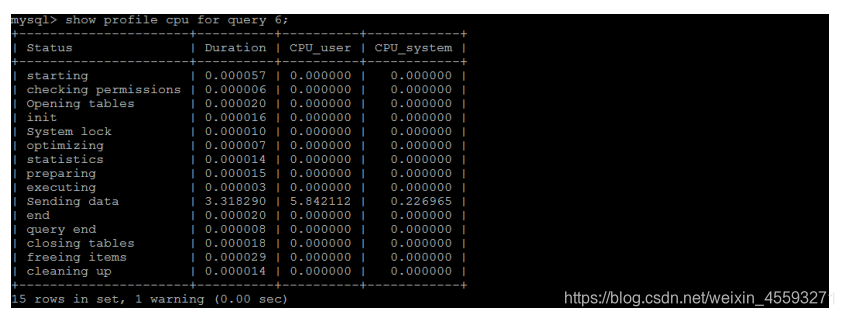
在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、block io 、context switch、page faults等
明细类型类查看MySQL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间 :
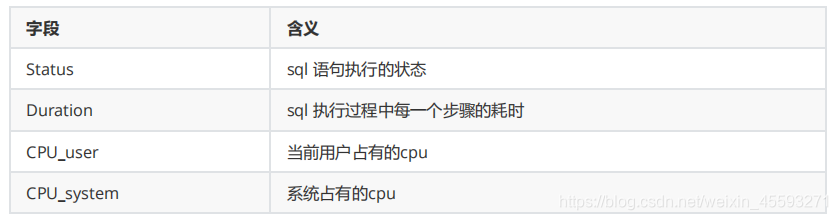
8.使用索引
索引是数据库优化最常用也是最重要的手段之一, 通过索引通常可以帮助用户解决大多数的MySQL的性能优化问
题。
验证索引提升查询效率
在我们准备的表结构tb_item 中, 一共存储了 300 万记录;
A. 根据ID查询
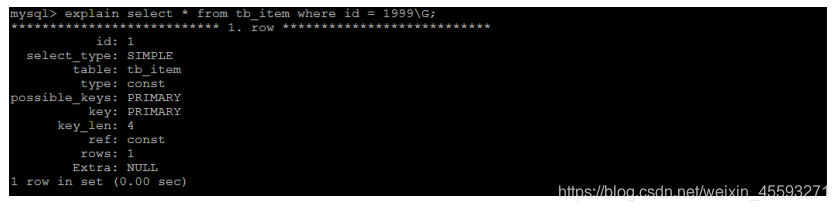
select * from tb_item where id = 1999\G;
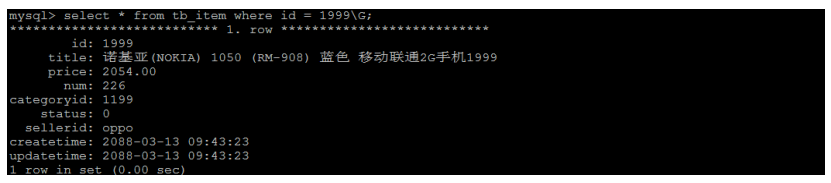
查询速度很快, 接近0s , 主要的原因是因为id为主键, 有索引;
2). 根据 title 进行精确查询
select * from tb_item where title = 'iphoneX 移动3G 32G941'\G;
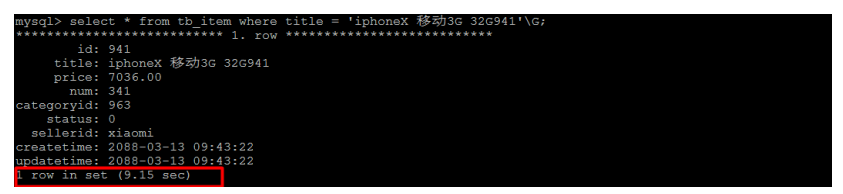
查看SQL语句的执行计划 :
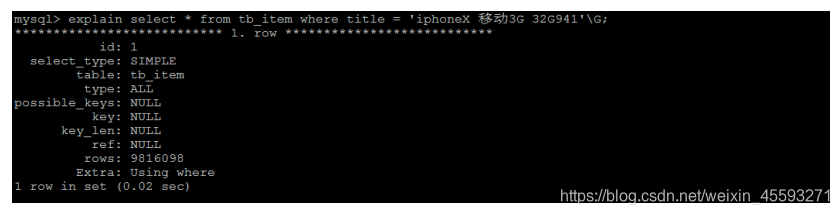
处理方案 , 针对title字段, 创建索引 :
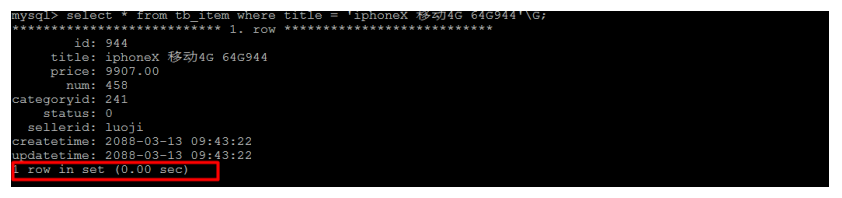
create index idx_item_title on tb_item(title);

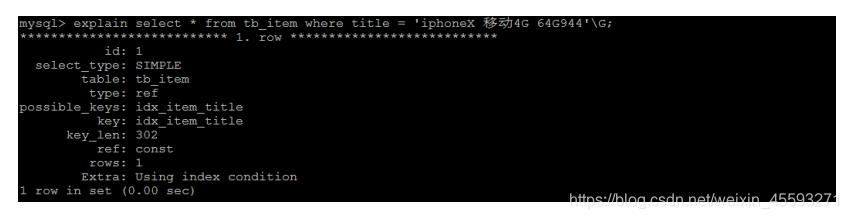
索引创建完成之后,再次进行查询 :
通过explain , 查看执行计划,执行SQL时使用了刚才创建的索引
9.如何避免索引失效的情况
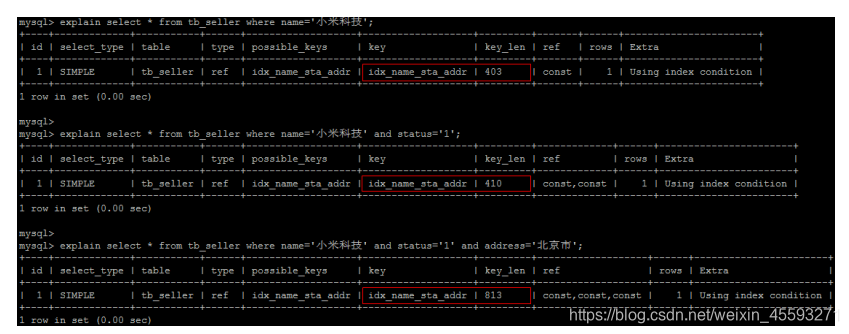
1). 全值匹配 ,对索引中所有列都指定具体值。
改情况下,索引生效,执行效率高。
explain select * from tb_seller where name='小米科技' and status='1' and address='北京 市'\G;

2). 最左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列。
匹配最左前缀法则,走索引:
违法最左前缀法则 , 索引失效:
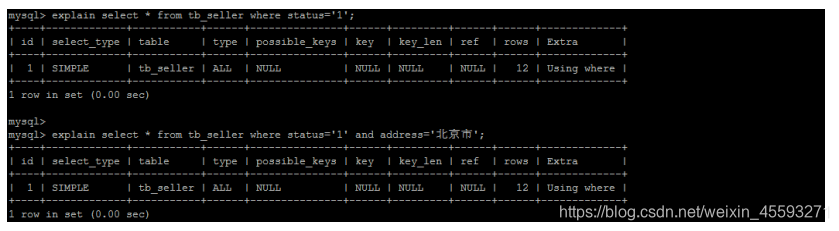
如果符合最左法则,但是出现跳跃某一列,只有最左列索引生效:

3). 范围查询右边的列,不能使用索引 。
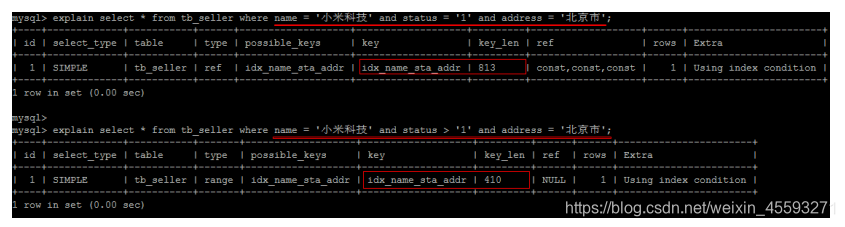
根据前面的两个字段name , status 查询是走索引的, 但是最后一个条件address 没有用到索引。
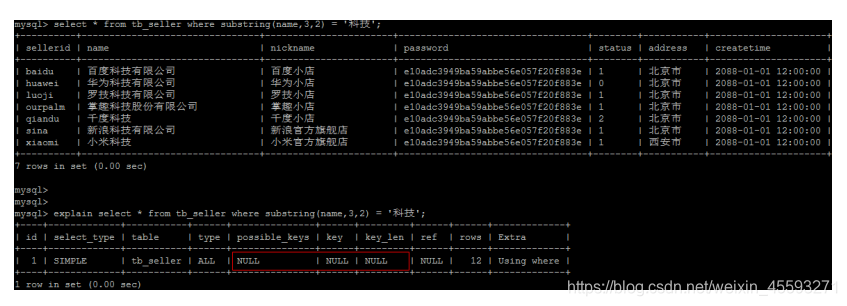
4). 不要在索引列上进行运算操作, 索引将失效。
5). 字符串不加单引号,造成索引失效。
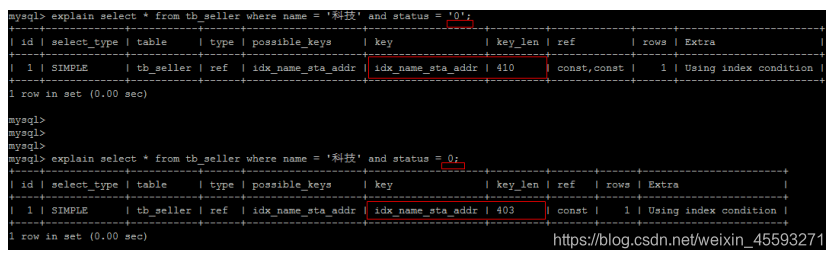
由于,在查询是,没有对字符串加单引号,MySQL的查询优化器,会自动的进行类型转换,造成索引失效。
6). 尽量使用覆盖索引,避免select *
尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少select * 。
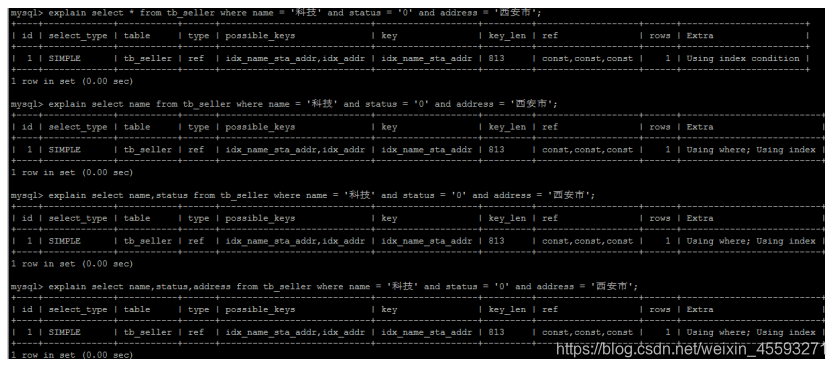
如果查询列,超出索引列,也会降低性能。

TIP :
using index :使用覆盖索引的时候就会出现
using where:在查找使用索引的情况下,需要回表去查询所需的数据
using index condition:查找使用了索引,但是需要回表查询数据 using index ;
using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表 查询数据
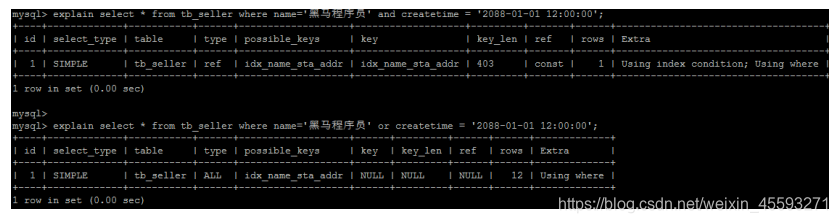
7). 用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
示例,name字段是索引列 , 而createtime不是索引列,中间是or进行连接是不走索引的 :
explain select * from tb_seller where name='黑马程序员' or createtime = '2088-01-01 12:00:00'\G;
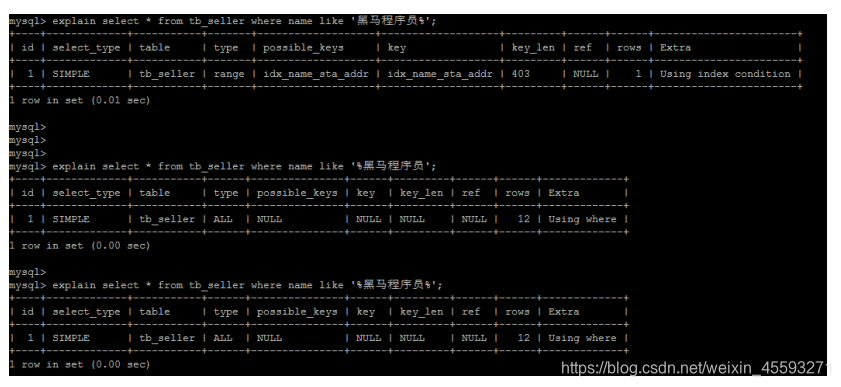
8). 以%开头的Like模糊查询,索引失效。
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
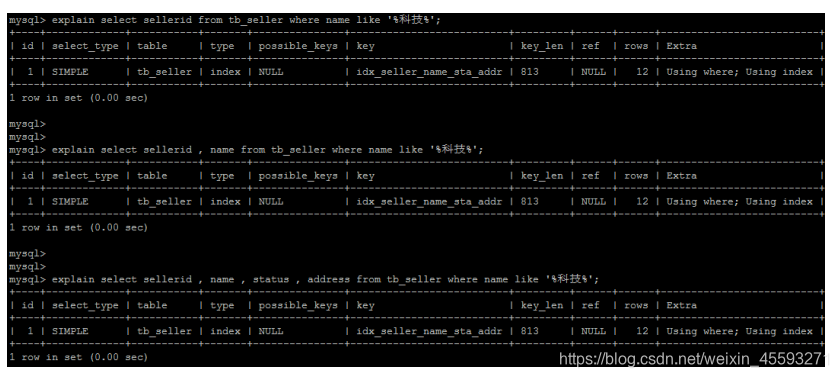
解决方案 :
通过覆盖索引来解决
9). 如果MySQL评估使用索引比全表更慢,则不使用索引。
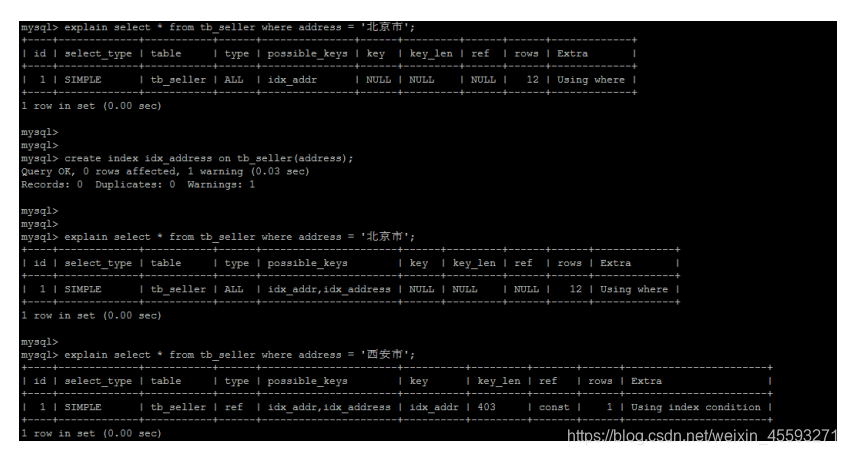
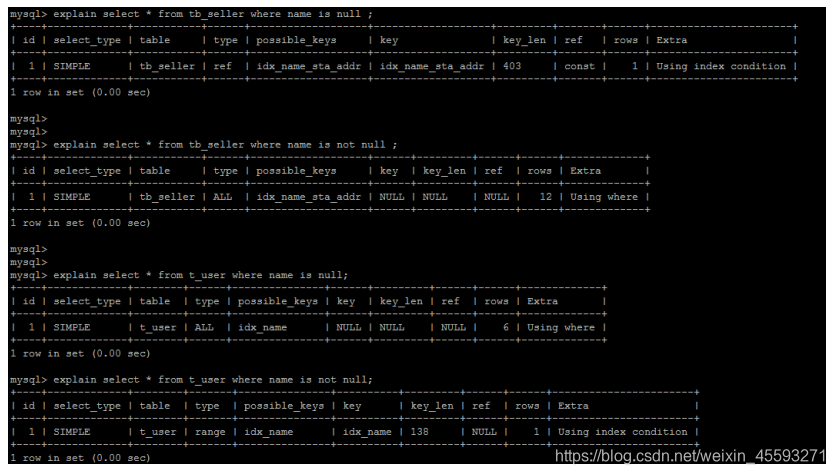
10). is NULL , is NOT NULL 有时索引失效。
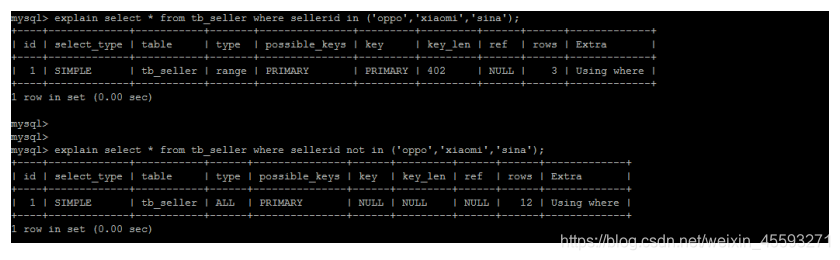
11). in 走索引, not in 索引失效。
12). 单列索引和复合索引。
尽量使用复合索引,而少使用单列索引 。
创建复合索引
create index idx_name_sta_address on tb_seller(name, status, address);
就相当于创建了三个索引 :
name
name + status
name + status + address
创建单列索引
create index idx_seller_name on tb_seller(name);
create index idx_seller_status on tb_seller(status);
create index idx_seller_address on tb_seller(address);
数据库会选择一个最优的索引(辨识度最高索引)来使用,并不会使用全部索引 。
10.查看索引使用情况
show status like 'Handler_read%';
show global status like 'Handler_read%';

Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低 越好)。 Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的 性能改善不高,因为索引不经常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列, 该值增加。 Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY … DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。 你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应 该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说 明你的表索引不正确或写入的查询没有利用索引。
11.SQL优化
大批量插入数据
环境准备 :
CREATE TABLE `tb_user_2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
`birthday` datetime DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`email` varchar(45) DEFAULT NULL,
`phone` varchar(45) DEFAULT NULL,
`qq` varchar(32) DEFAULT NULL,
`status` varchar(32) NOT NULL COMMENT '用户状态',
`create_time` datetime NOT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
当使用load 命令导入数据的时候,适当的设置可以提高导入的效率。
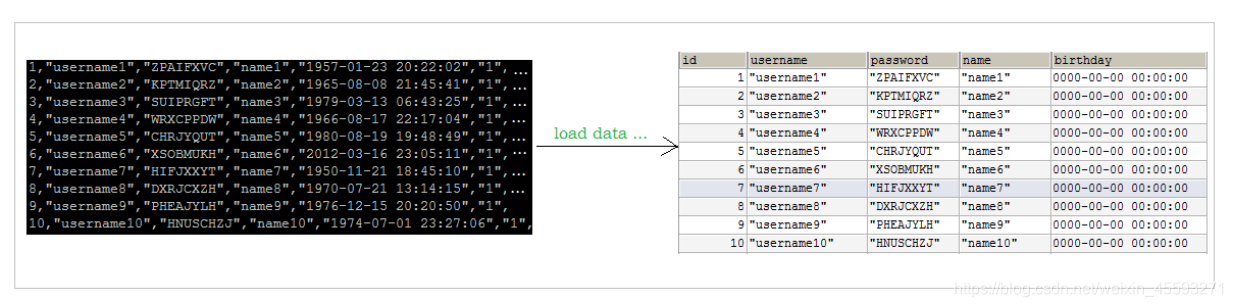
对于 InnoDB 类型的表,有以下几种方式可以提高导入的效率:
1) 主键顺序插入
因为InnoDB类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数
据的效率。如果InnoDB表没有主键,那么系统会自动默认创建一个内部列作为主键,所以如果可以给表创建一个
主键,将可以利用这点,来提高导入数据的效率。
脚本文件介绍 :
sql1.log ----> 主键有序
sql2.log ----> 主键无序
插入ID顺序排列数据:

插入ID无序排列数据:

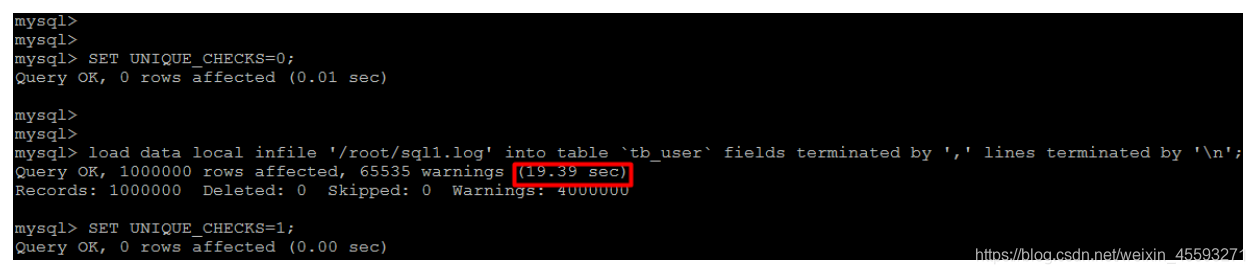
2) 关闭唯一性校验
在导入数据前执行 SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入结束后执行SET UNIQUE_CHECKS=1,恢
复唯一性校验,可以提高导入的效率。
3) 手动提交事务
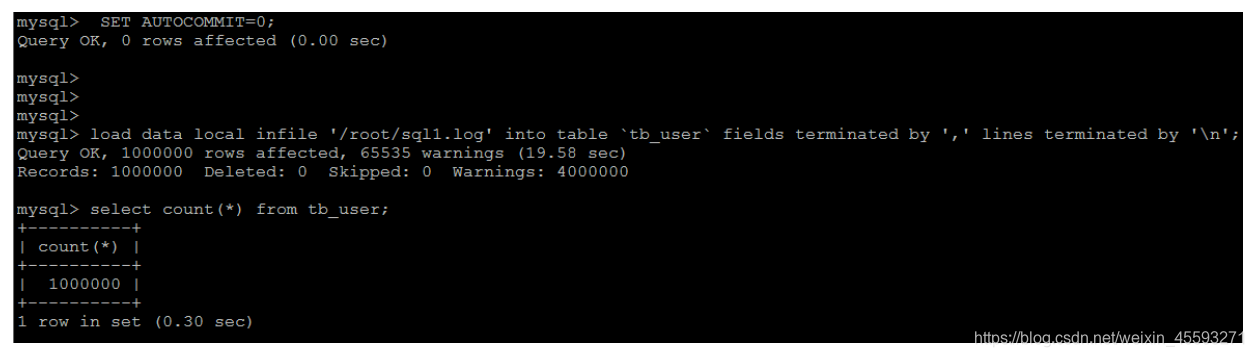
如果应用使用自动提交的方式,建议在导入前执行 SET AUTOCOMMIT=0,关闭自动提交,导入结束后再执行 SET
AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
优化insert语句
当进行数据的insert操作的时候,可以考虑采用以下几种优化方案。
如果需要同时对一张表插入很多行数据时,应该尽量使用多个值表的insert语句,这种方式将大大的缩减客户
端与数据库之间的连接、关闭等消耗。使得效率比分开执行的单个insert语句快。
示例, 原始方式为:
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
优化后的方案为 :
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
在事务中进行数据插入。
start transaction;
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
commit;
数据有序插入
insert into tb_test values(4,'Tim');
insert into tb_test values(1,'Tom');
insert into tb_test values(3,'Jerry');
insert into tb_test values(5,'Rose');
insert into tb_test values(2,'Cat');
优化后
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
insert into tb_test values(4,'Tim');
insert into tb_test values(5,'Rose');
优化order by语句
环境准备
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(3) NOT NULL,
`salary` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100');
insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');
create index idx_emp_age_salary on emp(age,salary);
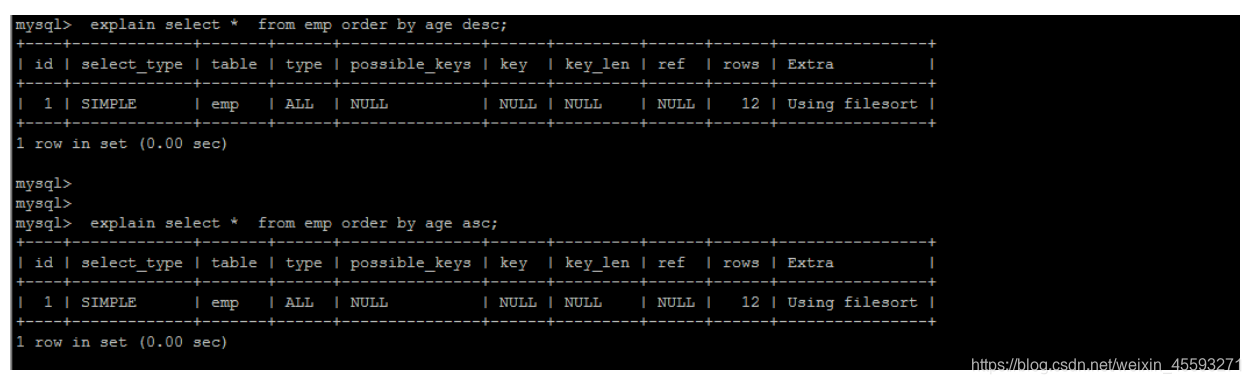
两种排序方式
1). 第一种是通过对返回数据进行排序,也就是通常说的 filesort 排序,所有不是通过索引直接返回排序结果的排序
都叫 FileSort 排序。
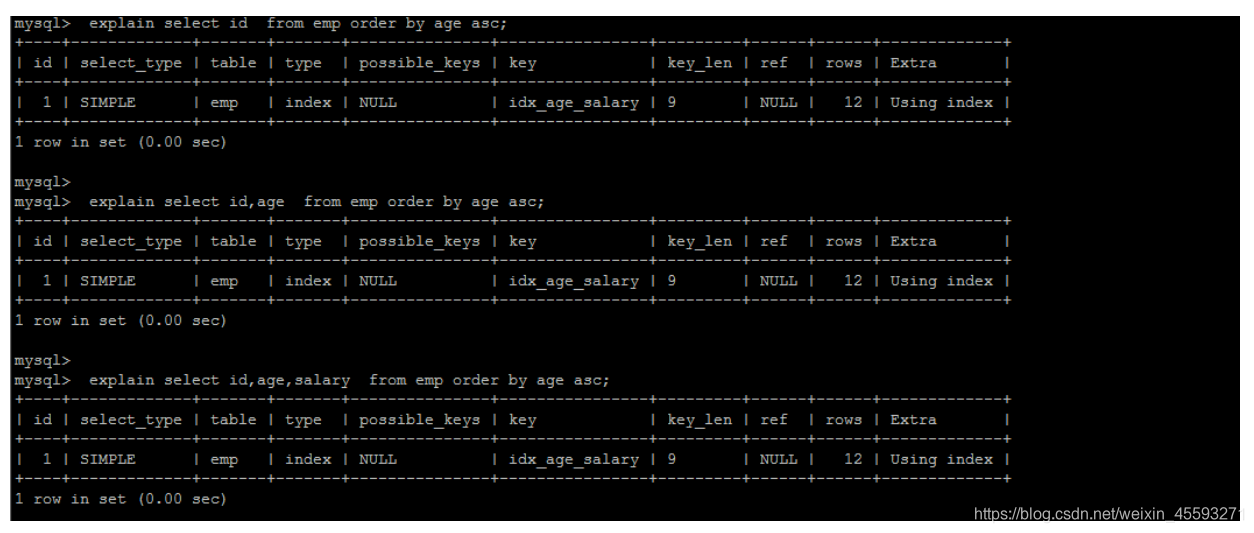
2). 第二种通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
多字段排序
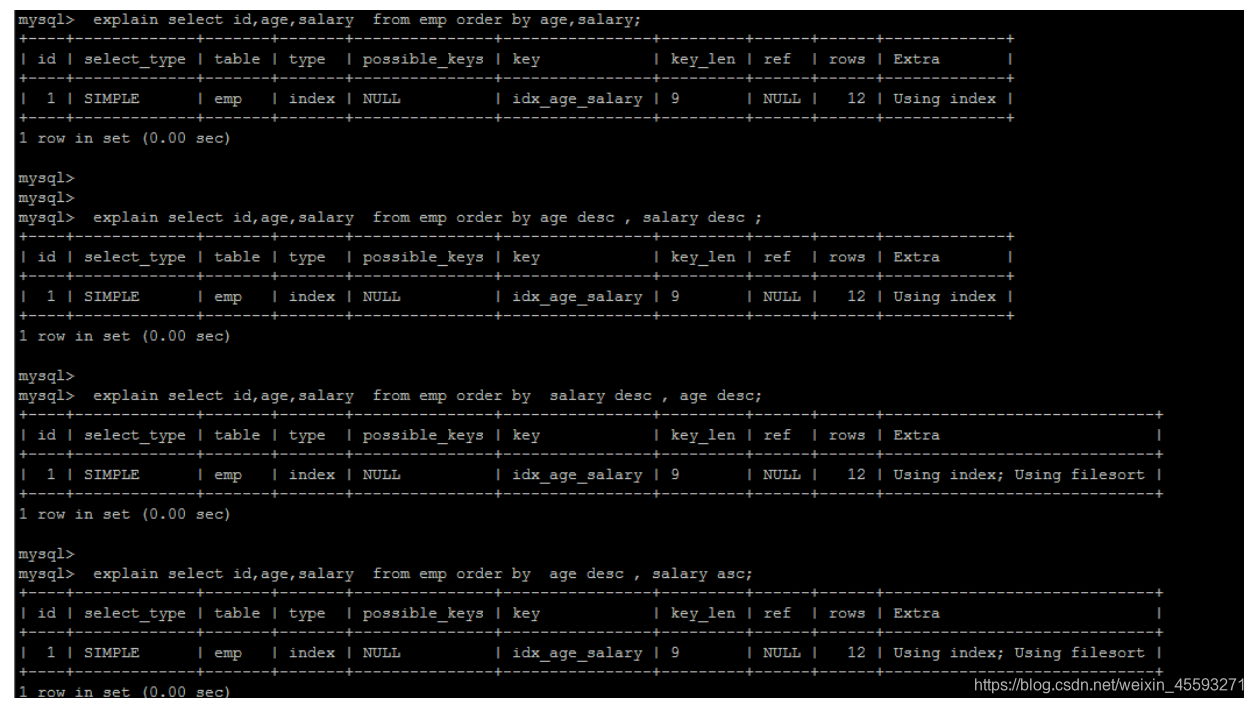
了解了MySQL的排序方式,优化目标就清晰了:尽量减少额外的排序,通过索引直接返回有序数据。where 条件
和Order by 使用相同的索引,并且Order By 的顺序和索引顺序相同, 并且Order by 的字段都是升序,或者都是
降序。否则肯定需要额外的操作,这样就会出现FileSort。
Filesort 的优化
通过创建合适的索引,能够减少 Filesort 的出现,但是在某些情况下,条件限制不能让Filesort消失,那就需要加
快 Filesort的排序操作。对于Filesort , MySQL 有两种排序算法:
1) 两次扫描算法 :MySQL4.1 之前,使用该方式排序。首先根据条件取出排序字段和行指针信息,然后在排序区
sort buffer 中排序,如果sort buffer不够,则在临时表 temporary table 中存储排序结果。完成排序之后,再根据
行指针回表读取记录,该操作可能会导致大量随机I/O操作。
2)一次扫描算法:一次性取出满足条件的所有字段,然后在排序区 sort buffer 中排序后直接输出结果集。排序时
内存开销较大,但是排序效率比两次扫描算法要高。
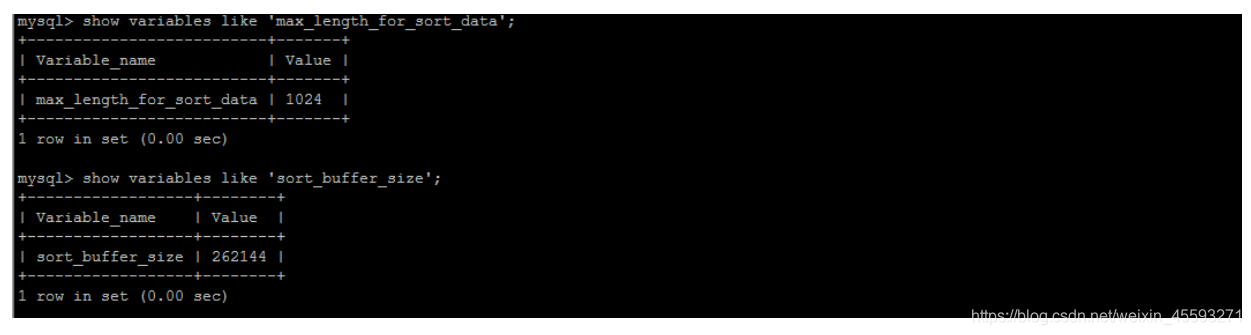
MySQL 通过比较系统变量 max_length_for_sort_data 的大小和Query语句取出的字段总大小, 来判定是否那种排
序算法,如果max_length_for_sort_data 更大,那么使用第二种优化之后的算法;否则使用第一种。
可以适当提高 sort_buffer_size 和 max_length_for_sort_data 系统变量,来增大排序区的大小,提高排序的效
率。
优化group by 语句
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分
组操作。当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算。所以,在
GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引。
如果查询包含 group by 但是用户想要避免排序结果的消耗, 则可以执行order by null 禁止排序。如下 :
drop index idx_emp_age_salary on emp;
explain select age,count(*) from emp group by age;

优化后
explain select age,count(*) from emp group by age order by null;

从上面的例子可以看出,第一个SQL语句需要进行"filesort",而第二个SQL由于order by null 不需要进行
“filesort”, 而上文提过Filesort往往非常耗费时间。
创建索引 :
create index idx_emp_age_salary on emp(age,salary);

优化嵌套查询
Mysql4.1版本之后,开始支持SQL的子查询。这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把
这个结果作为过滤条件用在另一个查询中。使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL
操作,同时也可以避免事务或者表锁死,并且写起来也很容易。但是,有些情况下,子查询是可以被更高效的连接
(JOIN)替代。
示例 ,查找有角色的所有的用户信息 :
explain select * from t_user where id in (select user_id from user_role );
执行计划为 :

优化后 :
explain select * from t_user u , user_role ur where u.id = ur.user_id;

连接(Join)查询之所以更有效率一些 ,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上需要两个步骤的
查询工作。
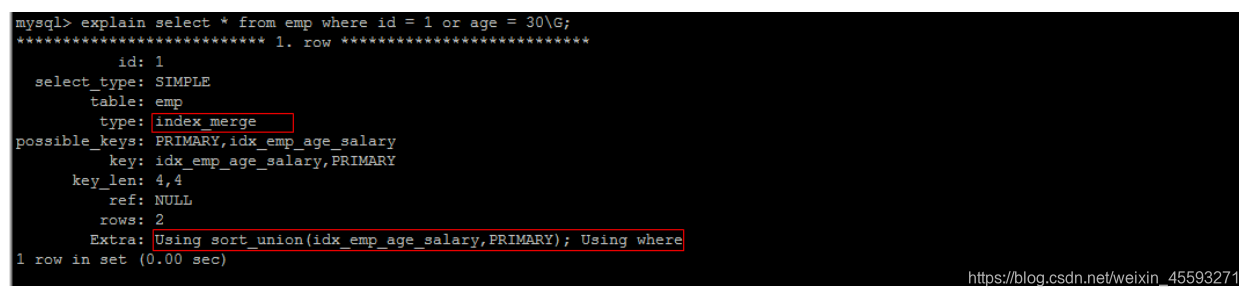
优化OR条件
对于包含OR的查询子句,如果要利用索引,则OR之间的每个条件列都必须用到索引 , 而且不能使用到复合索
引; 如果没有索引,则应该考虑增加索引。
获取 emp 表中的所有的索引 :

示例 :
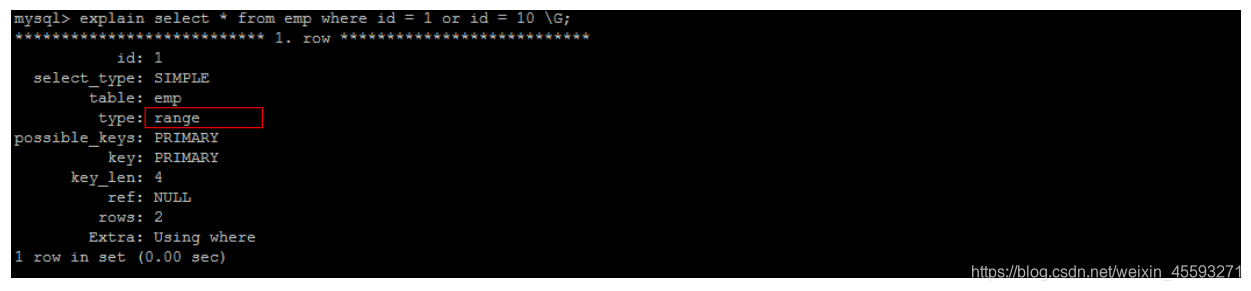
explain select * from emp where id = 1 or age = 30;
建议使用 union 替换 or :

我们来比较下重要指标,发现主要差别是 type 和 ref 这两项
type 显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >
unique_subquery > index_subquery > range > index > ALL
UNION 语句的 type 值为 ref,OR 语句的 type 值为 range,可以看到这是一个很明显的差距
UNION 语句的 ref 值为 const,OR 语句的 type 值为 null,const 表示是常量值引用,非常快
这两项的差距就说明了 UNION 要优于 OR 。
优化分页查询
一般分页查询时,通过创建覆盖索引能够比较好地提高性能。一个常见又非常头疼的问题就是 limit 2000000,10 ,
此时需要MySQL排序前2000010 记录,仅仅返回2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非
常大 。

优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容

优化思路二
该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询 。

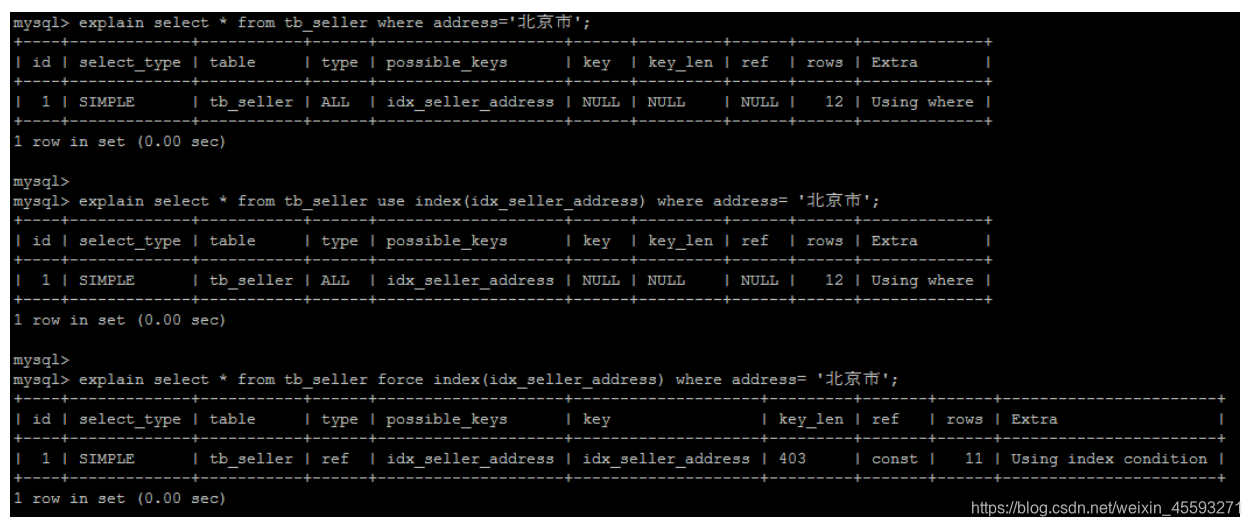
使用SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目
的。
USE INDEX
在查询语句中表名的后面,添加 use index 来提供希望MySQL去参考的索引列表,就可以让MySQL不再考虑其他
可用的索引。
create index idx_seller_name on tb_seller(name);
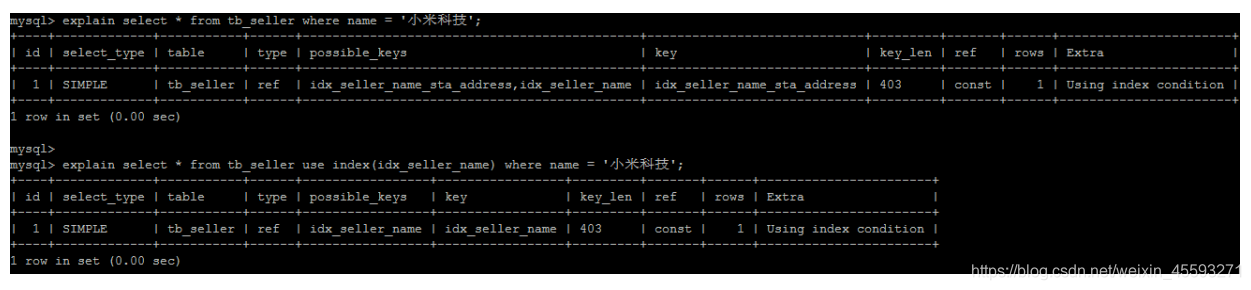
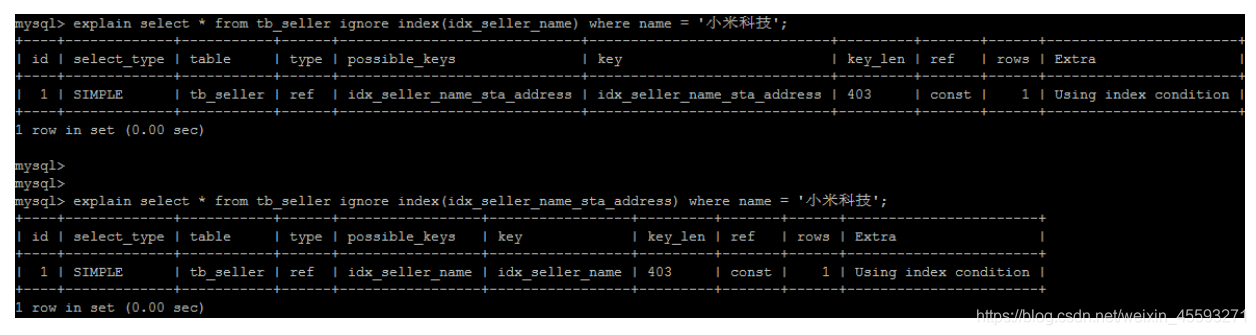
IGNORE INDEX
如果用户只是单纯的想让MySQL忽略一个或者多个索引,则可以使用 ignore index 作为 hint 。
explain select * from tb_seller ignore index(idx_seller_name) where name = '小米科 技';
FORCE INDEX
为强制MySQL使用一个特定的索引,可在查询中使用 force index 作为hint 。
create index idx_seller_address on tb_seller(address);