这篇文章我试图简单易懂的做入门指导,而不是也不想过多描述定义和原理。
Zookeeper Apache 官网
Zookeeper Apache wiki
Zookeeper bird’s eye view
github-Zookeeper
一、是什么
Apache Zookeeper 原来是Hadoop 的一个子项目,它为大型分布式计算提供开源的分布式配置服务 、同步服务 和命名注册 。现在是Apache 的一个独立顶级项目。它是一个Java程序 。
Zookeeper的架构通过冗余服务实现高可用性。因此,如果第一次请求无应答,客户端就可以询问另一台Zookeeper主机。Zookeeper数据结构是一个分层的命名空间,就像一个文件系统那样。客户端可以有不同的权限对节点读写,从而以这种方式拥有一个共享的配置服务。
引用一下官网的介绍:
Zookeeper 是给分布式应用使用的一个高性能的协调服务(coordination service)。它暴漏公共服务 - 比如命名、配置管理、同步and group services - in a simple interface ,所以你可以用Zookeeper 现成的功能去实现一致性、组管理、集群领导节点选举和presence protocols 。
典型用例
Naming Service(命名服务/目录服务)
- 在分布式架构中,有很多应用都对外提供了Service 和一个与之相关的Service路径 ,且每个应用通常还可能部署了多份在不同的机器上;
- 也就是说一个Service 有多个提供者;
- 此时,调用方只要知道Service 的协议 + IP地址(域名) + 路径即可成功调用;
- 这里要说的是关于IP地址(域名)部分:
显而易见的是,如果调用方使用硬编码域名来连接Service 的话,需要将每一个提供者的地址都写上,然后采用某种策略在调用时选择其中一个提供者。这会带来如下问题:
- 如果服务提供者部署的机器要增加一台、删除一台、或仅修改域名,那么每一个调用方竟然都不得不去修改其代码才能实现切换。通常,提供者肯定会变动、调用方也肯定有很多,所以,这是灾难……
- 所以,最好的方式就是有一个协调者/中介者:
- 协调者:记录所有提供者的地址、告诉所有调用者应该使用的提供者的地址;
- 提供者:将自己的地址注册到协调者上;
- 调用者:无须再硬编码提供者地址,而只连接协调者,又协调者告诉它相关提供者的地址;自身只关心Service 路径就好了;
所以你看,此时Zookeeper 就是命名服务 :它协调了提供者 和调用者 ,提供者 在Zookeeper 上注册其名字 ,而调用者 从Zookeeper 获取提供者 的名字 ;—> 协调服务 - Coordination Service 。
要点
- 为什么叫Zookeeper?
Zookeeper wiki:协调分布式系统这个工作看起来就像动物园做的事,而动物园需要一个管理员。
- 一类动物就是一类服务器,一类动物一群就是一类服务器的多节点。
- 多类动物就是多类服务器,动物园有多类多群动物,它需要一个管理员。
二、Zookeeper实现算法
仅从上面介绍来说,其实单个Zookeeper 提供的那么简单的功能,相信你不会觉得它复杂,甚至大部分人都能轻易写出一个这样的程序来。所以:
使用Zookeeper 如果使用单点就没有意义了,如果这个Zookeeper崩溃了,难道就让所有提供者和调用者懵逼,从而使整个系统崩溃了吗?所以一定是多个Zookeeper 实例,也就是分布式Zookeeper 。
它的难点在于多个Zookeeper 的通讯,其实现的关键部分就在于如何处理分布式情况下的数据一致性;
那Zookeeper 是怎么做的呢?
Zookeeper 是以Fast Paxos 算法为基础的,我们可以了解下这个算法。(这里我先简单引用下百度百科,这个博文仅仅是要记录如何快速使用它)
引用百度百科:
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致。一个通用的一致性算法可以应用在许多场景中,是分布式计算中的重要问题。因此从20世纪80年代起对于一致性算法的研究就没有停止过。节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。Paxos 算法就是一种基于消息传递模型的一致性算法。
三、安装与配置
完整的安装向导以及参数含义在官网上有,这里只记录下我的操作过程。
下载、解压
下载地址:zookeeper-3.4.8.tar.gz# 可以直接使用wget下载,也可以在其它地方下载完拷贝过来。这里解压到了`/usr/local`下 wget http://apache.fayea.com/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz tar -zxf zookeeper-3.4.8.tar.gz修改配置文件(集群配置)
cd zookeeper-3.4.8 # 将原有的zoo_sample.cfg拷贝一份,取名叫`zoo.cfg` cp conf/zoo_sample.cfg conf/zoo.cfg # vim修改配置文件 vim conf/zoo.cfg这里是集群配置:
- 修改了
dataDir; - 集群:增加了最下边的集群配置
server.N(如果不需要集群不配置此项,不执行下面的步骤3.) - 集群:需要在集群中每台机器上都这样配置。我这里是两台机器
192.168.192.128和192.168.192.129。
// the directory where the snapshot is stored. // do not use /tmp for storage, /tmp here is just example sakes. dataDir=/usr/local/zookeeper-3.4.8/data // There are two port numbers nnnnn. // The first followers use to connect to the leader, // and the second is for leader election. server.1=192.168.192.128:2555:3555 server.2=192.168.192.129:2555:3555- 修改了
在data目录下(
zoo.cfg中的dataDir目录)新建一个叫myid的文件,文件内容对应zoo.cfg中的server.x的x:vim myid,操作的是第一台机器,server.x的x是1,所以这里文件内容是:1记得将其它机器也配置好相应的这个文件。
可选:配置JVM参数
首先,查看
<Zookeeper_Home>/bin/zkServer.sh的start方法可以看到:定义了变量$JVMFLAGS让我们设置JVM参数。其次,可以在
<Zookeeper_Home>/bin/zkEnv.sh中看到:if [ -f "$ZOOCFGDIR/java.env" ] then . "$ZOOCFGDIR/java.env" fi就是说JVM参数最好配置在
<Zookeeper_Home>/conf/java.env中。所以,我们改这里。不过这个文件不存在,先创建一个:
vim java.env,代码如下(这里我是需要改小一点):JVMFLAGS="-Xmx300M -Xms300M"可选:配置zookeeper日志输出格式、目录
首先,在
<Zookeeper_Home>/conf/log4j.properties中可以看到:log4j.rootLogger=${zookeeper.root.logger} # Add ROLLINGFILE to rootLogger to get log file output log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold} log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file} log4j.appender.ROLLINGFILE.MaxFileSize=${zookeeper.log.maxfilesize} log4j.appender.ROLLINGFILE.MaxBackupIndex=${zookeeper.log.maxbackupindex} log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n还有其它配置没有全部贴出来,这里贴出来的是可以滚动存储的日志配置,可以看到zookeeper已经给我们准备好了,我们只需要设置相关变量就可以了:
${zookeeper.root.logger}:级别 + 日志记录器${zookeeper.log.dir}/${zookeeper.log.file}:路径和日志文件名
其次,可以在
<Zookeeper_Home>/bin/zkServer.sh中看到:if [ ! -w "$ZOO_LOG_DIR" ] ; then mkdir -p "$ZOO_LOG_DIR" fi ZOO_LOG_FILE=zookeeper-$USER-server-$HOSTNAME.log _ZOO_DAEMON_OUT="$ZOO_LOG_DIR/zookeeper-$USER-server-$HOSTNAME.out" case $1 in start) echo -n "Starting zookeeper ... " if [ -f "$ZOOPIDFILE" ]; then if kill -0 `cat "$ZOOPIDFILE"` > /dev/null 2>&1; then echo $command already running as process `cat "$ZOOPIDFILE"`. exit 1 fi fi nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" \ "-Dzookeeper.log.file=${ZOO_LOG_FILE}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \ -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p' \ -cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null & …-Dzookeeper.log.dir=${ZOO_LOG_DIR}-Dzookeeper.log.file=${ZOO_LOG_FILE}这个上面那个值就行,不改了-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}
所以,我们需要给上面这2个
${***}赋值即可。还是在<Zookeeper_Home>/bin/zkEnv.sh,修改如下:if [ "x${ZOO_LOG_DIR}" = "x" ] then ZOO_LOG_DIR="$ZOOKEEPER_PREFIX/logs" // 改为自己需要的目录 ZOO_LOG_DIR="/data/logs/zookeeper" fi if [ "x${ZOO_LOG4J_PROP}" = "x" ] then ZOO_LOG4J_PROP="INFO,CONSOLE" // 改为自己需要的 ZOO_LOG4J_PROP="INFO,ROLLINGFILE" fi分别在所有机器上启动,命令如下
[root@localhost zookeeper-3.4.8]# bin/zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.8/bin/../conf/zoo.cfg Starting zookeeper ... STARTED # 以上,启动成功!当然,我们最好还是要验证一下有没有真的启动成功,使用
status
成功状态如下:[root@localhost zookeeper-3.4.8]# ./bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: leader [root@localhost zookeeper-3.4.8]# ./bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: follower如果有问题,会大概显示如下:
[root@localhost zookeeper-3.4.8]# ./bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.8/bin/../conf/zoo.cfg Error contacting service. It is probably not running.此时我们可以打开上面自己配置的日志文件,查看具体信息,并按照信息修改错误即可。
四、维护
手动清理
Zookeeper文档中说到:
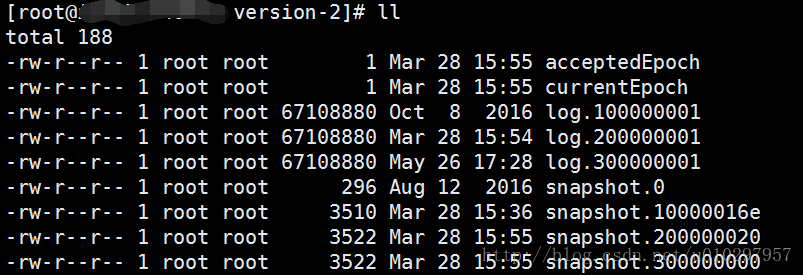
These are the snapshot and transactional log files.
…
A ZooKeeper server will not remove old snapshots and log files when using the default configuration (see autopurge below), this is the responsibility of the operator.就是说在我们配置的
dataDir=/usr/local/zookeeper-3.4.8/data目录下会生成快照文件和事务日志文件,这些文件需要我们自己负责它的清理工作;不过我们当然不是说每次需要手动的去清理这些文件……只要在上面的文档地址中,将官方提供的脚本代码按需做成
crontab定时任务即可。zkCli.sh启动脚本
./zkCli.sh -server localhost:2181后,可以直接输入help来查看支持的操作:[zk: localhost:2181(CONNECTING) 0] help ZooKeeper -server host:port cmd args stat path [watch] set path data [version] ls path [watch] delquota [-n|-b] path ls2 path [watch] setAcl path acl setquota -n|-b val path history redo cmdno printwatches on|off delete path [version] sync path listquota path rmr path get path [watch] create [-s] [-e] path data acl addauth scheme auth quit getAcl path close connect host:portzkCli.sh其实就是启动了org.apache.zookeeper.ZooKeeperMain$MyWatcher,可以自己进来看具体的实现:static { commandMap.put("connect", "host:port"); commandMap.put("close",""); commandMap.put("create", "[-s] [-e] path data acl"); commandMap.put("delete","path [version]"); commandMap.put("rmr","path"); commandMap.put("set","path data [version]"); commandMap.put("get","path [watch]"); commandMap.put("ls","path [watch]"); commandMap.put("ls2","path [watch]"); commandMap.put("getAcl","path"); commandMap.put("setAcl","path acl"); commandMap.put("stat","path [watch]"); commandMap.put("sync","path"); commandMap.put("setquota","-n|-b val path"); commandMap.put("listquota","path"); commandMap.put("delquota","[-n|-b] path"); commandMap.put("history",""); commandMap.put("redo","cmdno"); commandMap.put("printwatches", "on|off"); commandMap.put("quit",""); commandMap.put("addauth", "scheme auth"); }官方的
Getting Started中有一些具体使用zookeeperStarted;
记录一下介绍的不错的博客:
ZooKeeper原理及使用 :http://blog.csdn.net/xinguan1267/article/details/38422149
zkCli.sh使用指南:http://blog.csdn.net/ganglia/article/details/11606807?utm_source=tuicool&utm_medium=referral
这个其实是使用Dubbo的前置篇,接下来可以继续看RPC框架与Dubbo完整使用