1.简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
2.搭建
1.上传zookeeper包
2.tar -zxvf 解压
3.配置环境变量
4.source或者. 重新加配置文件
5.找到zookeeper安装路径,找到conf/zoo.sample.cfg,把这个文件改名为zoo.cfg
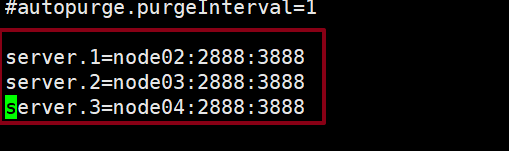
6.打开zoo.cfg,修改dataDir的路径和需要搭建zookeeper集群的节点server id

这里搭建了三台,serverid分别为1,2,3
7.把zookeeper分发给其他的节点,注意其他节点的环境变量也要配置
8.在每个节点下,找到刚刚配置的dataDir路径,在这个路径下,新建一个文件为myid,内容为server id。(例如我的dataDir为/var/hadoop/zookeeper,在node02下创建myid)


9.zkServer.sh start启动集群
3.内部运行机制
zookeeper刚刚启动时,集群处于LOOKING状态,由于没有进行任何事务的提交,会根据service id进行选取leader。如果zookeeper集群同时启动服务时,会根据server id最大的那一个作为leader。如果zookeeper集群一台一台启动时,当集群半数节点都已经起来时,会从这些已启动的节点中选取最大的server id作为leader。除了leader节点之外,其他节点时follower或者observer状态(当zookeeper集群节点很多时,当选取leader时会很难在很短的时间内得到选取结果,为了解决这个情况,会选取一部分节点作为follower,没被选上的作为observer。在zoo.cfg配置时,在节点后面加上observer。只有follower有选举和被选举的权利,observer没有选举权利)。
集群启动后,只有leader节点有增删改的权限,而follower只有查的权限。当客户端cli请求follower节点时,如果涉及增删改的请求,follower节点会向leader节点发出请求,leader接收到请求后,会把自身的zxid(事务id,根据事务,线性增长)加1,然后会进行包括leader在内的节点进行选举,如果半数以上的节点同意,leader节点会把请求以消息队列的方式分发到各个节点之上,并且接收到消息的节点会把自身的zxid增加。
集群运行一段时间后,当leader由于某种原因宕机时,集群会进入LOOKING状态,此时会在follower节点中进行选举leader,此时的选举会根据zxid和server id进行选举,首先会根据zxid最大的节点中选取server id最大的节点作为leader。
4.数据模型
zookeeper中数据模型时znode目录结构
节点间具有父子关系
层次的,目录型结构,便于管理逻辑关系
节点znode而非文件file
znode信息
包含最大1MB的数据信息
记录了Zxid等元数据信息
节点类型
Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
Znode支持序列SEQUENTIAL:leader
短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除
Znode的类型在创建时确定并且之后不能再修改
Znode有四种形式的目录节点
PERSISTENT
EPHEMERAL
PERSISTENT_SEQUENTIAL
EPHEMERAL_SEQUENTIAL
