本次竞赛主要是及基于西班牙语的短文本来判断句子是否相似,目的比较明确,虽然没有取得很好的成绩,得到第44/1027名,可惜离top20还有一段距离;但针对于个人而言,尝试了很多论文方法,感受颇多i,针对于个人而言,需要记录自己的方法总结,以便能够做出改进,和大家分享,有问题指正,讨论,qq号[email protected],代码将放在github中;
数据介绍,官方数据介绍如下:
数据说明
在本次竞赛中,训练数据集包含两种语言。我们将提供20,000个标注好的英语问句对作为源数据,同时我们也将提供1,400个标注好的西班牙语问句对,以及55,669个未标注的西班牙语问句。所有的标注结果都由语言和领域专家人工标注。与此同时,我们也提供了每种语言的翻译结果。
数据字段
● cikm_english_train: 英语问句对,匹配标注,及其西班牙语翻译。
格式为
英语问句1,西班牙语翻译1,英语问句2,西班牙语翻译2,匹配标注。
标注为1表示两个问句语义相同,0表示不同。
● cikm_spanish_train: 西班牙语问句对,匹配标注,及其英语翻译。
格式为
西班牙语问句1,英语翻译1,西班牙语问句2,英语翻译2,匹配标注。
标注为1表示两个问句语义相同,0表示不同。
● cikm_unlabel_spanish_train: 无标注西班牙语语料,及其英语翻译。
● cikm_test_a: 测试集,需要预测的西班牙语问句对。
不同字段以”\t”符号分隔。
对于数据处理非常重要,但是由于本人经验有限,提供的数据有很多并没有用到,例如没有被标注的数据55,669个这个数据有什么用,也没有引起足够的重视,对于数据处理部分,由于提供的数据较少,并且是不均衡数据,以下是我自己的尝试思路:
- 直接利用两个句子的共有词作为问题的相似度,这一简单的做法,是的得分当天排名29,目前排名53,说明,共有词特征对于语义表示有很大的作用,但这无法排除,否定词的存在,所以,要用有监督方法,对词语的权重进行调节,loss损失为0.85
- 我们利用gensim tfidf方法作为词语的权重,利用第一个方法的综合结果。效果更差,可能证明结合的方法不对;衍生方法,可以根据句子特征进行监督学习方法,目前找到的特征有 共有词,tfidf ,编辑距离Loss损失为0.95
- 本来认为lstm是最好的表现形式对于文本语义以及句子结构都能够有很好的表示,所以应该放在最后做处理,所以直接采用了cnn的思想来对语义相似度做处理,这里先把自己的图画出来,比较简单,如下图所示:
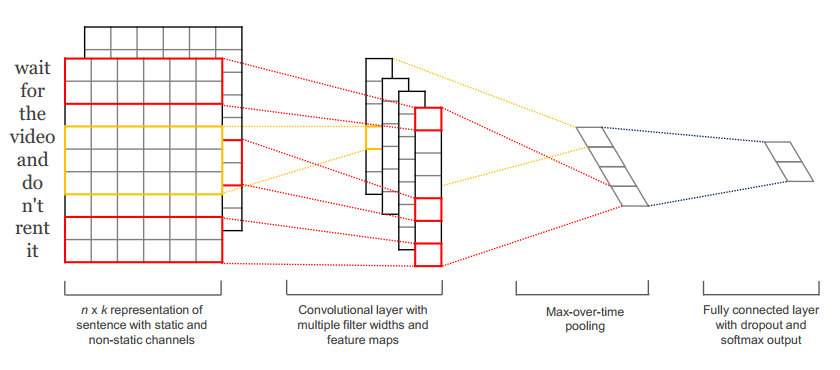
整个模型是按照两个句子的独立卷积操作进行的,1 利用竞赛所给的词向量分别对句子对feed进去,每一个句子形成一个矩阵形式,其中m,代表句子长度,n代表embedding的维度,设置的单词跨度为1,2,3,5,但是其实质1,2,3已经差不多可以代表所有短语的大小,通过卷积层以及max_pooling层,获取通过多个不同大小的核的输出,如图所示,每一个维度再求最大值,求最大值的维度要进行说明,max_pooling(x1,x2,...,xm),其中m代表句子长度对应的维度缩减,就是不同filter-size的获取的结果,可以理解为不同短语的一个维度的表示,求得就是不同维度最大短语特征作为整个句子的表示方法。但是不同于上图的方法,本次并没有采用full_connected_layers,因为发现在本次数据处理的基础上,加了这一层效果变得非常差。直接采用coss求两个句子独立的相似度;废话不多说直接从数据处理代码完整代码,然后一一解析,代码放在https://github.com/chenmingwei00/simple_cnn_cossin1.git中。
1。首先应该介绍的是主函数,也就是把模型与数据结合在一块运行的py文件,早这里是git中的cnn_version1.py文件,从头开始说明
初始化函数不多说,主要是对dropout-keep设置,batch_size设置,本次设置为10,原因很简单,虽然提供训练数据共有20000条左右,可是数据1和0标签比例为1:3,所以数据不平衡,而我对数据不平衡也看了很多方法,主要是smote方法以及欠采样方法,接下来会讨论数据不平衡的情况,总结采用欠采样在这里我的代码里效果最好,提取出10000条数据,所以batch-size设置为10效果最好,
num_epochs是迭代次数,每一次也就是batch_size训练,由于本次模型简单,数据较少,一般迭代次数在3000——————8000左右就会收敛,evaluate_every本次没有用到self.embedding_dim表示用到的词向量维度,这列提供词向量为300维度,self.num_filters=400表示卷积之后的map_feature输出的深度维度,self.filter_sizes表示跨越一个句子的宽度,也就是卷积核的window_size的大小self.get_data()其实就是数据准备,由于本次的词向量并没有发生变化,没有在训练时变化,就是准备数据;f = open('E:/tianchi_tran/my_cnn/competation_data/spanish_vec.pkl', 'rb')
self.words_vec = pickle.load(f)
这两句是自己处理得到的西班牙词语对应的词向量字典
class cnn_version1():
def __init__(self):
self.dropout_keep_prob=1.0
self.batch_size=10
self.num_epochs=500000
self.evaluate_every=3000
self.checkpoint_every=3000
self.embedding_dim=300
self.num_filters=400
self.filter_sizes="1,2,3,5"
self.l2_reg_lambda=0.05
self.allow_soft_placement=True
self.log_device_placement=False
self.get_data()
f = open('E:/tianchi_tran/my_cnn/competation_data/spanish_vec.pkl', 'rb')
self.words_vec = pickle.load(f)
self.model=InsQACNN(
sequence_length=70, # in this it is 263 每一个句子长度,本文是按照最大句子长度设定的句子向量长度,是否恰当 有待商榷
batch_size=self.batch_size,
vocab_size=len(self.vocab),
embedding_size=self.embedding_dim,
filter_sizes=list(map(int, self.filter_sizes.split(","))),
num_filters=self.num_filters,
l2_reg_lambda=self.l2_reg_lambda
)
#这个就是准备训练数据,此时的方法并没有使用验证数据进行训练指导
def get_data(self):
返回的其实就是,处理过后的词语数据
self.vocab,self.train_y,self.train_x_1,self.train_x_2 = insurance_qa_data_helpers.build_vocab()
self.test_x1,self.test_x2=insurance_qa_data_helpers.build_vocab_test()一下为训练函数,其实整个模型比较简单,我就大概对函数的主要句子进行解释
def train(self):
# 获取输入输出
session_conf = tf.ConfigProto(
allow_soft_placement=self.allow_soft_placement,
log_device_placement=self.log_device_placement)
sess = tf.Session(config=session_conf)
sess.run(tf.global_variables_initializer()) #对所有变量初始化
with sess.as_default():
saver,checkpoint_prefix,train_summary_writer=self.summary_fun(sess=sess)
for i in range(self.num_epochs):#开始迭代
try:
start = time.time()
#以下函数是随机选择batch-size=10的训练数据集,并且把词语向量根据self.wprd_vec生成数值向量,
self.x_train_1的shape=[10,70,300],为什么又要返回self.words_vec因为在词向量中有时候找不到,就随机初始化一个词向量,在下次遇到这些词语,就用之前随机初始化的词语
self.x_train_1, self.x_train_2, self.y_train_3 ,self.words_vec= insurance_qa_data_helpers.load_data_temp(self.words_vec,self.train_x_1,self.train_x_2,self.train_y, self.batch_size)
#以下过程是为了与模型文件的维度保持一致所做的操作
self.x_train_1=np.array([self.x_train_1])
self.x_train_1=self.x_train_1.reshape(self.x_train_1.shape[1],self.x_train_1.shape[2],self.x_train_1.shape[3],1)
self.x_train_2 = np.array([self.x_train_2])
self.x_train_2 = self.x_train_2.reshape(self.x_train_2.shape[1], self.x_train_2.shape[2],
self.x_train_2.shape[3], 1)
self.y_train_3=self.y_train_3.astype(float)
# print(self.x_train_1.shape)
# print(self.train_y.shape)
#把处理好的数据,这时的数据已经feed_dict成词向量矩阵,但是把句子成化成固定的70长度是不科学的,因为本次用到的max_pooling
#操作所以只需要把batch_size寻找固定的最大值padding就可以了,但是竞赛已经结束,而且是看到论文
#convolution for sentence classfilter
self.train_step(self.x_train_1, self.x_train_2, self.y_train_3, sess=sess,train_summary_writer=train_summary_writer)#
end = time.time()
current_step = tf.train.global_step(sess, self.model.global_step)
#每迭代self.checkpoint_every保存模型
if current_step % self.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))
except Exception as e:
print(e)
break接下来最重要的就是要分析的函数是
self.train_step(self.x_train_1,self.x_train_2,self.y_train_3,sess=sess,train_summary_writer=train_summary_writer)#
从下面看这个函数也比较简单,主要是把处理好的数据形成字典与模型图一一对应
def train_step(self,x_batch_1, x_batch_2, y_batch_3,sess,train_summary_writer):#)
"""
A single training step
"""
feed_dict = {
self.model.input_x_1: x_batch_1, #在这里是实际数据
self.model.input_x_2: x_batch_2,
self.model.input_y_3: y_batch_3,
self.model.dropout_keep_prob: self.dropout_keep_prob
}
output1,output2=sess.run([self.model.pooled_flat_1,self.model.pooled_flat_2],feed_dict)
print(np.array(output1).shape)
print(np.array(output1))
_, step, summaries, loss, accuracy = sess.run(
[self.model.train_op, self.model.global_step, self.model.train_summary_op, self.model.loss, self.model.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
if step%100==0:
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)以上函数也没什么可讲的,一看就非常容易懂。