开篇
这篇是基于k-nrm改进的一篇论文提出的方法。同样的作者,前后隔了一年左右的时间。前面讲k-nrm的博客我没有放出代码,这一篇我会放出一个详细的模型解读源码以供大家参考。
Conv-knrm
Conv-knrm相比k-nrm,最大的改变就是它添加了n-gram的卷积,增加了原先模型的层次,这里有一个好处就是它能够捕捉更加细微的语义实体,交叉的粒度也更加细。这边我放上它完整的模型图,如果大家想更加细致的了解它的原理,建议阅读它的原始论文Convolutional Neural Networks for Soft-Matching N-Grams in Ad-hoc Search。下面我简单的讲一下整体的模型。
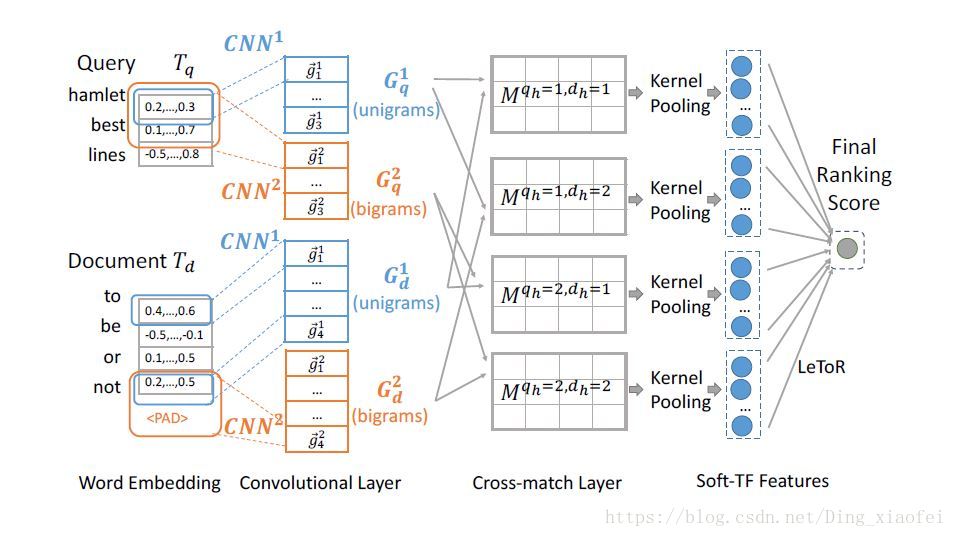
word embedding
首先还是embedding层,之前的博客已经讲过,就是把我们的句子转换成我们词向量组合的一个矩阵,这样就基本形成了我们的图,编程的时候要注意的是,我们期待卷积的张量是三维了,是带有通道数,原始的输入是要扩展维度的。这点在tensorflow里面尤其要注意。
query = Input(name='query', shape=(text1_maxlen,))
doc = Input(name='doc', shape=(text2_maxlen,))
embedding = Embedding(vocab_size, embed_size, weights=[embed],
trainable=True)
##这里的embed是预训练好的词向量
q_embed = embedding(query)
d_embed = embedding(doc)Convolutional Layer
就是单纯的卷积层,图中所示的是1-gram,2-gram大小的两种卷积核。
q_convs = []
d_convs = []
for i in range(max_ngram):
c = keras.layers.Conv1D(num_filters, i + 1, activation='relu', padding='same')
q_convs.append(c(q_embed))
d_convs.append(c(d_embed))这里使用的卷积和tensorflow不一样,它是把词向量的维度当做通道数的,所以使用的卷积是1d的。
Cross-match Layer
这里搞了一波交叉组合矩阵,计算公式依旧是cos。
for qi in range(max_ngram):
for di in range(max_ngram):
# if not corssmatch, then do not match n-gram with different length
if not if_crossmatch and qi != di:
print("non cross")
continue
q_ngram = q_convs[qi]
d_ngram = d_convs[di]
mm = Dot(axes=[2, 2], normalize=True)([q_ngram, d_ngram])kernel pooling
这个在之前的博客里面详细的解释过,包括它公式,这里不多赘述,我们代码里面见。
def Kernel_layer(mu, sigma):
def kernel(x):
return K.tf.exp(-0.5 * (x - mu) * (x - mu) / sigma / sigma)
return Activation(kernel) for qi in range(max_ngram):
for di in range(max_ngram):
# if not corssmatch, then do not match n-gram with different length
if not if_crossmatch and qi != di:
print("non cross")
continue
q_ngram = q_convs[qi]
d_ngram = d_convs[di]
mm = Dot(axes=[2, 2], normalize=True)([q_ngram, d_ngram])
for i in range(kernel_num):
mu = 1. / (kernel_num - 1) + (2. * i) / (kernel_num - 1) - 1.0
sigma = sigma
if mu > 1.0:
sigma = exact_sigma
mu = 1.0
mm_exp = Kernel_layer(mu, sigma)(mm)
mm_doc_sum = Lambda(lambda x: K.tf.reduce_sum(x, 2))(mm_exp)
mm_log = Activation(K.tf.log1p)(mm_doc_sum)
mm_sum = Lambda(lambda x: K.tf.reduce_sum(x, 1))(mm_log)
KM.append(mm_sum)
Phi = Lambda(lambda x: K.tf.stack(x, 1))(KM)完美匹配了前面那篇博客里面的公式。
全连接层
out_ = Dense(2, activation='softmax',
kernel_initializer=initializers.RandomUniform(minval=-0.014, maxval=0.014),
bias_initializer='zeros')(Phi)
model = Model(inputs=[query, doc], outputs=[out_])
return model数据预处理的代码
data_dir = "C:\\Users\\d84105613\\PycharmProjects\\Ai_qa\\data"
data_path = os.path.join(data_dir, "corpus.utf8")
print(data_path)
LTP_DATA_DIR = 'C:\\Users\\d84105613\\ltp_data'
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model')
segmentor = Segmentor() # 初始化实例
segmentor.load_with_lexicon(cws_model_path, os.path.join(data_dir,'wordDictupper.txt')) # 加载模型
def word_cut(sentence):
words = segmentor.segment(sentence)
#segmentor.release()
words = list(words)
#print(len(set(words)))
key = [",","?","[","]"]
words = [c for c in words if c not in punctuation]
words = [c for c in words if c not in key]
return words
def loadWord2Vec(filename):
vocab = []
embd = []
cnt = 0
fr = open(filename,'r',encoding='utf-8')
line = fr.readline().strip()
#print line
word_dim = int(line.split(' ')[1])
vocab.append("unk")
#print(word_dim)
embd.append([0]*word_dim)
for line in fr:
row = line.strip().split(' ')
vocab.append(row[0])
embd.append(row[1:])
print("loaded word2vec")
embd = np.asarray(embd).astype(np.float)
fr.close()
return vocab, embd
def padding_sentence(s1, s2):
#
# 得到句子s1,s2以后,很直观地想法就是先找出数据集中的最大句子长度,
# 然后用<unk>对句子进行填充
#
# s1_length_max = max([len(s) for s in s1])
# s2_length_max = max([len(s) for s in s2])
# sentence_length = max(s1_length_max, s2_length_max)
sentence_length = 20
sentence_num = s1.shape[0]
s1_padding = np.zeros([sentence_num, sentence_length], dtype=int)
s2_padding = np.zeros([sentence_num, sentence_length], dtype=int)
for i, s in enumerate(s1):
if len(s) <=20:
s1_padding[i][:len(s)] = s
else:
s1_padding[i][:] = s[:20]
for i, s in enumerate(s2):
if len(s) <=20:
s2_padding[i][:len(s)] = s
else:
s2_padding[i][:] = s[:20]
print("句子填充完毕")
return s1_padding, s2_padding
def get_id(word):
if word in sr_word2id:
return sr_word2id[word]
else:
return sr_word2id['unk']
def seq2id(seq):
#seq = clean_str(seq)
seq_split = word_cut(seq)
seq_id = list(map(get_id, seq_split))
return seq_id
def read_data_sets(train_dir):
#
# s1代表数据集的句子1
# s2代表数据集的句子2
# score代表相似度
# sample_num代表数据总共有多少行
#
# df_sick = pd.read_csv(train_dir, sep="\t", usecols=[1,2,4], names=['s1', 's2', 'score'],
# dtype={'s1':object, 's2':object, 'score':object})
# df_sick = df_sick.drop([0])
# s1 = df_sick.s1.values
# s2 = df_sick.s2.values
# score = np.asarray(map(float, df_sick.score.values), dtype=np.float32)
# sample_num = len(score)
s1 = []
s2 = []
label = []
for line in open(train_dir, encoding='utf-8'):
l = line.strip().split("¥")
if len(l) < 2:
continue
s1.append(l[0])
s2.append(l[1])
label.append(int(l[2]))
sample_num = len(label)
# 引入embedding矩阵和字典
label = [[0,1] if i == 1 else [1,0] for i in label]
global sr_word2id, word_embedding
sr_word2id, word_embedding = build_w2v_dic()
s1 = np.asarray(list(map(seq2id, s1)))
s2 = np.asarray(list(map(seq2id, s2)))
label = np.asarray(label)
#填充句子
s1, s2 = padding_sentence(s1, s2)
new_index = np.random.permutation(sample_num)
s1 = s1[new_index]
s2 = s2[new_index]
label = label[new_index]
return s1 ,s2, label
def build_w2v_dic():
# 从文件中读取 pre-trained 的 glove 文件,对应每个词的词向量
# 需要手动对glove文件处理,在第一行加上
# 400000 50
# 其中400000代表共有四十万个词,每个词50维,中间为一个空格或者tab键
# 因为word2vec提取需要这样的格式,详细代码可以点进load函数查看
w2v_path = os.path.join(data_dir, 'Word2VecModel_small.vector')
vocab, word_embedding = loadWord2Vec(w2v_path)
sr_word2id = pd.Series(range(0, len(vocab)), index=vocab)
word_mean = np.mean(word_embedding[1:], axis=0)
word_embedding[0] = word_mean
return sr_word2id, word_embedding
完整代码
#coding=utf-8
import os
import numpy as np
from pyltp import Segmentor
from zhon.hanzi import punctuation
import pandas as pd
import tensorflow as tf
import keras
from keras import losses
from keras import optimizers
import keras.backend as K
from keras.models import Sequential, Model
from keras.layers import *
from keras.layers import Input, Embedding, Dense, Activation, Lambda, Dot
from keras.activations import softmax
from keras.initializers import Constant, RandomNormal
data_dir = "C:\\Users\\d84105613\\PycharmProjects\\Ai_qa\\data"
data_path = os.path.join(data_dir, "corpus.utf8")
print(data_path)
LTP_DATA_DIR = 'C:\\Users\\d84105613\\ltp_data'
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model')
segmentor = Segmentor() # 初始化实例
segmentor.load_with_lexicon(cws_model_path, os.path.join(data_dir,'wordDictupper.txt')) # 加载模型
def build(embed):
text1_maxlen = 20
text2_maxlen = 20
vocab_size = 8035
embed_size = 300
max_ngram = 3
num_filters = 128
if_crossmatch = True
kernel_num =11
sigma = 0.1
exact_sigma = 0.01
##kernel pooling
def Kernel_layer(mu, sigma):
def kernel(x):
return K.tf.exp(-0.5 * (x - mu) * (x - mu) / sigma / sigma)
return Activation(kernel)
query = Input(name='query', shape=(text1_maxlen,))
doc = Input(name='doc', shape=(text2_maxlen,))
embedding = Embedding(vocab_size, embed_size, weights=[embed],
trainable=True)
q_embed = embedding(query)
d_embed = embedding(doc)
convs = []
q_convs = []
d_convs = []
for i in range(max_ngram):
c = keras.layers.Conv1D(num_filters, i + 1, activation='relu', padding='same')
q_convs.append(c(q_embed))
d_convs.append(c(d_embed))
KM = []
for qi in range(max_ngram):
for di in range(max_ngram):
# if not corssmatch, then do not match n-gram with different length
if not if_crossmatch and qi != di:
print("non cross")
continue
q_ngram = q_convs[qi]
d_ngram = d_convs[di]
mm = Dot(axes=[2, 2], normalize=True)([q_ngram, d_ngram])
for i in range(kernel_num):
mu = 1. / (kernel_num - 1) + (2. * i) / (kernel_num - 1) - 1.0
sigma = sigma
if mu > 1.0:
sigma = exact_sigma
mu = 1.0
mm_exp = Kernel_layer(mu, sigma)(mm)
mm_doc_sum = Lambda(lambda x: K.tf.reduce_sum(x, 2))(mm_exp)
mm_log = Activation(K.tf.log1p)(mm_doc_sum)
mm_sum = Lambda(lambda x: K.tf.reduce_sum(x, 1))(mm_log)
KM.append(mm_sum)
Phi = Lambda(lambda x: K.tf.stack(x, 1))(KM)
out_ = Dense(2, activation='softmax',
kernel_initializer=initializers.RandomUniform(minval=-0.014, maxval=0.014),
bias_initializer='zeros')(Phi)
model = Model(inputs=[query, doc], outputs=[out_])
return model
def word_cut(sentence):
words = segmentor.segment(sentence)
words = list(words)
key = [",","?","[","]"]
words = [c for c in words if c not in punctuation]
words = [c for c in words if c not in key]
return words
def loadWord2Vec(filename):
'''
读取预训练的词向量
:param filename:
:return: 词典和词向量矩阵
'''
vocab = []
embd = []
cnt = 0
fr = open(filename,'r',encoding='utf-8')
line = fr.readline().strip()
word_dim = int(line.split(' ')[1])
vocab.append("unk")
embd.append([0]*word_dim)
for line in fr:
row = line.strip().split(' ')
vocab.append(row[0])
embd.append(row[1:])
print("loaded word2vec")
embd = np.asarray(embd).astype(np.float)
fr.close()
return vocab, embd
def padding_sentence(s1, s2):
# 得到句子s1,s2以后,很直观地想法就是先找出数据集中的最大句子长度,
# 然后用<unk>对句子进行填充
# s1_length_max = max([len(s) for s in s1])
# s2_length_max = max([len(s) for s in s2])
# sentence_length = max(s1_length_max, s2_length_max)
'''
这里我对过长的句子做了截断,被我注释掉的代码是直接padding到最长的句子
:param s1:
:param s2:
:return: padding过的句子
'''
sentence_length = 20
sentence_num = s1.shape[0]
s1_padding = np.zeros([sentence_num, sentence_length], dtype=int)
s2_padding = np.zeros([sentence_num, sentence_length], dtype=int)
for i, s in enumerate(s1):
if len(s) <=20:
s1_padding[i][:len(s)] = s
else:
s1_padding[i][:] = s[:20]
for i, s in enumerate(s2):
if len(s) <=20:
s2_padding[i][:len(s)] = s
else:
s2_padding[i][:] = s[:20]
print("句子填充完毕")
return s1_padding, s2_padding
def get_id(word):
##获取每个单词词典里面的id
if word in sr_word2id:
return sr_word2id[word]
else:
return sr_word2id['unk']
def seq2id(seq):
##获取整个句子的id序列
seq_split = word_cut(seq)
seq_id = list(map(get_id, seq_split))
return seq_id
def read_data_sets(train_dir):
s1 = []
s2 = []
label = []
for line in open(train_dir, encoding='utf-8'):
l = line.strip().split("¥")
if len(l) < 2:
continue
s1.append(l[0])
s2.append(l[1])
label.append(int(l[2]))
sample_num = len(label)
# 引入embedding矩阵和字典
label = [[0,1] if i == 1 else [1,0] for i in label]
global sr_word2id, word_embedding
sr_word2id, word_embedding = build_w2v_dic()
s1 = np.asarray(list(map(seq2id, s1)))
s2 = np.asarray(list(map(seq2id, s2)))
label = np.asarray(label)
#填充句子
s1, s2 = padding_sentence(s1, s2)
new_index = np.random.permutation(sample_num)
s1 = s1[new_index]
s2 = s2[new_index]
label = label[new_index]
return s1, s2, label
def build_w2v_dic():
# 从文件中读取 pre-trained 的 word2vec 文件,对应每个词的词向量
# word2vec第一行是这种格式
# 400000 50
# 其中400000代表共有四十万个词,每个词50维,中间为一个空格或者tab键
w2v_path = os.path.join(data_dir, 'Word2VecModel_small.vector')
vocab, word_embedding = loadWord2Vec(w2v_path)
sr_word2id = pd.Series(range(0, len(vocab)), index=vocab)
word_mean = np.mean(word_embedding[1:], axis=0)
word_embedding[0] = word_mean
return sr_word2id, word_embedding
if __name__ == '__main__':
s1, s2, label = read_data_sets(data_path)
s1_train = s1[:200000]
s2_train = s2[:200000]
label_train = label[:200000]
s1_test = s1[200000:]
s2_test = s2[200000:]
label_test = label[200000:]
_, embed = build_w2v_dic()
print("preprocess end")
model = build(embed)
model.compile(optimizer=optimizers.adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08),
loss=losses.categorical_crossentropy, metrics=['accuracy'])
print('Training ------------')
model.fit([s1_train,s2_train],label_train,epochs=5,batch_size=32)
print('\nTesting ------------')
loss, accuracy = model.evaluate([s1_test,s2_test],label_test)
print('\ntest loss: ', loss)
print('\ntest accuracy: ', accuracy)