是否会使用索引,是mysql的关键
1.sql性能下降原因
- 查询语句写的不好,连接子查询太多,没有建索引等等
- 索引失效
- 关联Jion表过多
- 服务器参数设置不合适
2.索引优化
索引是什么?
索引就是一种排好序的查找数据结构,常见模型有哈希表、有序数组、二叉搜索树
目前最常用的innoDB引擎使用的模型是B+Tree,也就是多叉搜索树(叶子节点是指针,指向数据地址)
如何建索引(也可以用Alter)
假如表结构 id name email phonenumber
select * from user where name =‘’;
单值索引:create index idx_user_name on user(name)
select * from user where name =‘’ and email;
复合索引:create index idx_user_nameEmail on user(name,email)
唯一索引:列值唯一,可以为空
索引好处坏处
好处就是减少IO和CPU消耗
坏处就是占用空间、更新消耗增加、优化索引耗时
3.什么时候建索引
什么时候建
- 主键自动建索引,外键要建
- where经常用到的要建,where用不到的不建
- 排序、统计、分组的字段建立索引(order,group by等)
什么时候不建
- 频繁修改的列值
- 表记录太少
- 列值重复过多
4.Explain 性能分析
架构
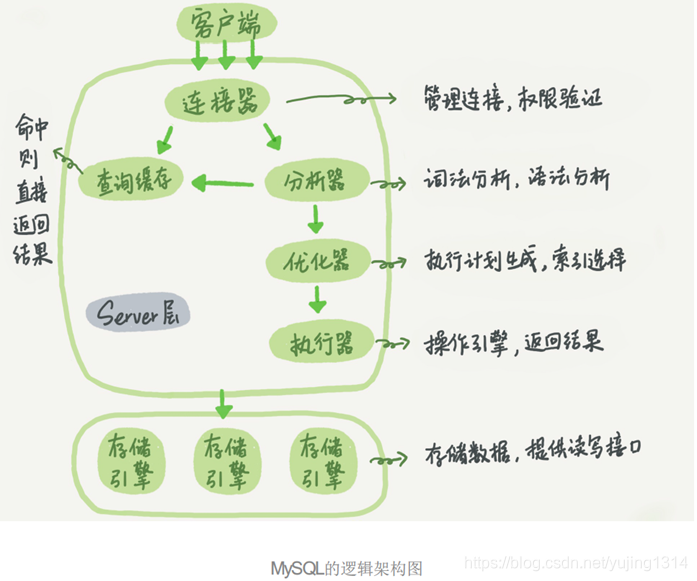
连接器:通过连接器连接数据库
查询缓存:MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句,执行过的直接缓存在内存中;如果查询命中缓存,MySQL不需要执行后面的复杂操作,就可以直接返回结果。
优化器: 跟指令重排类似,会选择最优方案
执行器:调用引擎
存储引擎:默认innoDB,还有MyISAM、MEMORY等
是什么
模拟优化器执行SQL语句,从而分析SQL
怎么做
Explain+SQL
结果如下

4.1 参数详解
id:选择标识符,可以理解为一组,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
select_type:表示查询的类型。比如SIMPLE-简单SELECT,不使用UNION或子查询等
table:输出结果集的表
type:对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。,常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度,表示索引中使用的字节数
ref:列与索引的比较,即哪些列或常量被用于查找索引列上的值
rows:扫描出的行数(估算的行数) 估算出结果集行数
Extra:执行情况的描述和说明
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
Using join buffer 使用了连接缓存
Using filesort 使用一个外部的索引排序
Using index 使用了覆盖索引
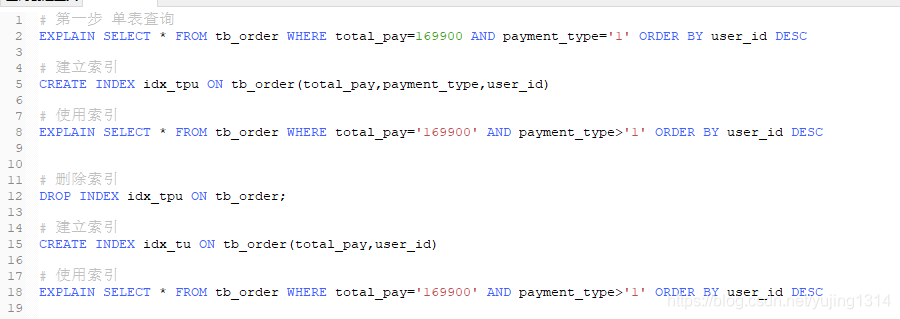
单表和多表索引优化
单表
两表
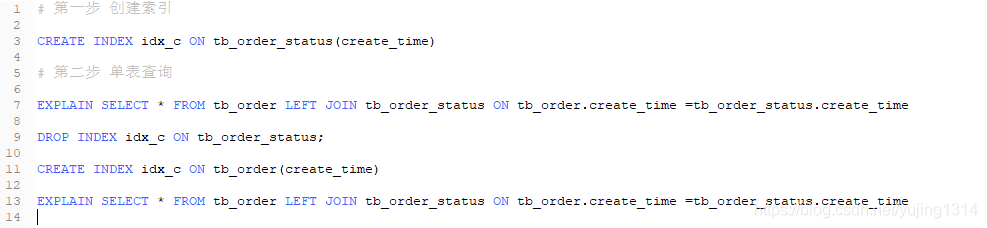
左连接的索引加到JOIN后面的表中效果更好,也就是加到右表,因为左连接条件用于如何从右表搜索行,左表都有
5.索引失效的情况
导图
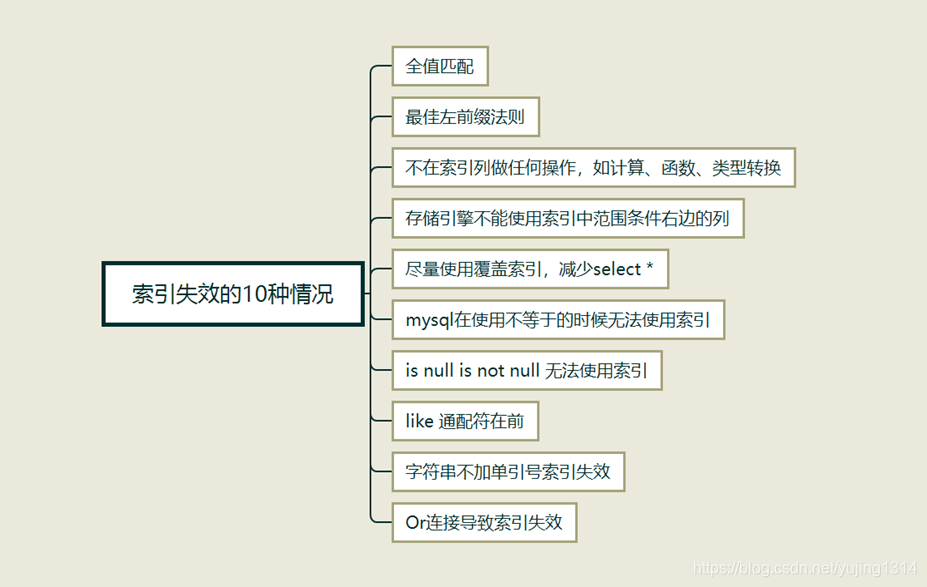
- 全值匹配:建立的复合索引中的索引全部都要用到,才是最好的
- 最佳左前缀法则:如果是复合索引,要遵守查询从索引的最左前列开始并且不跳过索引中的列
- 不在索引列做任何操作,如计算、函数、类型转换:比如left(索引)等函数
- 存储引擎不能使用索引中范围条件右边的列:从范围条件开始索引开始失效,比如id>‘10’
- 尽量使用覆盖索引,减少select *,select后面的搜索目标要准确
- mysql在使用不等于的时候无法使用索引:比如 is_null!=0
- is null is not null 无法使用索引: 比如 where id is null
- like 通配符在前,like使用通配符最好是索引在前,&索引 索引会失效
- 字符串不加单引号索引失效:会发生类型转换
- Or连接导致索引失效 :尽量少使用or