目录
写在前面
想来想去,还是以zookeeper开篇了,因为zookeeper目前的使用真的越来越广泛了,很多框架的使用过程中都会涉及到zookeeper,其在分布式系统中占据着举足轻重的地位。因此,在学完zookeeper之后,对于分布式系统中的一些相关原理会有一个更好的认识,再学习其他分布式框架就比较方便了。
zookeeper简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等(这段是我百度的......)。
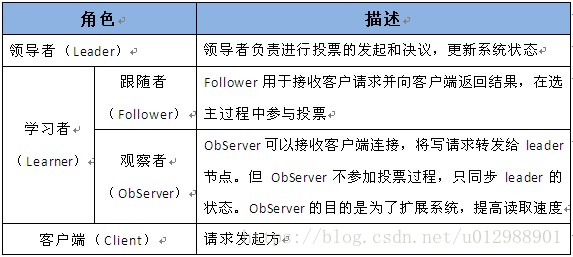
zookeeper中的角色
zookeeper的数据存储结构

zookeeper的数据存储是“树”状结构的,/ 为其根节点,有点类似于Linux的文件系统结构,znode节点可以细分为四种类型:
-
PERSISTENT-持久化节点:创建这个节点的客户端在与zookeeper服务的连接断开后,这个节点也不会被删除(除非您使用API强制删除)。
-
PERSISTENT_SEQUENTIAL-持久化顺序编号节点:当客户端请求创建这个节点A后,zookeeper会为这个节点编写一个全目录唯一的编号(这个编号只会一直增长)。当客户端与zookeeper服务的连接断开后,这个节点也不会被删除。
-
EPHEMERAL-临时znode节点:创建这个节点的客户端在与zookeeper服务的连接断开后,这个节点就会被删除。
-
EPHEMERAL_SEQUENTIAL-临时顺序编号znode节点:当客户端请求创建这个节点A后,zookeeper会这个A节点编写一个全目录唯一的编号(这个编号只会一直增长)。当创建这个节点的客户端与zookeeper服务的连接断开后,这个节点被删除
zookeeper的原理
ZooKeeper 的选举算法有两种:一种是基于 Basic Paxos(Google Chubby 采用)实现的,另外 一种是基于 Fast Paxos(ZooKeeper 采用)算法实现的。系统默认的选举算法为 Fast Paxos。 并且 ZooKeeper 在 3.4.0 版本后只保留了 FastLeaderElection 算法。
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
• 为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
• 每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
如果想深入了解Paxos算法的话,建议买本《从Paxos到Zookeeper分布式一致性原理与实践》好好学习一下哈。
zookeeper的使用场景
1 、统一命名服务
» 分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。
2 、配置管理
» 配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
» 将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到Zookeeper的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。

3、集群管理
» Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。

» 规定编号最小的为master,所以当我们对SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为master,那么master就被选出,而这个master宕机的时候,相应的znode会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为master,这样就做到动态master选举
4、协调资源抢占(分布式锁)
当分布式系统的多个节点试图同时抢占唯一资源时(例如同时写入一个文件),就需要对这个唯一资源的使用进行协调。这是ZK的“协调者”功能。
具体的使用案例
zookeeper目前已经成为Apache的顶级项目,越来越多的框架都会跟它配合使用,上面巴拉巴拉巴拉说了那么多,你可能还是感觉晕乎乎的,zookeeper到底具体能用来做什么呢?下面就举几个具体的例子,看完你就清楚了。
1、dubbo(阿里开源的一个RPC框架,目前已经捐献给Apache)可以用zookeeper作为注册中心,服务提供者将自己提供的服务信息注册到zookeeper上,服务消费者去服务提供者的信息。当提供者出现断电等异常停机时,注册中心能自动删除提供者信息,当注册中心重启时,能自动恢复注册数据,以及订阅请求。注册中心对服务提供者跟消费者是透明的,提供者、消费者可以做到动态扩容。
2、使用ZooKeeper实现的Master-Slave实现方式,是对ActiveMQ进行高可用的一种有效的解决方案,高可用的原理:使用ZooKeeper(集群)注册所有的ActiveMQ Broker。只有其中的一个Broker可以对外提供服务(也就是Master节点),其他的Broker处于待机状态,被视为Slave。如果Master因故障而不能提供服务,则利用ZooKeeper的内部选举机制会从Slave中选举出一个Broker充当Master节点,继续对外提供服务
3、SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
..........(等等还有很多哈)
下篇介绍:
下一篇会具体介绍zookeeper的单节点安装,集群的安装配置,相关配置参数的含义介绍等。