这里以鞠婧祎的个人主页为demo
https://www.douyin.com/user/MS4wLjABAAAACV5Em110SiusElwKlIpUd-MRSi8rBYyg0NfpPrqZmykHY8wLPQ8O4pv3wPL6A-oz
【2023-11-4 23:02:52 星期六】可能后面随着XX的调整, 方法不再适用, 请注意
找到接口
找到https://www.douyin.com/aweme/v1/web/aweme/post/路劲的接口
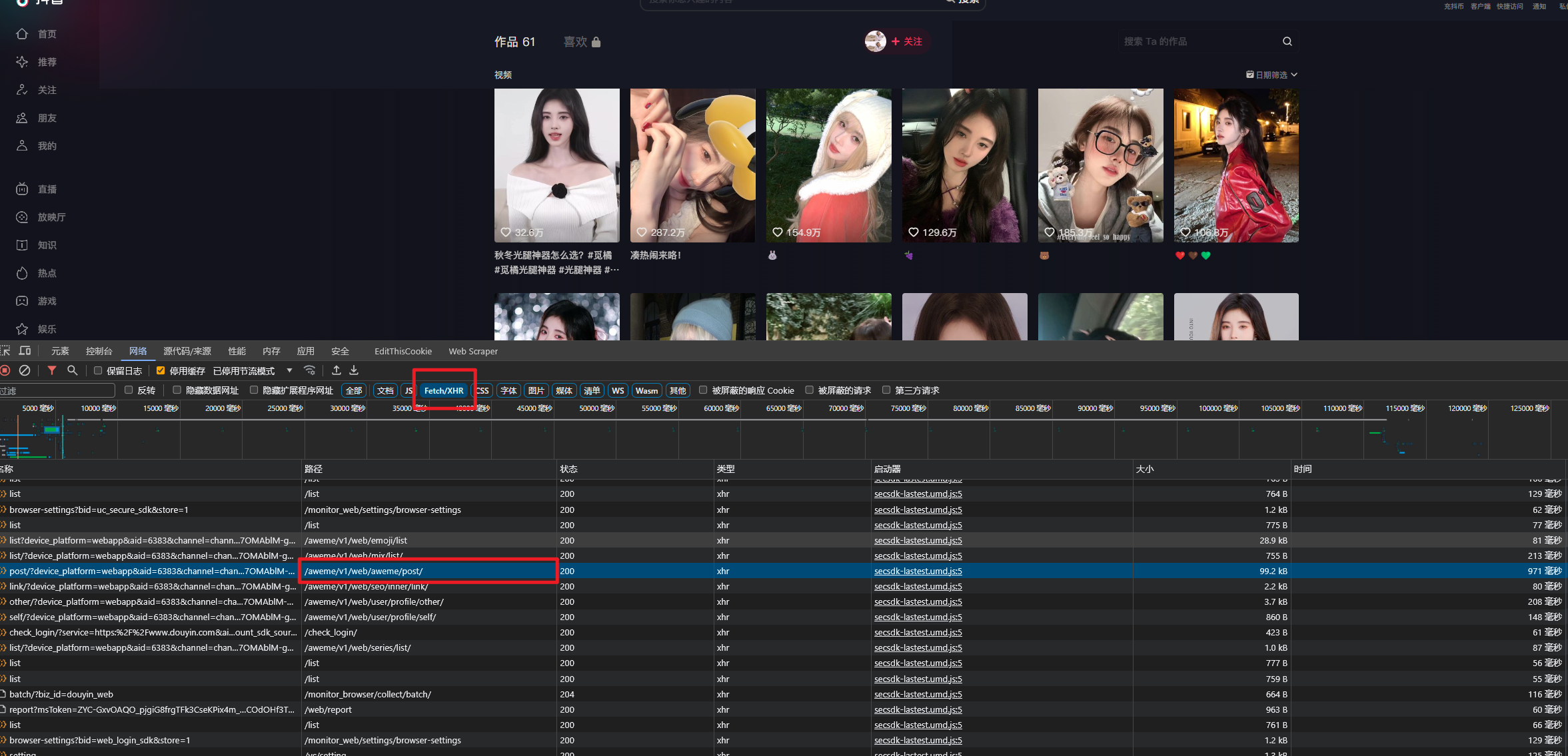
预览响应数据, 应该是能跟所发布视频的描述所对应的就OK, 但是只只有18条数据
余下的数据, 滚动进度条的时候就会出来了
接口整整37个参数, 随便改一个都会导致请求不到数据(返回状态码200, 但就是没数据), 没想到解决办法…
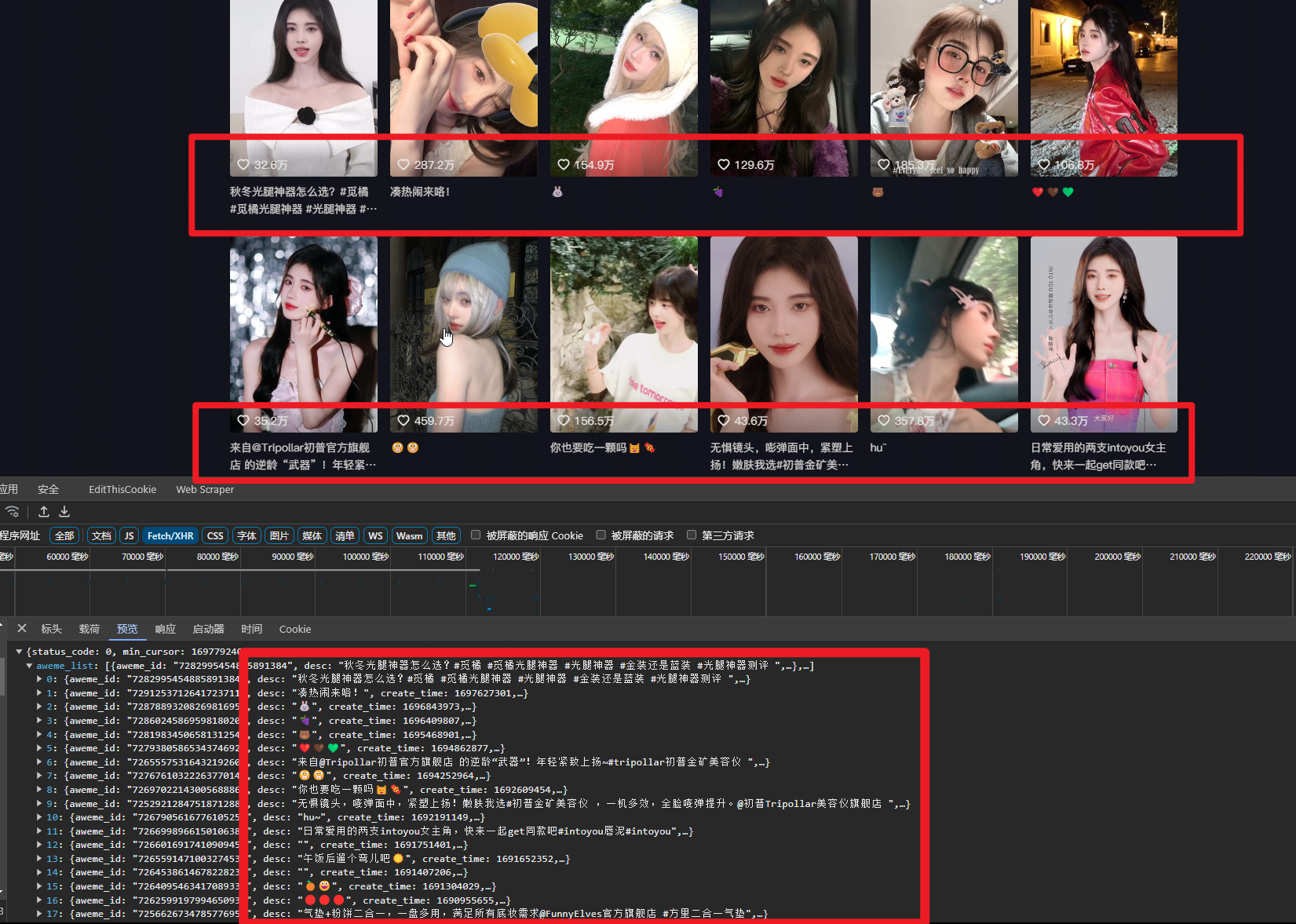
将返回的数据保存到json文件中
下载视频
import requests
import json
import os
# todo 错误处理
def download_video(url, path):
print('\n开始下载视频...', path.split('/')[-1])
r = requests.get(url, stream=True)
with open(path, 'wb') as f:
# 进度条
total_length = int(r.headers.get('content-length'))
print('视频大小:', total_length)
for chunk in r.iter_content(chunk_size=1024 * 1024):
if chunk:
f.write(chunk)
# 打印进度条
print('\r' + '[下载进度]:%s%.2f%%' % (
'>' * int((f.tell() / total_length) * 50), float(f.tell() / total_length) * 100), end='')
index = 0
# json_file, 接口返回的json文件位置
# save_file_dir, 保存视频的文件夹路径
def save_video_batch(json_file, save_file_dir):
global index
if not os.path.exists(save_file_dir):
os.makedirs(save_file_dir)
# 读取json文件
with open(json_file, 'r', encoding='utf-8') as f:
json_data = json.load(f)
aweme_list = json_data['aweme_list']
for aweme in aweme_list:
video_url_list = aweme['video']['play_addr']['url_list']
video_name = aweme['desc']
# 一个视频有三个地址, 成功一个就break
index += 1
for video_url in video_url_list:
# print(video_url)
try:
download_video(video_url, f'{
save_file_dir}{
index}-{
video_name}.mp4')
break
except Exception as e:
print('下载失败')
save_video_batch('../params/鞠婧祎主页.json', '../data/鞠婧祎主页/')
下载结果
某音反爬感觉做的很好, 好难爬…
尝试直接去获取html页面, 解析html页面, 但是获取的html页面并不是实际浏览器中浏览的页面(不是验证码界面我看了)
请求接口也是, API调试工具中能请求到, 但是使用代码就不行了, 也是返回200状态, 但是没有数据, 下面是代码, 不知道缺了什么
(有些我觉得敏感的数据, 需要自己替换)
import requests
headers = {
'authority': 'www.douyin.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'cookie': 'cookie', # 替换自己的cookie
'pragma': 'no-cache',
'referer': 'https://www.douyin.com/user/MS4wLjABAAAA0W6MrnV7YIYmneCLCypeKVoZj4VDk9amQorNZ8aIVfs',
'sec-ch-ua': '"Chromium";v="118", "Microsoft Edge";v="118", "Not=A?Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76',
}
params = (
('device_platform', 'webapp'),
('aid', '6383'),
('channel', 'channel_pc_web'),
('sec_user_id', 'MS4wLjABAAAA0W6MrnV7YIYmneCLCypeKVoZj4VDk9amQorNZ8aIVfs'),
('max_cursor', '1696500302000'),
('locate_query', 'false'),
('show_live_replay_strategy', '1'),
('need_time_list', '0'),
('time_list_query', '0'),
('whale_cut_token', ''),
('cut_version', '1'),
('count', '18'),
('publish_video_strategy_type', '2'),
('pc_client_type', '1'),
('version_code', '170400'),
('version_name', '17.4.0'),
('cookie_enabled', 'true'),
('screen_width', '1707'),
('screen_height', '1067'),
('browser_language', 'zh-CN'),
('browser_platform', 'Win32'),
('browser_name', 'Edge'),
('browser_version', '118.0.2088.76'),
('browser_online', 'true'),
('engine_name', 'Blink'),
('engine_version', '118.0.0.0'),
('os_name', 'Windows'),
('os_version', '10'),
('cpu_core_num', '16'),
('device_memory', '8'),
('platform', 'PC'),
('downlink', '10'),
('effective_type', '4g'),
('round_trip_time', '50'),
('webid', '7297499797400897065'),
('msToken', 'xxx'), # 替换token
('X-Bogus', 'xxx'), # 替换
)
response = requests.get('https://www.douyin.com/aweme/v1/web/aweme/post/', headers=headers, params=params)
# 响应200,
print(response.status_code)
# 但是没有数据
print(response.text)
现在的方法还很麻烦, 有待改进,
设想我只需要输入主页的url地址, 比如
https://www.douyin.com/user/MS4wLjABAAAACV5Em110SiusElwKlIpUd-MRSi8rBYyg0NfpPrqZmykHY8wLPQ8O4pv3wPL6A-oz, 自动下载主页中所有视频
【2023-11-7 17:02:20 星期二】
解决了哈哈哈, 看这里https://www.抖印.com/video/7298386922798468406