class sklearn.cluster.DBSCAN()
参数:
eps:-邻域阈值,样本距离超过ϵ的样本点不在ϵ-邻域内。
min_samples:The number of samples (or total weight) in a neighborhood for a point to be considered as a core point. This includes the point itself.样本点要成为核心对象所需要的ϵ-邻域的样本数阈值。
metric:最近邻距离度量参数。可取值如下:

algorithm:最近邻搜索算法参数,{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, optional
leaf_size:最近邻搜索算法参数,为使用KD树或者球树时, 停止建子树的叶子节点数量的阈值。
p:最近邻距离度量参数。只用于闵可夫斯基距离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离, p=2为欧式距离。如果使用默认的欧式距离不需要管这个参数
参数:eps,min_samples两个参数对聚类效果有很大的影响,主要进行调参找到适合的值得到好的聚类结果。
属性:
core_sample_indices_:核心点集合
shape = [n_core_samples]
components_:Copy of each core sample found by training.
shape = [n_core_samples, n_features]
labels_:Cluster labels for each point in the dataset given to fit(). Noisy samples are given the label -1.
shape = [n_samples]
实例
# 基于密度的聚类算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X1,y1=datasets.make_circles(n_samples=5000,factor=.6,noise=.05)
X2,y2=datasets.make_blobs(n_samples=1000,n_features=2,centers=[[1.2,1.2]],cluster_std=[[.1]],random_state=9)
X=np.concatenate((X1,X2))
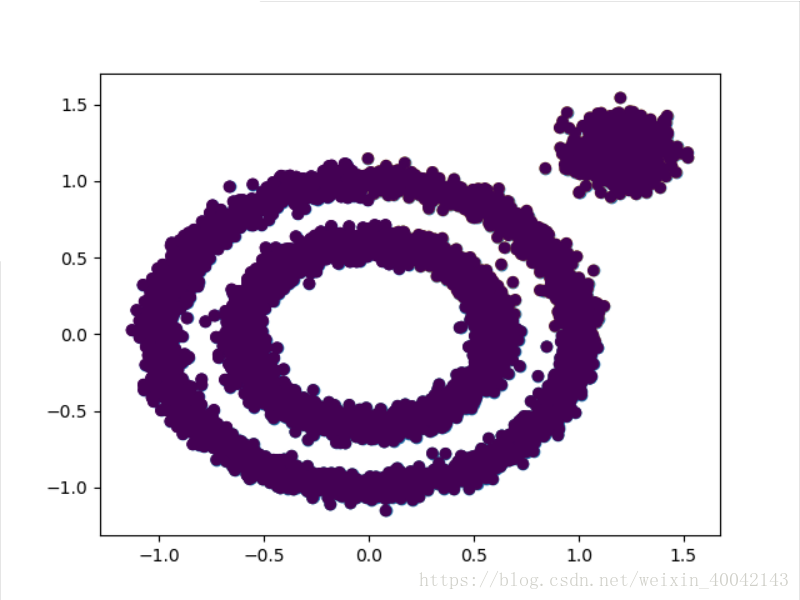
plt.scatter(X[:,0],X[:,1],marker='o')
#k-means聚类
from sklearn.cluster import KMeans
y_pre=KMeans(n_clusters=3,random_state=9).fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pre)
#DBSCAN聚类--默认参数
from sklearn.cluster import DBSCAN
y_p=DBSCAN(eps=0.1,min_samples=10).fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_p)
plt.show()样本的散点图:

k-means聚类效果:

DBSCAN聚类(默认参数)
DBSCAN进行调参,
eps默认为0.5,eps=0.05
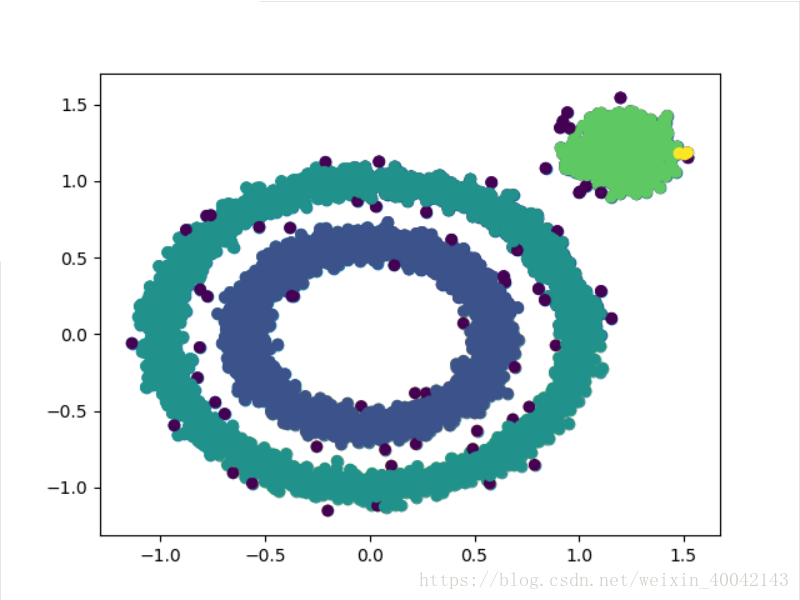
eps=0.1,min_sample=10

参考文献:
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html#sklearn.cluster.DBSCAN,