1、知道提升、梯度提升是什么意思
1.1、提升
每一步产生一个弱预测模型,并加权累加到总模型中。
1.2、梯度提升
如果每一步的预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升。

1.3、了解提升算法的过程
处理的过程:拿原始数据x,y生成一棵树(得到一个相应的函数T(xi)),得到对应的根据点预测值。之后计算原始数据和预测值的残差(残差尽可能接近于0)作为损失函数(残差是观测值与预测值之间的差),如果不等于0则将残差作为xi的“y”再生成一棵树,再得到对应的预测值Yi,再次计算”y”和预测值Y^的残差值(也就是预测值和残差值的残差值),看损失函数的值是否为0,若不为0则重复以上步骤…直到损失函数为0.(提升算法的损失函数是预测值和真实值的残差)


2、残差与残差平方和(residual sum of squares)
残差:是指观测值与预测值(拟合值)之间的差,即是实际观察值与回归估计值的差,把每个残差的平方后加起来 称为残差平方和,它表示随机误差的效应。
每一点的y值的估计值和实际值的差的平方之和称为残差平方和,而y的实际值和平均值的差的平方之和称为总平方和。
误差:即观测值与真实值的偏离;
残差:观测值与拟合值的偏离.
误差与残差,这两个概念在某程度上具有很大的相似性,都是衡量不确定性的指标,可是两者又存在区别。
误差与测量有关,误差大小可以衡量测量的准确性,误差越大则表示测量越不准确。
误差分为两类:系统误差与随机误差。其中,系统误差与测量方案有关,通过改进测量方案可以避免系统误差。随机误差与观测者,测量工具,被观测物体的性质有关,只能尽量减小,却不能避免。
残差――与预测有关,残差大小可以衡量预测的准确性。残差越大表示预测越不准确。残差与数据本身的分布特性,回归方程的选择有关。
误差大,由异常值引起.表明数据可能有严重的测量错误;或者所选模型不合适,;
残差大,表明样本不具代表性,也有可能由特征值引起.
总之要看一个模型是否合适,看误差;要看所取样本是否合适,看残差;
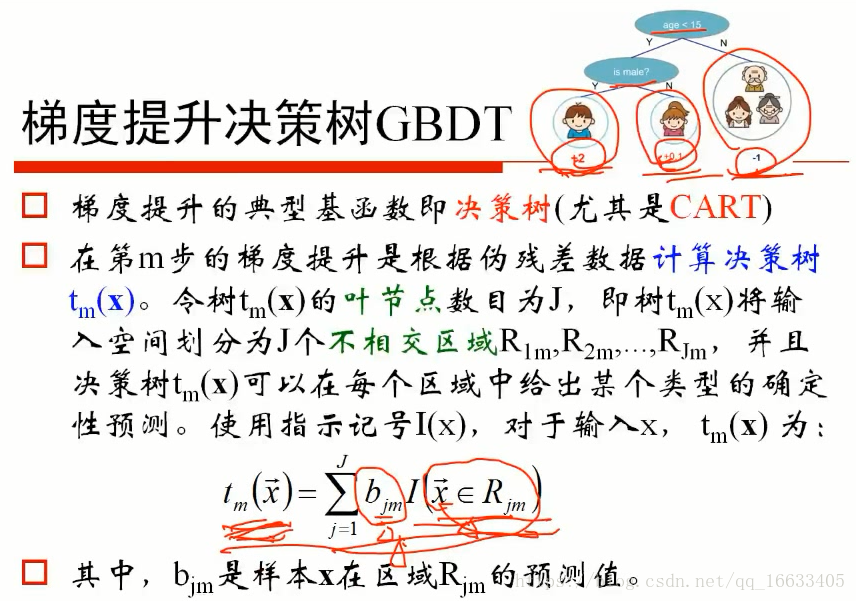
3、了解GBDT算法
了解GBDT计算决策树的公式Tm(x)也就代表决策树函数(即输入x得到预测值),其中Bjm代表的是样本X在区域Rjm的预测值(Rjm决策树的几个叶子节点),I代表的是x是否该区域(是的话为1,不是的话为0)


4、了解XGBoost算法
XGBoost算法只是将目标函数改为了二阶导信息
XGBoost生成树的过程:枚举可行的分割点(下图五个数据有4种分割),然后依次计算对应的Gain()(根节点的损失减去两个叶节点的损失得到一个增益值),选取增益最大的划分。
依次进行得到整棵树。由此也能得到对应的权值w(参考w的计算公式)。




5、了解Adaboost算法
5.1、Adaboost算法的原理
通过初始化权值得到对应的误差率,进而得到加权系数,之后利用公式不断的迭代初始权值直到目标函数达到最优。
权值是需要初始化即D

em(误差率)可以计算出来(就相当于判断预测值和实际值是否相等),知道em后就能计算出对应的Gm(x)对应的系数αm了。

由下图中的公式计算Wm+1的值(α、样本的实际值和预测值以及对应样本的权值都为已知条件),去更新数据集D1中对应的权值得到D2,之后再计算D2对应的误差率e2和对应的系数α2…依次类推直到最后。(exp,高等数学里以自然常数e为底的指数函数)

由算到的m个α系数和对应的预测值相乘相加得到最终的总分类器
f(x):基本分类器的线性组合。

αm的值是>0的(1-em>em即误差率小于0.5)

迭代过程中预测结果对权值的影响:即实际操作中当预测结果正确时,第二次迭代时对应的权值会减小,反之则会增加。
Wmi公式中的值都能得到。

5.2、例子


选取一个阈值使基本分类器G1(x)的误差率最小。









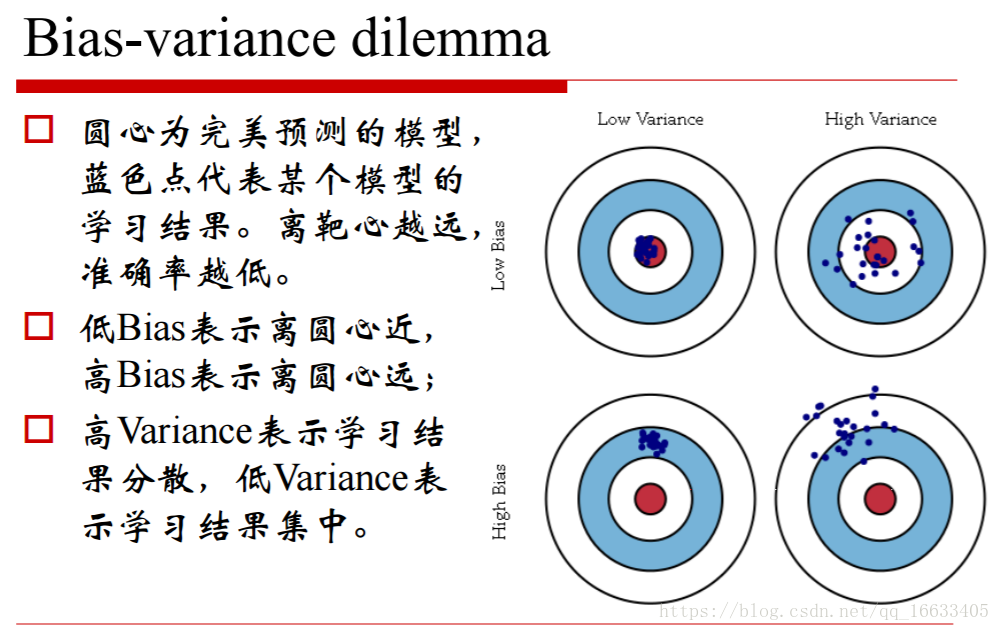
6、偏差和方差
知道偏差和方差:把偏差认为是单个模型的拟合能力,而方差则描述的是同一个学习算法在不同数据集的不稳定性
偏差与方差:
偏差描述的是算法的预测的平均值和真实值的关系(可以想象成算法的拟合能力如何),而方差描述的是同一个算法在不同数据集上的预测值和所有数据集上的平均预测值之间的关系(可以想象成算法的稳定性如何)。