今天闲着没事刷抖音,看到好多好看的小姐姐,突然想到把抖音里好看好玩的视频都下载来多方便看省的一会一个广告,一会一个推送的。
我先是用fiddler抓包工具进行了抖音app的抓包,
fiddler的使用:https://blog.csdn.net/lyd135364/article/details/78384285
分析了带有feed地址名的接口,发现这次改版后抖音的一个小bug,我今天也度娘了下以前的抖音视频爬取方式,但都在最近一次的改版中被进行文件加密了。
以前的爬取和android逆向,都是调用原getUserInfo()方法,但是更新后的抖音,这个方法所在的包都没了。原加密的as和cp参数加密直接得到结果的方法就用不成了
今天在尝试爬取的过程中,发现的小bug就是:直接在抓包的过程中,把as和cp的值写死就成了。虽然是动态获取的,但不会进行二次验证,只要说它们是由抖音自己加密组合成的数据,并且能通过后台的解签就可以了。
这次更新后,验证的方式变了。变成验证验证参数:ts,_rticket和mas。
ts为秒级时间戳,_rticket为毫秒级时间戳,mas的生成加密方式与这二者有关,与其他参数无关。(抖音后台有关于时间的验证,超过一定时间,三者作废)
判断原因是:我把as和cp参数写死不变的情况下,更改上述三个参数,依旧可以通过scrapy访问到数据,如果只更改这三者其中之一,那么无法访问到了。
现在我需要一个大手子或者逆向破解的大佬帮个忙,把这一步走过去,就能正常scrapy爬取了。
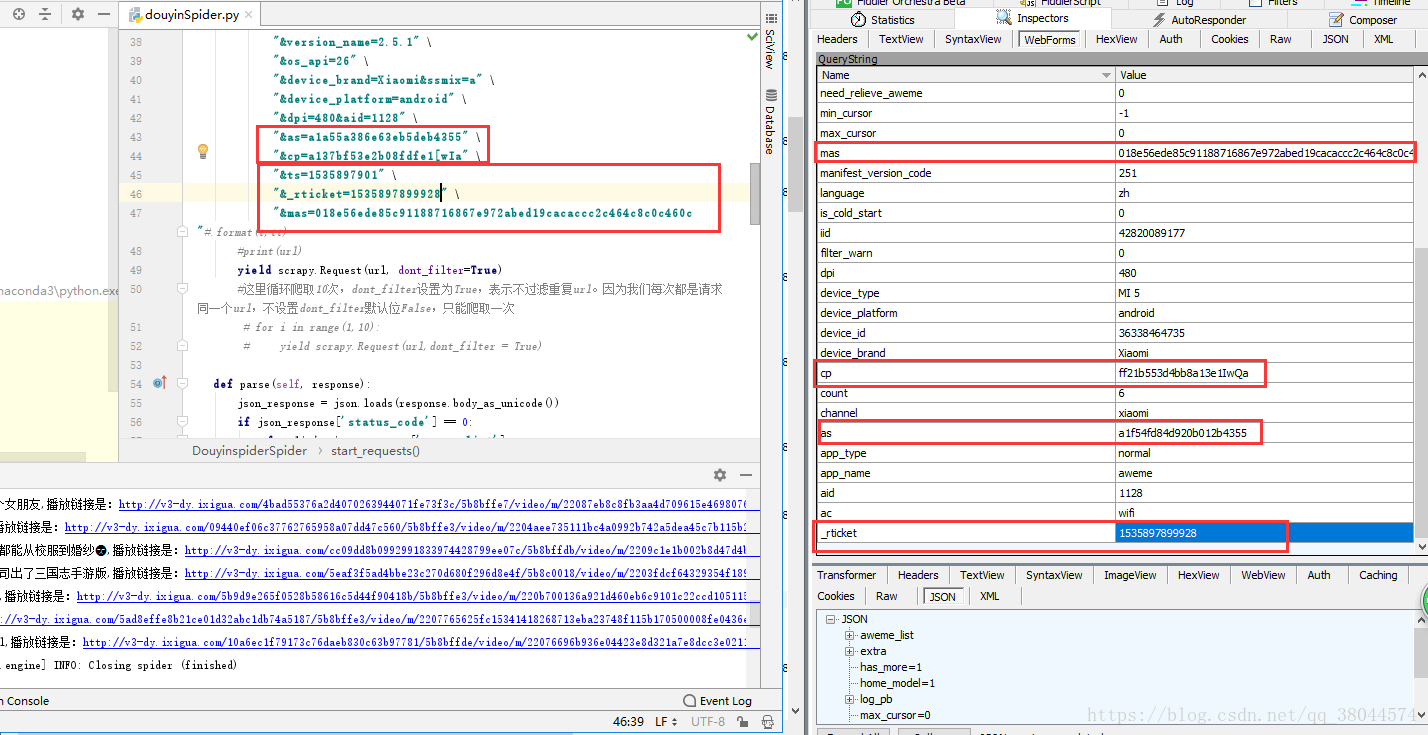
从我这个截图中可以看到。我这里的cp和as与fiddler抓包中的值是不同的,但是我依然能通过这个借口访问到,并且每次刷新访问的结果都是不同的6条。ts没有在图中截取到,只截取到了_rticket和mas的值。我自己代买中的as和cp还是我中午第一次抓包时候的值。现在已经是22:30分了。。依然能用,所以说。。我的判断没有错吧。
希望有大佬能看到能告诉我这个加密方式是什么样的,万分感谢。(这几天如果还是搞不定的话,我就只有自己动手逆向破解去了。哎。。但感觉搞不定)
如果您想联系我的话:qq.290660285 vx:lottery_cs
下面一段就是目前比较流行的获取方式了。直接复制粘贴即可使用。
如果这篇文章对你有帮助的话,是我的荣幸。
如果有错误,欢迎指正,我会以最快的速度修改的。
下面的代码,源码来自:https://www.jianshu.com/p/80e5b3c25905
我只是将原代码从2.X,升级到了3.X,并且将原有的一些小问题改掉后能正常运行。
并且对下载下来的文件做了整理和合并文件夹
其实一开始只要访问分享出来的短链接,就能获取到该用户的userid,也就是页面中
class=”focus-btn go-author” 的data-id的值。
如果想更方便更直接的下载,完全不像看到这么多的步骤,
可以尝试在下面的基础上修改,改成无头的访问方式,然后在修改流程流程就是:
1:在main方法中,输入分享出来的视频短连接
2:在run方法中,先获取NickName(昵称)和userid,然后传入到douyin_spider方法中
3:获取json数据,然后进行视频下载
很简单的操作,这里我就不修改了,动一动看官勤劳的小手,这样对这篇代码能更熟悉
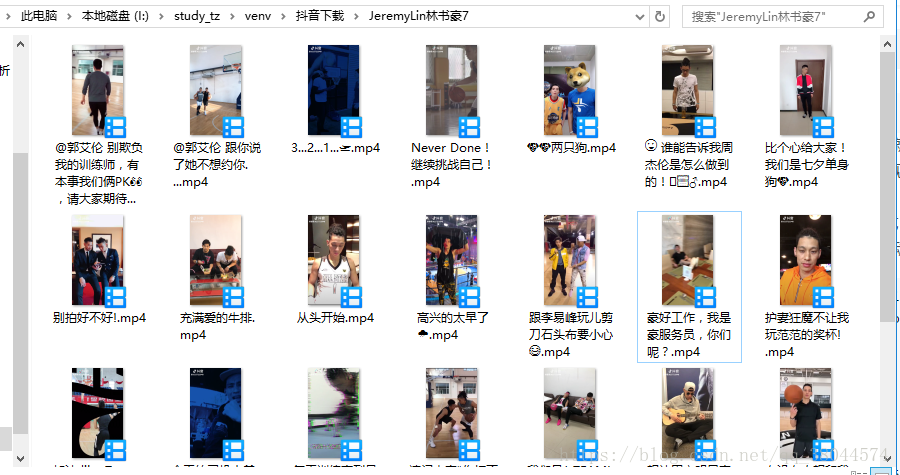
这是下载下来的截图:
from selenium import webdriver
from bs4 import BeautifulSoup
import json
import requests
import sys
import time
import os
import uuid
from contextlib import closing
class douyin_spider(object):
"""docstring for douyin_spider"""
def __init__(self, user_id, _signature, dytk):
self.Chrome_path = 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chromedriver.exe'
self.userid = user_id
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
mobile_emulation = {'deviceName': 'iPhone X'}
# chrome浏览器模拟iPhone X进行页面访问
options = webdriver.ChromeOptions()
# options = webdriver.Chrome()
options.add_experimental_option("mobileEmulation", mobile_emulation)
self.browser = webdriver.Chrome(executable_path=self.Chrome_path, chrome_options=options)
self._signature = _signature
self.dytk = dytk
self.url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=0&aid=1128&_signature=%s&dytk=%s' % (
self.userid, self._signature, self.dytk)
def handle_url(self):
url_list = [self.url, ]
self.browser.get(self.url)
web_data = self.browser.page_source
soup = BeautifulSoup(web_data, 'lxml')
web_data = soup.pre.string
web_data = json.loads(str(web_data))
# print('--------------------')
# print(web_data)
if web_data['status_code'] == 0:
while web_data['has_more'] == 1:
# 最大加载32条视频信息,has_more等于1表示还未全部加载完
max_cursor = web_data['max_cursor']
# 获取时间戳
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s' % (
self.userid, max_cursor, self._signature, self.dytk)
url_list.append(url)
self.browser.get(url)
web_data = self.browser.page_source
soup = BeautifulSoup(web_data, 'lxml')
web_data = soup.pre.string
web_data = json.loads(str(web_data))
else:
max_cursor = web_data['max_cursor']
# 获取时间戳
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s' % (
self.userid, max_cursor, self._signature, self.dytk)
url_list.append(url)
else:
url_list = []
return url_list
def get_download_url(self, url_list):
title_url = 'https://www.amemv.com/share/user/{}?u_code=hg518ec9×tamp=1535886010&utm_source=qq&utm_campaign=client_share&utm_medium=android&app=aweme&iid=42820089177'.format(self.userid)
html = requests.get(title_url)
soup = BeautifulSoup(html.text,'lxml')
nick_name = soup.find('p',{'class':'nickname'}).get_text()
download_url = []
title_list = []
if len(url_list) > 0:
for url in url_list:
self.browser.get(url)
web_data = self.browser.page_source
soup = BeautifulSoup(web_data, 'lxml')
web_data = soup.pre.string
web_data = json.loads(str(web_data))
#print('------------------')
#print(web_data)
if web_data['status_code'] == 0:
for i in range(len(web_data['aweme_list'])):
download_url.append(web_data['aweme_list'][i]['video']['play_addr']['url_list'][0])
title_list.append(web_data['aweme_list'][i]['share_info']['share_desc'])
return download_url, title_list,nick_name
else:
print('该作者目前还未上传作品')
def videodownloader(self, url, title,nick_name):
size = 0
path ='抖音下载/%s/' %nick_name +title + '.mp4'
with closing(requests.get(url, headers=self.headers, stream=True, verify=False)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
if os.path.exists(path) ==True:
print('文件:%s已经存在' %path)
else:
print
'%s is downloading...' % title
sys.stdout.write('[File Size]: %0.2f MB\n' % (content_size / chunk_size / 1024))
with open(path, 'wb') as f:
for data in response.iter_content(chunk_size=chunk_size):
f.write(data)
size += len(data)
f.flush()
sys.stdout.write('[Progress]: %0.2f%%' % float(size / content_size * 100) + '\r')
sys.stdout.flush()
else:
print
response.status_code
def run(self):
try:
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=0&aid=1128&_signature=%s&dytk=%s' % (
self.userid, self._signature, self.dytk)
url_list = self.handle_url()
download_url, title_list, nick_name = self.get_download_url(url_list)
path = '抖音下载/%s' % nick_name
result_op = os.path.exists(path)
if result_op:
for i in range(len(download_url)):
url = download_url[i]
title = title_list[i]
self.videodownloader(url, title, nick_name)
else:
print(result_op)
os.mkdir(path)
except:
print('出现错误')
finally:
self.browser.close()
if __name__ == '__main__':
# 创建对象
# 传入三个参数,user_id,_signature,dytk
#经过我运行整理后,发现只需要传入想要下载up主的userid即可,后两个参数完全不用修改,可以直接下载
#根据userid的不同,生成不同的下载用户的nickname文件夹,然后再在此文件夹下生成
#mp4文件
#userid的获取方式,见原链接
douyin_spider = douyin_spider('95870186531', 'WSMdixASAql5PsaSQZJ1MVkjHZ', '539f2c59bb57577983b3818b7a7f32ef')
douyin_spider.run()