tensorflow入门笔记(二十八)人脸识别(下)
-------韦访 180826
1、概述
这一讲,我们来训练自己的人脸识别模型。
2、下载CASIA-WebFace人脸数据集
CASIA-WebFace人脸数据集包含了10575个人的494414张人脸图片,需要在
网站申请,反正我没成功打开人脸数据集的申请界面,在万能的百度上找到了一个,我把它放到百度云上了,下载链接如下,有点大,4.4G,
链接: https://pan.baidu.com/s/1LOAcYEE4fV6-63WdOLy9GA 密码: 42hx
CASIA-WebFace人脸数据集的目录结构跟LFW类似,每个人对应一个文件夹,不同的是,CASIA-WebFace人脸数据集每个文件夹下都有多张同一个人脸的图片,结构如下图所示,


3、人脸检测和人脸对齐
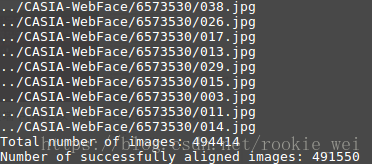
和上一讲一样,先用MTCNN对数据集进行预处理------人脸检测和人脸对齐,在facenet-master下执行命令,
python src/align/align_dataset_mtcnn.py ../CASIA-WebFace ../CASIA-WebFace_align_182 --image_size 182 --margin 44
经过N个小时的运行,总算结束了,运行结果为,
下图是预处理前的图片,

下图是预处理后的图片,

处理后的图像大小为182*182,而送入神经网络的图像大小是160*160,之所以处理后的图像大小为182*182,是为了预留一定空间给数据增强时裁剪。
4、开始训练
训练的代码是src/train_softmax.py,使用的是中心损失来训练模型,因为中心损失要用Softmax损失配合训练,所以取了这样的文件名。
执行命令,
python src/train_softmax.py --logs_base_dir ../log --models_base_dir ../models --data_dir ../CASIA-WebFace_align_182/ --model_def models.inception_resnet_v1 --image_size 160 --lfw_dir ../lfw_align_160/ --optimizer RMSPROP --learning_rate -1 --max_nrof_epochs 80 --random_crop --random_flip --learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt --weight_decay 5e-5 --center_loss_factor 1e-2 --center_loss_alfa 0.9
报错,
totalMemory: 1.95GiB freeMemory: 1.71GiB
2018-08-26 20:09:10.257341: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1423] Adding visible gpu devices: 0
2018-08-26 20:09:10.434062: I tensorflow/core/common_runtime/gpu/gpu_device.cc:911] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-08-26 20:09:10.434084: I tensorflow/core/common_runtime/gpu/gpu_device.cc:917] 0
2018-08-26 20:09:10.434089: I tensorflow/core/common_runtime/gpu/gpu_device.cc:930] 0: N
2018-08-26 20:09:10.434269: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1041] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1993 MB memory) -> physical GPU (device: 0, name: GeForce GTX 950, pci bus id: 0000:01:00.0, compute capability: 5.2)
2018-08-26 20:09:10.438385: E tensorflow/stream_executor/cuda/cuda_driver.cc:936] failed to allocate 1.95G (2090270720 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
2018-08-26 20:09:10.442601: E tensorflow/stream_executor/cuda/cuda_driver.cc:936] failed to allocate 1.75G (1881243648 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
Running training
2018-08-26 20:09:32.671532: E tensorflow/stream_executor/cuda/cuda_dnn.cc:403] could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2018-08-26 20:09:32.671592: E tensorflow/stream_executor/cuda/cuda_dnn.cc:370] could not destroy cudnn handle: CUDNN_STATUS_BAD_PARAM
2018-08-26 20:09:32.671601: F tensorflow/core/kernels/conv_ops.cc:712] Check failed: stream->parent()->GetConvolveAlgorithms( conv_parameters.ShouldIncludeWinogradNonfusedAlgo<T>(), &algorithms)
Aborted
应该又是显存不够的原因,那么,每次训练的batch调小点试试,新增参数--batch_size 1,再试试,
python src/train_softmax.py --logs_base_dir ../log --models_base_dir ../models --data_dir ../CASIA-WebFace_align_182/ --model_def models.inception_resnet_v1 --image_size 160 --lfw_dir ../lfw_align_160/ --optimizer RMSPROP --learning_rate -1 --max_nrof_epochs 80 --random_crop --random_flip --learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt --weight_decay 5e-5 --center_loss_factor 1e-2 --center_loss_alfa 0.9 --batch_size 1
还是内存溢出,为什么它每次都要分配1.95G的显存呢?看看源码还有那些参数设置了这个的?打开src/train_softmax.py,搜索memory,看到--gpu_memory_fraction参数,注释大概意思是为每个线程分配这么多的显存,这里默认值是1.0,即为每个线程分配1G的显存,显然我的破显卡是没那么大的显存的,那么,设置该参数为0.5试试。执行命令,
python src/train_softmax.py --logs_base_dir ../log --models_base_dir ../models --data_dir ../CASIA-WebFace_align_182/ --model_def models.inception_resnet_v1 --image_size 160 --lfw_dir ../lfw_align_160/ --optimizer RMSPROP --learning_rate -1 --max_nrof_epochs 80 --random_crop --random_flip --learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt --weight_decay 5e-5 --center_loss_factor 1e-2 --center_loss_alfa 0.9 --gpu_memory_fraction 0.5
还是显存溢出,那么,同时修改--batch_size的大小,将它改成1试试,运行命令,
python src/train_softmax.py --logs_base_dir ../log --models_base_dir ../models --data_dir ../CASIA-WebFace_align_182/ --model_def models.inception_resnet_v1 --image_size 160 --lfw_dir ../lfw_align_160/ --optimizer RMSPROP --learning_rate -1 --max_nrof_epochs 80 --random_crop --random_flip --learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt --weight_decay 5e-5 --center_loss_factor 1e-2 --center_loss_alfa 0.9 --batch_size 1 --gpu_memory_fraction 0.5

这下能跑起来了,说明我们的判断对了,适当的将batch_size改大一点,我试着改成20还是内存溢出,改成10就好了,所以最终的命令为,
python src/train_softmax.py --logs_base_dir ../log --models_base_dir ../models --data_dir ../CASIA-WebFace_align_182/ --model_def models.inception_resnet_v1 --image_size 160 --lfw_dir ../lfw_align_160/ --optimizer RMSPROP --learning_rate -1 --max_nrof_epochs 80 --random_crop --random_flip --learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt --weight_decay 5e-5 --center_loss_factor 1e-2 --center_loss_alfa 0.9 --batch_size 10 --gpu_memory_fraction 0.5
接下来的工作就交给机器吧。
本以为工作就这样完了,没想到运行了一下就出错了,错误打印如下,
Saving variables
Variables saved in 0.39 seconds
Saving metagraph
Metagraph saved in 2.38 seconds
Runnning forward pass on LFW images
............
Accuracy: 0.60733+-0.01493
Validation rate: 0.01900+-0.00716 @ FAR=0.00133
Saving statistics
Traceback (most recent call last):
File "src/train_softmax.py", line 581, in <module>
main(parse_arguments(sys.argv[1:]))
File "src/train_softmax.py", line 261, in main
for key, value in stat.iteritems():
AttributeError: 'dict' object has no attribute 'iteritems'
百度了一下,说python3.5将iteritems变为了items,所以将261行的iteritems改为items,再运行。
跑了一下,又内存溢出了,那还是将batch_size改为1好了。
至于其他参数的含义,看源码的注释吧。