前言
在机器学习中,聚类是一种常见的无监督学习方法,它的目标是将数据集中的数据点分成不同的组,每个组之间具有相似的特征。聚类可以用于各种应用程序,如图像分割,社交媒体分析,医疗数据分析等。DBSCAN是一种聚类算法,它被广泛应用于各种领域。
一、DBSCAN算法原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它的原理是基于数据点周围的密度来确定聚类。在DBSCAN中,密度高的区域被认为是聚类,而密度低的区域则被认为是噪声。
DBSCAN的算法流程如下:
- 选择一个数据点作为起点,然后查找与该点距离在指定范围内的所有数据点。
- 如果距离在指定范围内的数据点数量大于或等于指定的阈值,则将这些数据点标记为核心点。
- 对于所有核心点,将与其距离在指定范围内的所有数据点归为同一个簇中。如果两个核心点之间存在重叠的数据点,则将它们归为同一簇中。
- 对于所有非核心点,将它们标记为噪声点。
基本概念:
- 密度相连:若从某核心点p出发,点q和点k都是密度可达的,则称点q和点k是密度相连的。
- 边界点:属于某一个类的非核心点,不能发展下线了
- 直接密度可达:若某点p在点q的 r 邻域内,且q是核心点则p-q直接密度可达。
- 噪声点:不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达的
在DBSCAN中,有三个参数需要指定:
- eps:指定在距离范围内的最大距离。
- min_samples:指定一个点周围的最小数据点数量,用于确定核心点。
- metric:用于计算距离的度量方法,密度阈值
二、基础使用
- 导包
import matplotlib.pyplot as plt
import numpy as mp
from sklearn.datasets import make_circles
from sklearn.cluster import DBSCAN
make_circles是scikit-learn中的一个函数,用于生成一个随机的圆形数据集。该函数的参数包括n_samples,表示生成数据集中样本的数量;noise,表示在生成的数据中加入的高斯噪声的标准差;factor,表示内外圆之间的比例因子;random_state,表示生成数据的随机种子,用于确保多次生成的数据集一致。
make_circles函数会在二维平面上生成两个圆形状的簇,并将它们相互嵌套放置,以模拟实际中的非线性可分问题.
DBSCN()实例化参数介绍
- eps:表示两个样本之间的最大距离,超出此距离的样本将被视为离群点,默认值为0.5。
- min_samples:表示簇中的最小样本数,小于此数量的簇将被视为离群点,默认值为5。
- metric:表示用于计算距离的度量方法,默认为欧几里得距离(euclidean)。还可以选择曼哈顿距离(manhattan)、余弦距离(cosine)等。
- metric_params:表示度量方法的其他参数。
- algorithm:表示计算DBSCAN的算法,可以选择基于kd树的高效算法(‘kd_tree’)或基于球树的高效算法(‘ball_tree’),默认为自动选择。
- leaf_size:表示构建kd树或球树时的叶子大小,默认为30。
- p:表示用于闵可夫斯基距离计算的参数,p=1时为曼哈顿距离,p=2时为欧几里得距离,p>2时为L_p距离,默认为2。
-> n_jobs:表示用于计算的并行工作数量,默认为1。-1表示使用所有可用的CPU核心。
返回方法介绍
fit_predict(X):在训练模型的同时,返回聚类结果,即返回每个样本点所属的簇编号,如果是噪声点则返回-1。X为输入的数据。
- labels_:训练后,每个样本点所属的簇编号,如果是噪声点则为-1。
- core_sample_indices_:训练后,核心样本的索引。
- components_:训练后,核心样本的特征向量。
- eps_:训练后,最佳的eps值。
- min_samples_:训练后,最佳的min_samples值。
- get_params():获取当前模型的参数设置。
-数据集
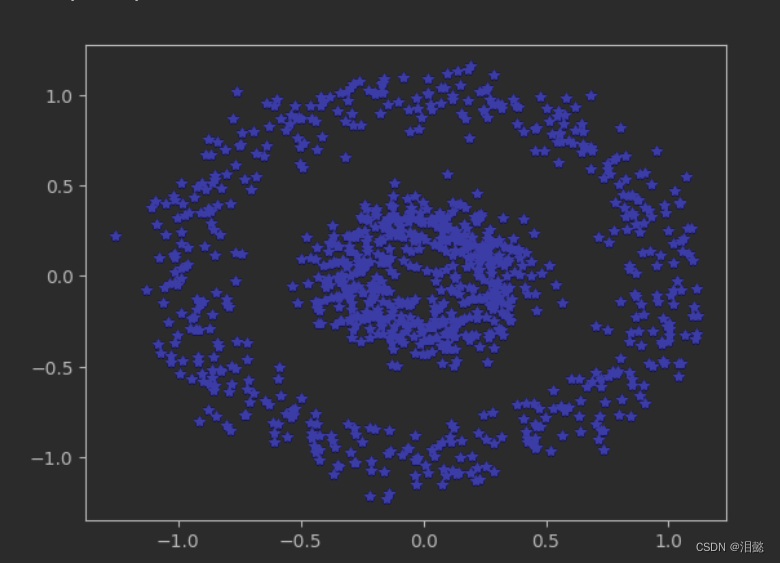
X,y=make_circles(factor=0.3,n_samples=1000,random_state=42,noise=0.1)
X
-我们可视化一下我们看到的数据
plt.plot(X[:,0],X[:,1],'b.',marker='*')
plt.show()
- 由于不同的eps对结果的影响不同,这里我们尝试多个eps进行训练
def plot_show(epe,modal):
core_mask=np.zeros_like(modal.labels_,dtype=bool)
#设置核心样本店
core_mask[modal.core_sample_indices_]=True
anoalie_mask=modal.labels_==-1
# 标记噪声点
non_core_mask=~(core_mask | anoalie_mask)
cores=modal.components_
anomalies=X[anoalie_mask]
non_cores=X[non_core_mask]
plt.scatter(cores[:,0],cores[:,1],c=modal
.labels_[core_mask],marker='o',cmap='Paired')
plt.scatter(cores[:, 0], cores[:, 1], marker='*', s=20, c=modal.labels_[core_mask])
plt.scatter(anomalies[:,0],anomalies[:,1],c='red',marker='X',s=70)
plt.scatter(non_cores[:,0],non_cores[:,1],c=modal.labels_[non_core_mask],marker='.')
plt.axis('off')
plt.title(f'epe:{
epe}')
for i,epe in enumerate(epes):
dbscan=DBSCAN(eps=epe,min_samples=5)
dbscan.fit(X)
plt.subplot(331+i)
plot_show(epe,dbscan)
plt.show()
 看到可以不同的epe值对于分类的结果还是很大,选择合适的epe尤为重要,图中中的X就是核心样本所在的位置
看到可以不同的epe值对于分类的结果还是很大,选择合适的epe尤为重要,图中中的X就是核心样本所在的位置
三、DBSCAN与Kmeans处理比较
DNSCAN在对任意形状非线性的簇处理很有优势,而Kmeans对却无法很好处理,我们实验观察
- 加载数据
from sklearn.datasets import make_moons
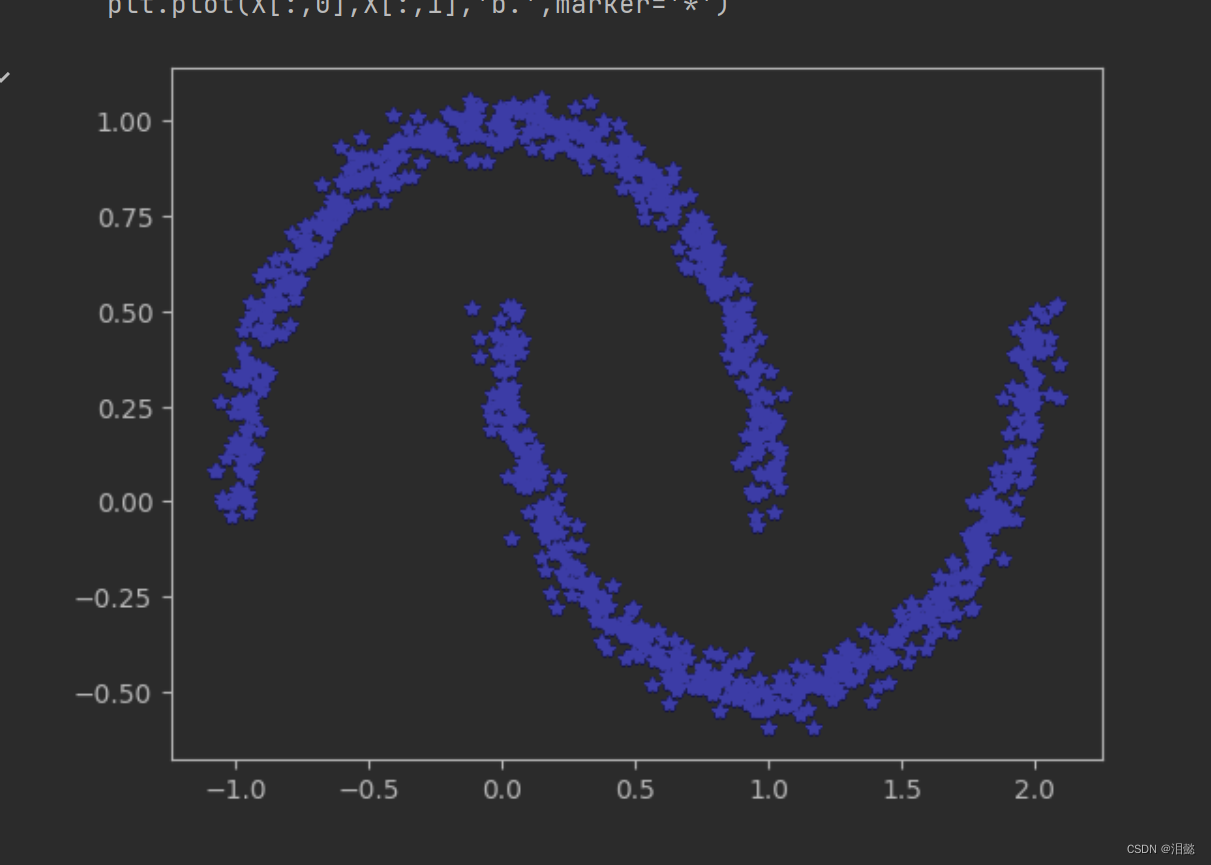
X,y=make_moons(n_samples=1000,noise=0.04,random_state=42)
#%% md
#%%
plt.plot(X[:,0],X[:,1],'b.',marker='*')
plt.show()
make_moons是scikit-learn中的一个函数,用于生成一个随机的月牙形数据集。该函数的参数包括n_samples,表示生成数据集中样本的数量;noise,表示在生成的数据中加入的高斯噪声的标准差;random_state,表示生成数据的随机种子,用于确保多次生成的数据集一致。
make_moons函数会在二维平面上生成两个半月形状的簇,并将它们相互交叉放置。
-比较两种分类方式
plt.subplot(121)
dbscan=DBSCAN(eps=0.1,min_samples=5)
dbscan.fit(X)
plt.scatter(X[:,0],X[:,1],c=dbscan.labels_)
plt.title('DBSCAN')
from sklearn.cluster import KMeans
plt.subplot(122)
kmeans=KMeans(n_clusters=2,random_state=42)
kmeans.fit(X)
plt.scatter(X[:,0],X[:,1],c=kmeans.labels_)
plt.title('KMEANS')
plt.show()
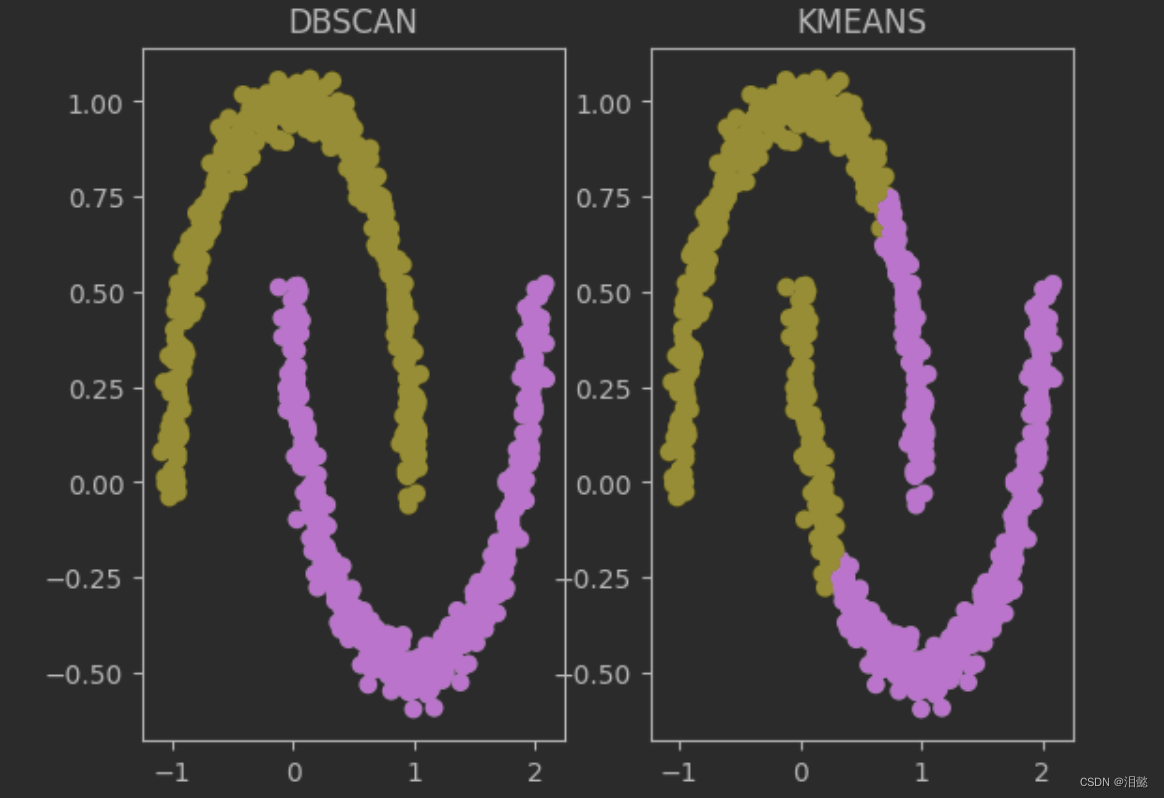
可见kmeans并没有达到我们的分类效果
总结
DBSCAN算法具有以下特点:
- 不需要事先设定簇的个数。
- 能够识别任意形状的簇。
- 能够识别噪声点。
- 对参数的设定比较敏感,但是通常只需要调整两个参数:半径 ϵ \epsilon ϵ和最小样本数 M i n P t s MinPts MinPts。
但是dbscan在图像切割中,发现一个问题,如果min_samples设置太小,会导致图像切割后没有明显变化,如果设置太大,有些密度较小的点就会被当噪声去掉,导致图像损失,与原来的shape不一致,目前还没有好的处理方法,后期如果有解决方法,第一时间分享。
由于本人能力有限,上述内容有任何错误,欢迎指正
==我会继续努力分享学习,希望大家多多支持