1、概述
换了个固态硬盘,本想装最新的系统mint 19,谁知道却是个坑,NVIDIA驱动和CUDA工具老是装不上去,各种问题,折腾了几天,还是用回了原来的系统。不过,这次软件改了一下,使用了python3.5+tensorflow1.9+CUDA9.0 。
这一讲,来学学非常热门的人脸识别。首先介绍MTCNN原理,然后介绍如何利用深度卷积网络提取人脸特征,以及如何利用提取的特征进行人脸识别,最后,学习Tensorflow怎么使用上面的算法。
2、MTCNN原理
2.1、简介
人脸识别,首先得做人脸检测,也就是找到人脸在哪里,用矩形框框出位置。理想情况下,应该检测出图片中所有的人脸,不要遗漏和错检。
获得人脸的矩形框后,然后就要做人脸对齐(Face Alignment),因为原始图片中,人脸的姿态、位置可能有较大区别,为了统一处理,要把人脸“摆正”。“摆正”的方法,其实就是先找到人脸的关键点,比如眼睛、鼻子、嘴巴、脸轮廓等。根据这些关键点,使用仿射变换将人脸统一标准,尽量消除姿势不同带来的误差。
而MTCNN就是一种基于深度神经网络的人脸检测和人脸对其的方法。
MTCNN由3个神经网络构成,分别是P-Net,R-Net、O-Net。
在使用上述网络之前,要对原始图片进行预处理,先将原始图片缩放到不同尺寸,形成一个“图像金字塔”,如下图所示。


接着再对每个尺寸的图片通过神经网络计算一次。
这样做的原因是,原始图片中,人脸可能存在不同的尺寸,有个脸大,有的脸小。对于脸小的,可以在放大后的图片上检测,对于脸大的,可以在缩小后的图片上检测,这样就可以在统一的尺寸下检测人脸了。
2.2、P-Net网络结构

如上图所示,就是一个P-Net网络结构,输入是一个12*12*3的RGB图像块,该网络要判断这个12*12的图像中是否有人脸,并给出人脸框和关键点(左眼、右眼、鼻子、左嘴角、右嘴角)位置。所以,对应有三个输出,下面分别介绍,
第一个输出(face classification):判断该图像是否是人脸。输出形状为1*1*2,其实就是两个值,分别对应该图像是人脸的概率和该图像不是人脸的概率。这两个值加起来严格等于1。
第二个输出(bounding box regression):框回归,就是给出框的精确位置。输入的12*12的图像块可能不是完整的人脸框位置。比如,有时候人脸并不是正好为方形;有时候图像块可能偏左,或偏右。所以,需要输出当前框位置相对与完整的人脸框位置的偏移,这个偏移由4个变量组成。(一般图像中的框由4个数表示,分别为框左上角的横坐标、框左上角的纵坐标、框的宽度、框的高度),所以,框回归的输出值为:框左上角的横坐标的相对偏移、框左上角纵坐标的相对偏移、框的宽度的误差、框高度的误差。所以输出向量的形状为1*1*4.
第三个输出(Facial landmark localization): 这个输出就是给出人脸5个关键点的位置。分别为左眼的位置、右眼的位置、鼻子的位置、左嘴角的位置、右嘴角的位置。每个关键点由横坐标和纵坐标表示,所以输出向量的形状为1*1*10.

如上图所示,在实际计算中,通过P-Net中第一层卷积的移动,会对图像中的每一个12*12区域做一次人脸检测,得到结果如上图所示。图中框的大小不一,除了框回归的影响之外,主要的原因是图片“金字塔”中的各个尺寸都用P-Net就算过一次,所以形成的大小不同的人脸框。上面得到的结果很粗糙,还需要进一步优化,这就是R-Net网络的工作了。
2.3、R-Net网络
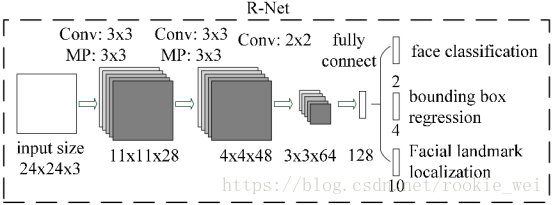
如上图所示,就是一个R-Net网络结构,输入是一个24*24*3的RGB图像块,R-Net的作用也是判断24*24*3的图像块中是否包含人脸,以及给出关键点的位置。R-Net的输出和P-Net的输出结构和含义完全一样。
在实际应用中,一般都对每个P-Net输出的可能包含人脸的区域缩放到24*24*3的大小,再输入到R-Net中。

经过R-Net优化后的结构如上图所示,消除了很多P-Net网络的误判情况。接着,将结果送给O-Net网络继续优化。
2.4、O-Net网络
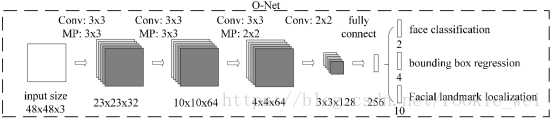
如上图所示,就是一个O-Net网络结构,输入是一个48*48*3的RGB图像块。O-Net网络的结构和P-Net网络结构依然类似,只不过输入图像块的大小不一样,而且网络通道数和层数更多了。

如上图所示,就是经过了O-Net网络后的结果。
2.5、损失定义和训练过程
由上可知,每个网络的输出都是由3个部分组成,所以损失也是由这三个部分构成。
针对判断人脸是否存在的部分,直接使用交叉熵损失。针对框回归和关键点判定部分,使用L2损失。最后由这三个部分损失各乘上自身的权重,再加起来,就形成最后的损失。
那么,如何确定各自的权重呢?P-Net和R-Net更关心框位置的准确性,所以框位置的权重就比较大,而O-Net更关心关键点的判定,所以关键点的权重就比较大。
3、提取特征
3.1、概述
经过上面的步骤后,就得到了包含人脸的区域的图像了,接下来就要进行人脸识别了。这一步一般是使用深度卷积网络,将人脸图像转成一个向量的表示,即“特征提取”。
通常在图像应用中,可以去掉最后的全连接层,使用卷基层的最后一层作为图像的“特征”。但这个方法用在人脸识别中效果并不好。
在人脸识别中,希望使用“向量表示”之间的欧几里得距离之间反应人脸的相似度。比如,
- 对于同一个人的两张图片,对应的向量之间的欧几里得距离应该比较小;
- 对于不同人的两张图片,对应的向量之间的欧几里得距离应该比较远。
上面什么意思呢?假设,人脸图像为x1,x2,对应的特征为f(x1),f(x2),则,
- x1,x2对应同一张人脸时,f(x1),f(x2)的距离 ||f(x1)-f(x2)||2 应该很小
- x1,x2对应不同一张人脸时,f(x1),f(x2)的距离 ||f(x1)-f(x2)||2 应该很大
再以CNN对MNIST分类为例,设计一个特殊的卷积网络,使得最后一层的变量为2维,可以画出每一类对应的2维向量,如下图所示。
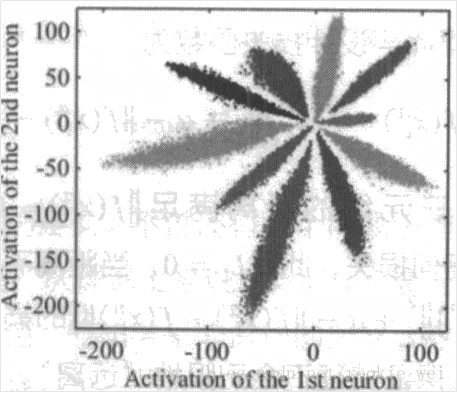
上图是直接使用Softmax训练得到的结果,它不符合我们希望的特征具有的特点(同类之间的向量距离尽可能的接近,不同类的向量距离尽可能远)。接下来我们就介绍两种方法来优化它。
3.2、三元组损失
三元组损失(Triplet Loss)的思想是,既然想让特征之间的距离具备某些性质,那么,就应围绕这个距离来设计损失。
比如,每次都在训练中取3张人脸图像,第一张图像记为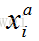
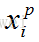

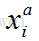
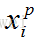

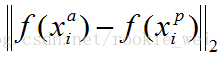

三元组损失公式如下,

损失函数为,
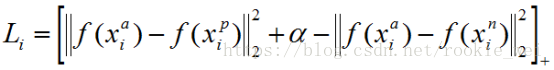
所以当三元组满足

时,不产生任何损失。当不满足上式时,就会有值为
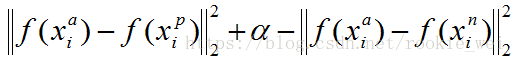
的损失。
在训练时,还会固定
三元组损失是直接对距离优化,虽然可以解决人脸特征表示问题,但是效果并不是很好。通常需要非常大的人脸数据集,才能取得较好的结果。
3.3、中心损失
中心损失不是直接对距离进行优化,而是保留了原有分类模型,但又为每个类指定一个类别中心。同一类的图像对应的特征都尽量靠近自己的类别中心,不同类的类别中心尽可能远离。
假设人脸图像为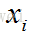

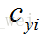


则定义中心损失为
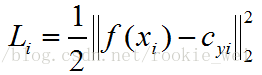
多张图像的中心损失就是它们的损失之和,

那怎么确定每个类别的中心呢?理想情况下,类别的最佳中心应该要对它对应的所有图片的特征求均值,但,这样做的话,每一次梯度下降都要对所有图片计算一次,这样的计算复杂度和计算量就异常巨大。
那怎么办呢?嘿嘿,这就又用到前面课程的思想,将“大事”化小,将数据分成多个batch,在初始阶段,先随机确定一个,然后,对每个batch使用对当前batch内的也计算梯度,并使用该梯度更新。
当然,还要加入Softmax损失,最终的损失为,
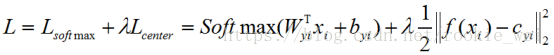
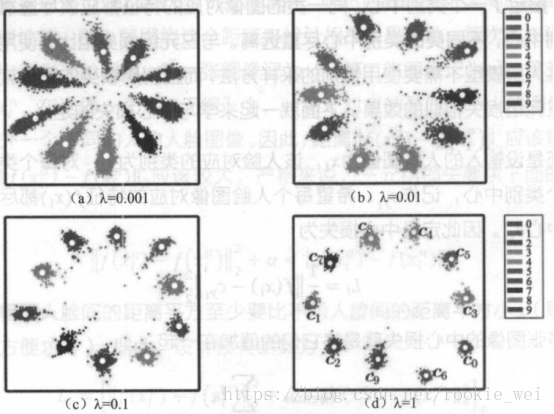
λ是一个常量,当λ去不同值时,效果如下图所示。可以看到,λ越大,越内聚。
4、应用
提取特征后,就可以使用特征做不同的应用了。一般的应用有下面几种。
- 人脸验证:验证A、B是否同一个人,只要给向量之间的距离设置一个阈值即可。这类应用蛮广泛的,门禁、人脸支付、考勤等。
- 人脸识别:输入一张图片,给出数据库中与之最相似的人脸。
- 人脸聚类:对数据库中的人脸进行聚类。
总结:
这一讲主要讲了人脸识别的一些基本原理和方法,下一讲中,我们将介绍tensorflow中怎么实现人脸识别。