前言:之前写了HashMap 、 ArrayList 和 LinkedList , 还差 HashTable 没有学习,这篇学习下HashTable。
PS: 源码分析针对于Android O 的jdk,即jdk1.8
参考博客: HashMap 和 HashTable 到底哪不同 ?
简单的demo:jiatai的 hashTable demo
1. HashTable简单介绍
HashTable从实现方面用的数据结构是散列表,它和HashMap差不多。友情提醒,HashTable已经过时了,现在如果非多线程场景推荐用HashMap, 多线程场景推荐用ConcurrentHashMap,虽然HashTable支持并发,但是通过加Synchronized实现的,估计是效率考虑从而过时了。
Java Collections Framework</a>. Unlike the new collection
* implementations, {@code Hashtable} is synchronized. If a
* thread-safe implementation is not needed, it is recommended to use
* {@link HashMap} in place of {@code Hashtable}. If a thread-safe
* highly-concurrent implementation is desired, then it is recommended
* to use {@link java.util.concurrent.ConcurrentHashMap} in place of
* {@code Hashtable}.
2. HashTable简单使用
写一段hashTable源码注释中提及的使用吧:package com.example.demo_28_hashtable;
import java.util.Hashtable;
public class MyClass {
public static void main(String[] args){
Hashtable<String, Integer> numbers = new Hashtable<String, Integer>();
numbers.put("one", 1);
numbers.put("two", 2);
numbers.put("three", 3);
System.out.println(numbers);
Integer n = numbers.get("two");
if (n != null) {
System.out.println("two = " + n);
}
}
}
3. HashTable 与 HahsMap 的区别
由于HashTable与hashMap很相似,并且hashTable又过时了,那本文就主要就区别介绍一下HashTable和HashMap的区别。
3.1 继承体系不同
参考博客很详细地描述了继承关系并列举了其中的public 方法,具体如下所示:
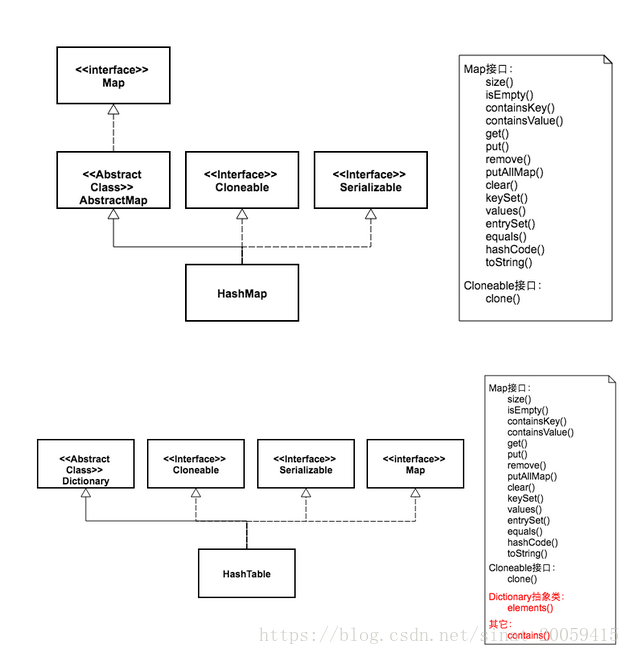
从图中可以看出,两个类的继承体系有些不同。虽然都实现了Map、Cloneable、Serializable三个接口。但是HashMap继承自抽象类AbstractMap,而HashTable继承自抽象类Dictionary,其中Dictionary类是一个已经被废弃的类。
/**
* The <code>Dictionary</code> class is the abstract parent of any
* class, such as <code>Hashtable</code>, which maps keys to values.
* Every key and every value is an object. In any one <tt>Dictionary</tt>
* object, every key is associated with at most one value. Given a
* <tt>Dictionary</tt> and a key, the associated element can be looked up.
* Any non-<code>null</code> object can be used as a key and as a value.
* <p>
* As a rule, the <code>equals</code> method should be used by
* implementations of this class to decide if two keys are the same.
* <p>
* <strong>NOTE: This class is obsolete. New implementations should
* implement the Map interface, rather than extending this class.</strong>
*
* @author unascribed
* @see java.util.Map
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.Object#hashCode()
* @see java.util.Hashtable
* @since JDK1.0
*/
public abstract
class Dictionary<K,V> {
3.2 Null key & Null Value
hashTable不支持key 或者 value 为空。看一下HashTable的put方法,代码中明显判断了值是否为空,如果为空则抛出空指针异常。key为空则通过直接调用key.hashCode()会导致空指针。
/**
* Maps the specified <code>key</code> to the specified
* <code>value</code> in this hashtable. Neither the key nor the
* value can be <code>null</code>. <p>
*
* The value can be retrieved by calling the <code>get</code> method
* with a key that is equal to the original key.
*
* @param key the hashtable key
* @param value the value
* @return the previous value of the specified key in this hashtable,
* or <code>null</code> if it did not have one
* @exception NullPointerException if the key or value is
* <code>null</code>
* @see Object#equals(Object)
* @see #get(Object)
*/
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
HashtableEntry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
HashtableEntry<K,V> entry = (HashtableEntry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
HashMap则支持空的键或值,也顺带看一下HashMap的put方法。
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
从hash方法可以看出两点
- hashMap支持key为null,并且会将其hash值计算为0。
- hashMap不是直接使用key的hash值作为分布元素依据的,而是会加上一步异或操作。
而value值是没有像HashTable一样直接判断是不是空。可以理解为没有限制。
3.3 默认初始容量大小不同
HashTable默认是11
/**
* Constructs a new, empty hashtable with a default initial capacity (11)
* and load factor (0.75).
*/
public Hashtable() {
this(11, 0.75f);
}
而HashMap默认是16
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
3.4 哈希函数
我们要在hash表中新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。
HashTable:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
HashMap:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
i = (n - 1) & hash
3.5 扩容
HashTable:
int newCapacity = (oldCapacity << 1) + 1;
HashMap:
newThr = oldThr << 1; // double threshold
3.6 线程安全
可以观察到hashTable几乎所有方法都加了synchronized关键字,由此得知hashTable是支持并发的,而hashMap是不支持并发的。最开始也讲了,如果非多线程场景推荐用HashMap, 多线程场景推荐用ConcurrentHashMap,虽然HashTable支持并发,但是通过加Synchronized实现的,估计是效率考虑从而过时了。
比如HashTable下面的size()方法前面就加了synchronized关键字
/**
* Returns the number of keys in this hashtable.
*
* @return the number of keys in this hashtable.
*/
public synchronized int size() {
return count;
}
3.7 散列冲突时链表处理方法
HashTable:是将新添的元素放在链表的head位置
private void addEntry(int hash, K key, V value, int index) {
modCount++;
HashtableEntry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
HashtableEntry<K,V> e = (HashtableEntry<K,V>) tab[index];
tab[index] = new HashtableEntry<>(hash, key, value, e);
count++;
}
HashMap:是将元素放在链表的尾巴上的
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
4. 总结
HashTable已经过时了,现在如果非多线程场景推荐用HashMap, 多线程场景推荐用ConcurrentHashMap。HashTable如果不是兼容老版本的需要,应该是没有必要再次使用了。